ctf里有几类题我是见到之后拔腿就跑,比如java和xss,对于后者,最近杂七杂八的学了很多js和前端的知识 没那么发怵了,而前者……不多说了,学学学!
本篇学习内容来自于廖雪峰Java教程,个人感觉比较适合对其它语言也有一点掌握的人
本机win10,为了兼容一些程序暂时有java8和11两个版;ide使用idea
Java基础
java程序结构
- src/xxx.java,类名为文件名,main为入口(idea直接输main会自动补全),idea格式化代码ctrl+shift+F
- 类class习惯大写字母开头,方法method习惯小写字母开头,必须带分号(不同于js可有可无)
classpath&jar
classpath是JVM的环境变量,是一组目录的集合(分隔符由系统定- 推荐在启动JVM时设置
classpath变量,不要污染系统环境(可以放心的交给idea
java -classpath .;C:\work\project1\bin;C:\shared abc.xyz.Hello
java -cp .;C:\work\project1\bin;C:\shared abc.xyz.Hello
不要把任何Java核心库添加到classpath中!默认的当前目录
.对于绝大多数情况都够用jar包实际上就是一个zip格式的压缩文件,包含
package组织的目录层级,以及各个目录下的所有文件(包括.class文件和其他文件),注意不含bin目录(注意层级)可以把jar理解为n多个class文件的容器,JVM自带的Java标准库rt.jar也是以jar形式进行存放
jar不关心class之间的依赖,如果漏掉的话在运行期极有可能抛出
ClassNotFoundException如果我们要执行一个jar包的
class,就可以把jar包放到classpath中
java -cp ./hello.jar abc.xyz.Hello
MANIFEST.MF文件可以提供jar包的信息,如Main-Class- 分析题目中给出jar包时我一般直接改zip解压,用idea打开整个目录作为项目(idea yyds
模块
- Java9后引入,解决依赖问题,控制jar之间的相互调用
- 把一堆class封装为jar仅仅是一个打包的过程,而把一堆class封装为模块则不但需要打包,还需要写入依赖关系,并且还可以包含二进制代码(通常是JNI扩展)
- 以java的标准库rt.jar为例,被拆为
java.base.jmod
java.compiler.jmod
java.datatransfer.jmod
java.desktop.jmod
...
以.jmod为拓展名标识,每个文件都是一个模块,模块java.base对应的文件就是java.base.jmod
- 模块之间的依赖关系已经被写入到模块内的
module-info.class文件了。所有的模块都直接或间接地依赖java.base模块,只有java.base模块不依赖任何模块,它可以被看作是根模块,好比所有的类都是从Object直接或间接继承而来
编写模块的部分暂略。
JavaBean
指的是符合某种规范的一种编程模式或编程思想(个人理解
部分Python爱好者也喜欢这么写,可拓展性强,就是很臃肿
- 写方法
setter,读方法getter,只有其中一种属性之一的被称为只写/读属性——满足这样规范的class被称为JavaBean
// 读方法:
public Type getXyz()
// 写方法:
public void setXyz(Type value)
- 要枚举一个JavaBean的所有属性,可以直接使用Java核心库提供的
Introspector
import java.beans.*;
public class Main {
public static void main(String[] args) throws Exception {
BeanInfo info = Introspector.getBeanInfo(Person.class); // 获取属性列表
for (PropertyDescriptor pd : info.getPropertyDescriptors()) {
System.out.println(pd.getName());
System.out.println(" " + pd.getReadMethod());
System.out.println(" " + pd.getWriteMethod());
}
}
}
class Person {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
语法基础
变量&数据类型
- 类似c的赋值风格:
类型 变量名 = 变量值(不同于go) - 程序设计的一个重要原则:数据的存储和显示要分离
- 执行
int x = n这样的变量赋值时,相当于两步操作,x与n是不同的存储单元 - 基本类型有
byte,int,short,long,float,double,boolean,char(表示ascii或一个Unicode字符),不可赋值null - 引用类型为所有class和interface类型,可赋值为null表示空
- 使用对应的Wrapper Class包装类可以将基本类型视为引用类型(class),好处是可以使用大量的实用方法
public class Main {
public static void main(String[] args) {
int i = 100;
// 通过new操作符创建Integer实例(不推荐使用,会有编译警告):
Integer n1 = new Integer(i);
// 通过静态方法valueOf(int)创建Integer实例:
Integer n2 = Integer.valueOf(i);
// 通过静态方法valueOf(String)创建Integer实例:
Integer n3 = Integer.valueOf("100");
System.out.println(n3.intValue());
}
}
- 每种基本类型都有其包装类型
| 基本类型 | 对应的引用类型 |
|---|---|
| boolean | java.lang.Boolean |
| byte | java.lang.Byte |
| short | java.lang.Short |
| int | java.lang.Integer |
| long | java.lang.Long |
| float | java.lang.Float |
| double | java.lang.Double |
| char | java.lang.Character |
- 所有的整数和浮点数的包装类型都继承自
Number,因此,可以非常方便地直接通过包装类型获取各种基本类型
// 向上转型为Number:
Number num = new Integer(999);
// 获取byte, int, long, float, double:
byte b = num.byteValue();
int n = num.intValue();
long ln = num.longValue();
float f = num.floatValue();
double d = num.doubleValue();
由于java中并不存在无符号整型这一说,全部都是有整型的,需要通过包装类型的静态方法来完成,比如
Byte.toUnsignedInt()int和对应的Integer可以互相转化,甚至直接使用
Integer n = 100; // 编译器自动使用Integer.valueOf(int)
int x = n; // 编译器自动使用Integer.intValue()
这种直接把int变为Integer的赋值写法,称为自动装箱(Auto Boxing);反过来,把Integer变为int的赋值写法,称为自动拆箱(Auto Unboxing)
注意:自动装箱和自动拆箱只发生在编译阶段,目的是为了少写代码。
装箱和拆箱会影响代码的执行效率,因为编译后的class代码是严格区分基本类型和引用类型的。并且,自动拆箱执行时可能会报NullPointerException(两种类型对null的容忍度不同
public class Main {
public static void main(String[] args) {
Integer n = null;
int i = n;
}
}
// NullPointerException
- 所有包装类型都是不变类,和String一样通过内部的
private final int字段实现,无法派生子类 - 判断值类型的变量是否相等可用
==,但是包装类型必须用equals比较(引用类型存在值相等但指向不同对象的情况)!!!详细的演示
public class Main {
public static void main(String[] args) {
Integer x = 127;
Integer y = 127;
Integer m = 99999;
Integer n = 99999;
System.out.println("x == y: " + (x==y)); // true
System.out.println("m == n: " + (m==n)); // false
System.out.println("x.equals(y): " + x.equals(y)); // true
System.out.println("m.equals(n): " + m.equals(n)); // true
}
}
==比较,较小的两个相同的Integer返回true,较大的两个相同的Integer返回false,这是因为Integer是不变类,编译器把Integer x = 127;自动变为Integer x = Integer.valueOf(127);
为了节省内存,Integer.valueOf()对于较小的数,始终返回相同的实例,因此==比较“恰好”为true,但我们绝不能因为Java标准库的Integer内部有缓存优化就用==比较,必须用equals()方法比较两个Integer
- 因为
Integer.valueOf()可能始终返回同一个Integer实例,因此,在我们自己创建Integer的时候,以下两种方法:
Integer n = new Integer(100);
Integer n = Integer.valueOf(100);
方法二更好,不用每次都new新的实例而是直接使用静态工厂方法进行调用,它会做到内部优化,尽可能地返回缓存的实例以节省内存
String作引用类型,类似c中的指针,内部存储一个指向内存中的地址- 加上
final表示常量,创建实例后无法修改 - 类型名过长时可用
var代替 instanceof()确定类型
运算
- 溢出不报错,注意自检
- 优先级太多记不住,统一加括号完事了
- 两种类型不同的数进行运算时会存在类型的隐式转换(short+int -> int+int),注意运算精度
- 整数运算很准确,没有必要为了节省内存而使用
byte和short进行整数运算 - 整数运算在除数为
0时会报错,而浮点数运算在除数为0时,不会报错,返回NANorInfinityor-Infinity - 布尔关系和三元运算中注意逻辑短路
- 三元运算
b ? x : y后面的类型必须相同
字符&字符串
- Java的
String和char在内存中总是以Unicode编码表示 - 字符char用
'',字符串用""(空字符串不等于null),字符串拼接存在类型隐式转换,""" """写多行字符串(同py) - java中的字符串赋值操作可直接联想c的指针进行理解,通过内部的
private final char[]字段 以及没有任何修改char[]的方法实现字符串的不可变性;基于这一点,如果传入的对象有可能改变,我们需要复制而不是直接引用 - 字符串比较必须用
equals()或equalsIgnoreCase(),不可偷懒用==
更多字符串的用法可几乎等同于Python,不列举
String和char[]类型可以互相转换
char[] cs = "Hello".toCharArray(); // String -> char[]
String s = new String(cs); // char[] -> String
- 如果修改了
char[]数组,String并不会改变
public class Main {
public static void main(String[] args) {
char[] cs = "Hello".toCharArray();
String s = new String(cs);
System.out.println(s);
cs[0] = 'X';
System.out.println(s);
}
}
这是因为通过new String(char[])创建新的String实例时,它并不会直接引用传入的char[]数组,而是会复制一份,所以,修改外部的char[]数组不会影响String实例内部的char[]数组,因为这是两个不同的数组
- 早期的String总以char[]进行存储
public final class String {
private final char[] value;
private final int offset;
private final int count;
}
而较新的JDK版本的String则以byte[]存储:如果String仅包含ASCII字符,则每个byte存储一个字符,否则,每两个byte存储一个字符,这样做的目的是为了节省内存,因为大量的长度较短的String通常仅包含ASCII字符
public final class String {
private final byte[] value;
private final byte coder; // 0 = LATIN1, 1 = UTF16
对于使用者来说,String内部的优化不影响任何已有代码,因为它的public方法签名是不变的
数组
- 新建数组
int[] n = new int[5];,大小不可变,为引用类型 - 对于数组元素(或所有可迭代的数据类型)的遍历直接使用
for(int n:na){},缺点是无法指定遍历顺序,无法获取数组索引(n直接代表元素) - 快速打印数组内容
System.out.println(Arrays.toString(ns)); - 快速打印二维数组内容
System.out.println(Arrays.deepToString(ns)); - 可变参数用
类型...定义,可变参数相当于数组类型
流程控制
- 读取输入需要
import java.util.Scanner,由Scanner对象进行读入操作
import java.util.Scanner;
public class hello {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
System.out.print("Input your name: ");
String name = scanner.nextLine();
System.out.print("Input your age: ");
int age = scanner.nextInt();
System.out.printf("Hi, %s, you are %d\n", name, age);
}
}
- switch语句不要忘break,case不用花括号
default语句,可以在漏写某个枚举常量时自动报错,从而及时发现错误
OOP基础
类&实例
- 对象靠new
- 一个java源文件可以包含多个类的定义,但只能定义一个public类,且public类名必须与文件名一致;如果要定义多个public类,必须拆到多个Java源文件中
方法
- 语法
修饰符 方法返回类型 方法名(方法参数列表) {
若干方法语句;
return 方法返回值;
}
// 无return 返回类型为void
- 变量设为private后可以通过public对外的方法间接修改
- 没事儿就尽可能少用public,少暴露对外的方法
- 与类名相同的方法作为construct构造方法,无返回值
- 先初始化字段,再执行构造方法(可覆盖前面的
- 可定义多个构造方法(传入参数类型 数量不同),new时会自动匹配;一个构造方法可以调用其他构造方法(便于代码复用),语法
class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public Person(String name) {
this(name, 18); // 调用另一个构造方法Person(String, int)
}
public Person() {
this("Unnamed"); // 调用另一个构造方法Person(String)
}
}
- 非构造方法也可有多个重名的(参数不同 返回值通常相同),称为方法重载(Overload),便于用一个名字处理多种参数输入
继承&多态
- 使用
extends关键字,例class Student extends Person - subclass == extended class; super class == parent class == base class
- 子类不可访问父类的
private字段和方法,不能覆写父类带有final关键字的方法,不能继承带有final的类,不能重新赋值带有final的字段 private访问权限被限定在class的内部,而且与方法声明顺序无关;如果一个类内部还定义了nested class嵌套类,那么,嵌套类拥有访问private的权限- 定义为
protected的字段和方法可以被子类访问,以及子类的子类 - 继承之后
super.name,this.name,name都是一个意思,但如果存在方法覆写后调用父类方法就必须用super.name(联想NodeJS的.call,.apply异曲同工之妙) - 未注明
extends xxx的类自动被补上了extends Object,最顶层的object也是可以被覆写的 - 任何类的构造方法中第一行语句必须是调用父类的构造方法,如未注明会自动补上
super();,所以如果父类没有默认的构造方法,子类就必须显式调用super()并给出参数以便让编译器定位到父类的一个合适的构造方法————一句话:子类不继承父类的构造方法,是自动生成的(联想Nodejs执行代码时的wrapper) - Java15之后允许
sealed修饰class,并可通过permits限制能从该类继承的子类名称(目前为预览状态,可开启--enable-preview和--source 15开启)
public sealed class Shape permits Rect, Circle, Triangle {
// xxx
}
- 向上转型基本无问题,向下可能回报ClassCastException的错误,用
instanceof判断一个实例究竟是不是某种类型 - 子类与父类方法签名完全相同时可覆写(Override),加上
@Override可以让编译器帮助检查是否进行了正确的覆写(非必要) - new来的对象如果指定的类型不同,实际调用其方法时会不同,run起来才知道具体用的啥,这个叫多态(Polymorphic),有助于实现功能拓展,封装底层逻辑 优化交互
抽象类&接口
- 抽象类不实现任何功能 仅为了定义方法签名,目的就是为了让子类继承并覆盖,注意这个类本身也要声明为
abstract作抽象类
abstract class Person {
public abstract void run(); // 无子句
}
- 当我们定义了一个抽象类和N个具体类,我们可以用抽象类作引用类型去引用具体类的子类实例,好处在于对实例的方法进行调用时并不关心抽象类型变量的具体子类型
Person s = new Student();
Person t = new Teacher();
// 不关心Person变量的具体子类型:
s.run();
t.run();
// 同样不关心新的子类是如何实现run()方法的:
Person e = new Employee();
e.run();
这种尽量引用高层类型,避免引用实际子类型的方式,称之为面向抽象编程,本质:
上层代码只定义规范(abstract class Person),不需要子类就可以实现业务逻辑(正常编译),具体的业务逻辑由不同的子类实现,调用者并不关心
interface比抽象类还抽象的纯抽象接口,无实例字段,所有方法都默认public abstract
interface Person {
void run();
String getName();
}
- 当具体类实现一个接口时需要用
implements
class Student implements Person {
private String name;
public Student(String name) {
this.name = name;
}
@Override
public void run() {
System.out.println(this.name + " run");
}
@Override
public String getName() {
return this.name;
}
}
- 一个类可以实现多个接口,一个接口也可以继承自另一个接口
class Student implements Person, Hello { // 实现了两个interface
...
}
interface Person extends Hello { // 继承另一个接口
void run();
String getName();
}
- 在接口中,可以定义
default方法;default方法和抽象类的普通方法是有所不同的。因为interface没有字段,default方法无法访问字段,而抽象类的普通方法可以访问实例字段(Java>=1.8)
静态字段&静态方法
用
static关键字修饰的字段处于同一个共享作用域中不推荐用
实例.静态字段去访问静态字段,因为在java中实例对象并没有静态字段(实际),代码中可以访问是因为编译器可以根据实例类型自动转换为类名.静态字段来访问推荐用类名来访问静态字段,可以将其理解为类本身的字段
调用实例方法必须通过一个实例变量,而调用静态方法则不需要实例变量,通过类名就可以调用
public class Main {
public static void main(String[] args) {
Person.setNumber(99);
System.out.println(Person.number);
}
}
class Person {
public static int number;
public static void setNumber(int value) {
number = value;
}
}
- 静态方法内部无法访问
this,也无法访问实例字段,只能访问静态字段 - 静态方法常用于工具类,比如
Arrays.sort()和Math.random();java程序入口的main也是静态方法噢 - 对于接口而言虽然不能有实例字段,但是可以有
public static final加持的静态字段
public interface Person {
public static final int MALE = 1;
public static final int FEMALE = 2;
}
// 可简写
public interface Person {
// 编译器会自动加上public statc final:
int MALE = 1;
int FEMALE = 2;
}
包
- 使用package包来解决名字冲突(各个语言都有了 很好懂),可以用类的全名
- 包没有父子关系!java.util和java.util.zip是不同的包,两者没有任何继承关系
- 所有Java文件对应的目录层次要和包的层次一致,编译后的
.class文件也需要按照包结构存放 - 位于同一个包的类,可以访问包作用域的字段和方法。不用
public、protected、private修饰的字段和方法就是包作用域 import static可以导入可以导入一个类的静态字段和静态方法- Java编译器最终编译出的
.class文件只使用完整类名(超长),所以编译器在遇到class名称时如果非完整类名,按照 当前package->import的包->java.lang包 的顺序进行查找
// Main.java
package test;
import java.text.Format;
public class Main {
public static void main(String[] args) {
java.util.List list; // ok,使用完整类名 -> java.util.List
Format format = null; // ok,使用import的类 -> java.text.Format
String s = "hi"; // ok,使用java.lang包的String -> java.lang.String
System.out.println(s); // ok,使用java.lang包的System -> java.lang.System
MessageFormat mf = null; // 编译错误:无法找到MessageFormat: MessageFormat cannot be resolved to a type
}
}
- 编写class时,编译器自动帮我们
import java.lang.*(不包含java.lang.reflect这样的包)和import当前package的其它class - 把方法定义为
package权限有助于测试,因为测试类和被测试类只要位于同一个package,测试代码就可以访问被测试类的package权限方法
内部类
- 或称nested class嵌套类
- Inner Class定义在一个类的内部,它的实例不能单独存在
public class Main {
public static void main(String[] args) {
Outer outer = new Outer("Nested"); // 实例化一个Outer
Outer.Inner inner = outer.new Inner(); // 实例化一个Inner
inner.hello();
}
}
class Outer {
private String name;
Outer(String name) { // 调用Outer的构造方法来创建Inner实例
this.name = name;
}
class Inner {
void hello() {
System.out.println("Hello, " + Outer.this.name);
}
}
}
原因是Inner Class除了this指向自己以外还隐含地持有一个Outer Class实例,可以用Outer.this访问这个实例;所以,实例化一个Inner Class不能脱离Outer实例
Inner Class和普通Class相比,除了能引用Outer实例外,还有一个额外的特权:可以修改Outer Class的private字段;因为Inner Class的作用域在Outer Class内部,所以能访问Outer Class的private字段和方法
观察Java编译器编译后的.class文件可以发现,Outer类被编译为Outer.class,而Inner类被编译为Outer$Inner.class
- 还可以通过匿名类Anonymous Class来定义Inner Class,两者本质上相同
public class Main {
public static void main(String[] args) {
Outer outer = new Outer("Nested");
outer.asyncHello();
}
}
class Outer {
private String name;
Outer(String name) {
this.name = name;
}
void asyncHello() {
Runnable r = new Runnable() { //
@Override
public void run() {
System.out.println("Hello, " + Outer.this.name);
}
};
new Thread(r).start();
}
}
Runnabale本身是不能实例化的接口,这里实际定义了一个实现了Runnable接口的匿名类,并通过new实例化 之后转型为Runnable,过程很多但是实现起来代码很简洁;和Inner Class一样也可以访问Outer Class的private
- 匿名类在定义时必须实例化,最终会编译为
Outer$1.class
Runnable r = new Runnable(){
// 实现必要的抽象方法...
};
- 继承自普通类的匿名类,编译为
Main$1.class和Main$2.class两个匿名类文件
import java.util.HashMap;
public class Main {
public static void main(String[] args) {
HashMap<String, String> map1 = new HashMap<>();
HashMap<String, String> map2 = new HashMap<>() {}; // 匿名类!
HashMap<String, String> map3 = new HashMap<>() {
{
put("A", "1");
put("B", "2");
}
};
System.out.println(map3.get("A"));
}
}
- 静态内部类示例
public class Main {
public static void main(String[] args) {
Outer.StaticNested sn = new Outer.StaticNested();
sn.hello();
}
}
class Outer {
private static String NAME = "OUTER";
private String name;
Outer(String name) {
this.name = name;
}
static class StaticNested {
void hello() {
System.out.println("Hello, " + Outer.NAME);
}
}
}
用static修饰的内部类和Inner Class有很大的不同,它不再依附于Outer的实例,而是一个完全独立的类,因此无法引用Outer.this,但它仍然可以访问Outer的private静态字段和静态方法;如果把StaticNested移到Outer之外,就失去了访问private的权限
Java核心类(部分)
StringBuilder
- 是一个可变对象,可以预分配缓冲区,向其中新增字符时,不会创建新的临时对象
StringBuilder sb = new StringBuilder(1024);
for (int i = 0; i < 1000; i++) {
sb.append(',');
sb.append(i);
}
String s = sb.toString();
- 可链式操作
public class Main {
public static void main(String[] args) {
var sb = new StringBuilder(1024);
sb.append("Mr ")
.append("Bob")
.append("!")
.insert(0, "Hello, ");
System.out.println(sb.toString());
}
}
- 实现的关键是定义的
append()方法会返回this,这样就可以不断调用自身的其他方法;仿写链式调用函数
public class Main {
public static void main(String[] args) {
Adder adder = new Adder();
adder.add(3)
.add(5)
.inc()
.add(10);
System.out.println(adder.value());
}
}
class Adder {
private int sum = 0;
public Adder add(int n) {
sum += n;
return this;
}
public Adder inc() {
sum ++;
return this;
}
public int value() {
return sum;
}
}
StringBuffer和StringBuilder接口完全相同,是早期版本,通过同步来保证多个线程操作StringBuffer也是安全的,但是同步会带来执行速度的下降
enum
public class Main {
public static void main(String[] args) {
Weekday day = Weekday.SUN;
if (day == Weekday.SAT || day == Weekday.SUN) {
System.out.println("Work at home!");
} else {
System.out.println("Work at office!");
}
}
}
enum Weekday { // 只需依次列出枚举的常量名
SUN, MON, TUE, WED, THU, FRI, SAT;
}
enum常量本身带有类型信息,即Weekday.SUN类型是Weekday,编译器会自动检查出类型错误不可能引用到非枚举的值,因为无法通过编译
不同类型的枚举不能互相比较或者赋值,因为类型不符
enum虽然也是引用类型,但因为其在JVM中只有唯一实例,所以可以直接用==比较继承自
java.lang.Enum,无法被继承,无法new实例枚举类的字段也可以是非final类型,即可以在运行期修改,但是不推荐这样
天生适合switch,具有类型信息和有限个枚举常量
public class Main {
public static void main(String[] args) {
Weekday day = Weekday.SUN;
switch(day) {
case MON:
case TUE:
case WED:
case THU:
case FRI:
System.out.println("Today is " + day + ". Work at office!");
break;
case SAT:
case SUN:
System.out.println("Today is " + day + ". Work at home!");
break;
default:
throw new RuntimeException("cannot process " + day);
}
}
}
enum Weekday {
MON, TUE, WED, THU, FRI, SAT, SUN;
}
record
java14开始
- 不变类的class和字段都使用
final关键字,无法派生子类,创建实例后无法修改任何字段 - 创建不变类后为了保证不变类的比较,还需要正确覆写
equals()和hashCode()方法,手动覆写很麻烦,可以直接用record一行写出不变类
public final class Point {
private final int x;
private final int y;
public Point(int x, int y) {
this.x = x;
this.y = y;
}
public int x() {
return this.x;
}
public int y() {
return this.y;
}
}
public class Main {
public static void main(String[] args) {
Point p = new Point(123, 456);
System.out.println(p.x());
System.out.println(p.y());
System.out.println(p);
}
}
public record Point(int x, int y) {}
最后一行相当于
public final class Point extends Record {
private final int x;
private final int y;
public Point(int x, int y) {
this.x = x;
this.y = y;
}
public int x() {
return this.x;
}
public int y() {
return this.y;
}
public String toString() {
return String.format("Point[x=%s, y=%s]", x, y);
}
public boolean equals(Object o) {
...
}
public int hashCode() {
...
}
}
除了用final修饰class以及每个字段外,编译器还自动为我们创建了构造方法,和字段名同名的方法,以及覆写toString()、equals()和hashCode()方法
- 和
enum类似,我们自己不能直接从Record派生,只能通过record关键字由编译器实现继承 - 如果要对参数进行检查,可以用Compact Constructor
public record Point(int x, int y) {
public Point {
if (x < 0 || y < 0) {
throw new IllegalArgumentException();
}
}
}
编译器生成的方法
public final class Point extends Record {
public Point(int x, int y) {
// 这是我们编写的Compact Constructor:
if (x < 0 || y < 0) {
throw new IllegalArgumentException();
}
// 这是编译器继续生成的赋值代码:
this.x = x;
this.y = y;
}
...
}
- 作为
record的Point仍然可以通过of()添加静态方法
public record Point(int x, int y) {
public static Point of() {
return new Point(0, 0);
}
public static Point of(int x, int y) {
return new Point(x, y);
}
}
var z = Point.of();
var p = Point.of(123, 456);
异常处理
异常&捕获异常
- Java内置异常处理机制,是一种
class,本身带有类型信息;异常可以在任何地方抛出,但只需要在上层捕获,这样可以做到和方法调用分离
try {
String s = processFile(“C:\\test.txt”);
// ok:
} catch (FileNotFoundException e) {
// file not found:
} catch (SecurityException e) {
// no read permission:
} catch (IOException e) {
// io error:
} catch (Exception e) {
// other error:
}
- 继承关系是这样的
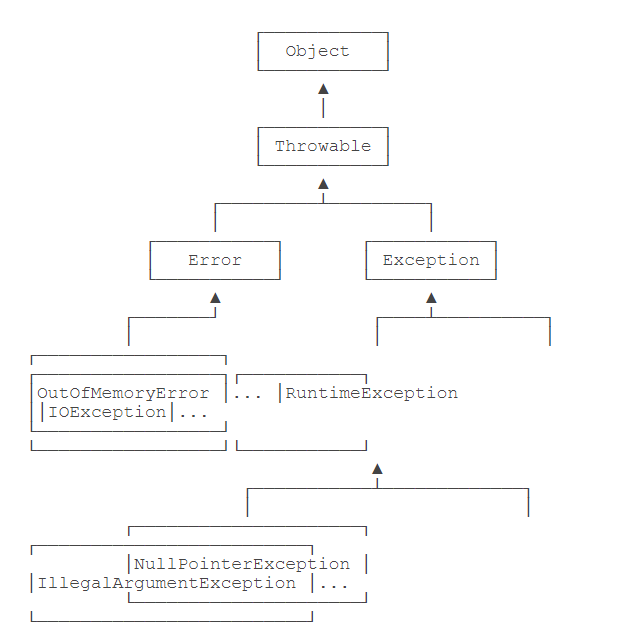
Throwable是异常体系的根,它继承自Object
Error表示严重错误,比如OutofMemoryError, NoClassDefFoundError, StackOverflowError
Exception表示运行时的异常,可以被捕获并处理,比如NumberFormatException, FileNotFoundException, SocketException;还包括一些可修正的语法错误,比如NullPointerException, IndexOutOfBoundsException
- 常用异常
Exception
│
├─ RuntimeException
│ │
│ ├─ NullPointerException
│ │
│ ├─ IndexOutOfBoundsException
│ │
│ ├─ SecurityException
│ │
│ └─ IllegalArgumentException
│ │
│ └─ NumberFormatException
│
├─ IOException
│ │
│ ├─ UnsupportedCharsetException
│ │
│ ├─ FileNotFoundException
│ │
│ └─ SocketException
│
├─ ParseException
│
├─ GeneralSecurityException
│
├─ SQLException
│
└─ TimeoutException
必须捕获的异常,包括
Exception及其子类,但不包括RuntimeException及其子类,这种类型的异常称为Checked Exception如果不捕获Checked Exception,编译器会报错,原因是方法定义时使用
throws Xxx表示该方法可能抛出的异常类型,导致调用方在调用的时候,必须强制捕获这些异常不需要捕获的异常,包括
Error及其子类,RuntimeException及其子类捕获异常需要提前import
import java.io.UnsupportedEncodingException;
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
try {
byte[] bs = toGBK("中文");
System.out.println(Arrays.toString(bs));
} catch (UnsupportedEncodingException e) {
System.out.println(e);
}
}
static byte[] toGBK(String s) throws UnsupportedEncodingException {
// 用指定编码转换String为byte[]:
return s.getBytes("GBK");
}
}
- 只要是方法声明的Checked Exception,不在调用层捕获,也必须在更高的调用层捕获;所有未捕获的异常,最终也必须在
main()方法中捕获 - 所有异常都可以调用
printStackTrace()方法打印异常栈
static byte[] toGBK(String s) {
try {
return s.getBytes("GBK");
} catch (UnsupportedEncodingException e) {
// 先记下来再说:
e.printStackTrace();
}
return null;
- 如果不想用try可以直接把
main()方法定义为throws Exception
import java.io.UnsupportedEncodingException;
import java.util.Arrays;
public class Main {
public static void main(String[] args) throws Exception {
byte[] bs = toGBK("中文");
System.out.println(Arrays.toString(bs));
}
static byte[] toGBK(String s) throws UnsupportedEncodingException {
// 用指定编码转换String为byte[]:
return s.getBytes("GBK");
}
}
相当于声明了所有可能抛出的Exception,也就不用捕获了;代价就是一旦发生异常,程序会立刻退出,不够灵活
- 当方法声明了可能抛出的异常,可以没有
catch,只使用try ... finally结构
void process(String file) throws IOException {
try {
...
} finally {
System.out.println("END");
}
}
- 可以一个try对多个catch,此时注意catch的顺序:子类在前,避免短路
public static void main(String[] args) {
try {
process1();
process2();
process3();
} catch (IOException e) {
System.out.println("IO error");
} catch (UnsupportedEncodingException e) { // 永远捕获不到 会被上面的截胡
System.out.println("Bad encoding");
}
}
抛出异常
- 分两步:创建某个
Exception的实例 -> 抛出
void process2(String s) {
if (s==null) {
throw new NullPointerException();
}
}
- 如果一个方法捕获了某个异常后,又在
catch子句中抛出新的异常,就相当于把抛出的异常类型“转换”了;注意为了能追踪到完整的异常栈,在构造异常的时候,把原始的Exception实例传进去
public class Main {
public static void main(String[] args) {
try {
process1(); // 01
} catch (Exception e) {
e.printStackTrace(); // 05
}
}
static void process1() {
try {
process2(); // 02
} catch (NullPointerException e) {
// throw new IllegalArgumentException();
throw new IllegalArgumentException(e); // 04
}
}
static void process2() {
throw new NullPointerException(); // 03
}
}
如果用注释掉的方式写就会丢失NullPointerException这一条
- 在代码中获取原始异常可以使用
Throwable.getCause()方法。如果返回null,说明已经是“根异常”了(Caused by: xxxx) - 如果在finally中抛出异常(尽量别),由于
catch中准备抛出的异常就“消失”了,所以这个没有被抛出的异常称为“被屏蔽”的异常Suppressed Exception - 如果我们需要获知所有的异常,可以先用
origin变量保存原始异常,然后调用Throwable.addSuppressed(),把原始异常添加进来,最后在finally抛出
public class Main {
public static void main(String[] args) throws Exception {
Exception origin = null;
try {
System.out.println(Integer.parseInt("abc"));
} catch (Exception e) {
origin = e;
throw e;
} finally {
Exception e = new IllegalArgumentException();
if (origin != null) {
e.addSuppressed(origin);
}
throw e;
}
}
}
当catch和finally都抛出了异常时,虽然catch的异常被屏蔽了,但是,finally抛出的异常仍然包含了它:
Exception in thread "main" java.lang.IllegalArgumentException
at Main.main(Main.java:11)
Suppressed: java.lang.NumberFormatException: For input string: "abc"
at java.base/java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
at java.base/java.lang.Integer.parseInt(Integer.java:652)
at java.base/java.lang.Integer.parseInt(Integer.java:770)
at Main.main(Main.java:6)
通过Throwable.getSuppressed()可以获取所有的Suppressed Exception
自定义异常
- 见的做法是自定义一个
BaseException作为“根异常”,然后,派生出各种业务类型的异常;BaseException需要从一个适合的Exception派生,通常建议从RuntimeException派生
public class BaseException extends RuntimeException {
}
public class UserNotFoundException extends BaseException {
}
public class LoginFailedException extends BaseException {
}
- 自定义的
BaseException应该提供多个构造方法
public class BaseException extends RuntimeException {
public BaseException() {
super();
}
public BaseException(String message, Throwable cause) {
super(message, cause);
}
public BaseException(String message) {
super(message);
}
public BaseException(Throwable cause) {
super(cause);
}
}
这样,抛出异常的时候,就可以选择合适的构造方法
断言
- JVM默认关闭断言指令,需传入
-enableassertions或-ea;还可以有选择地对特定地类启用断言,命令行参数是:-ea:com.itranswarp.sample.Main,表示只对com.itranswarp.sample.Main这个类启用断言;或者对特定地包启用断言,命令行参数是:-ea:com.itranswarp.sample...(注意结尾有3个.),表示对com.itranswarp.sample这个包启动断言 - 是一种调试方式,失败时会抛出
AssertionError,导致程序结束退出
public static void main(String[] args) {
double x = Math.abs(-123.45);
assert x >= 0 : "x must >= 0"; // 会带上消息
System.out.println(x);
}
- 不能用于可恢复的程序错误,只应该用于开发和测试阶段,对于可恢复的程序错误,不应该使用断言
void sort(int[] arr) {
assert arr != null;
}
应该直接捕获了
void sort(int[] arr) {
if (arr == null) {
throw new IllegalArgumentException("array cannot be null");
}
}
日志
为了取代System.out.println(),封装好了很多好用的方法
JDK Logging
标准库自带
import java.util.logging.Level;
import java.util.logging.Logger;
public class Hello {
public static void main(String[] args) {
Logger logger = Logger.getGlobal();
logger.info("start process...");
logger.warning("memory is running out...");
logger.fine("ignored.");
logger.severe("process will be terminated...");
}
}
- JDK的Logging定义了7个日志级别,从严重到普通
SEVERE, WARNING, INFO(default), CONFIG, FINE, FINER, FINEST
- 局限:配置不太方便,需要在JVM启动时传递参数
-Djava.util.logging.config.file=<config-file-name>,一旦开始运行main()方法,就无法修改配置
Commons Logging
第三方,由Apache创建,可以挂接不同的日志系统,并通过配置文件指定挂接的日志系统
可作为日志接口,而非日志实现
- 默认搜索Log4j,没有的话用JDK Logging
- 使用很简单
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
public class Main {
public static void main(String[] args) {
Log log = LogFactory.getLog(Main.class); // 获取实例
log.info("start..."); // 打印日志
log.warn("end.");
}
}
- 6个日志级别
FATAL, ERROR, WARNING, INFO(default), DEBUG, TRACE
- 除
info(String)外还有info(String, Throwable)这样一个重载方法,便于更简单地记录异常
try {
...
} catch (Exception e) {
log.error("got exception!", e);
}
- 如果在静态方法中引用
Log,通常直接定义一个静态类型变量:
// 在静态方法中引用Log:
public class Main {
static final Log log = LogFactory.getLog(Main.class);
static void foo() {
log.info("foo");
}
}
- 在实例方法中引用
Log,通常定义一个实例变量
// 在实例方法中引用Log:
public class Person {
protected final Log log = LogFactory.getLog(getClass());
void foo() {
log.info("foo");
}
}
- 上面展示了两种
getLog()的方式,第二种的好处是子类可以直接使用该实例,原因是Java的动态特性,子类获取的Log字段实际上相当于LogFactory.getLog(Student.class),但却是从父类继承而来,并且无需改动代码
Log4j
日志实现(乐)Log4j,我真的好喜欢你啊!为了你,我不要用无序列表了!!!
Log4j是一个组件化设计的日志系统,它的架构大致如下
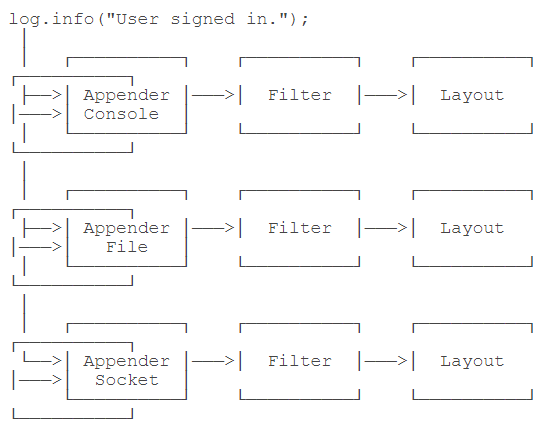
当我们使用Log4j输出一条日志时,Log4j自动通过不同的Appender把同一条日志输出到不同的目的地
- console:输出到屏幕;
- file:输出到文件;
- socket:通过网络输出到远程计算机;
- jdbc:输出到数据库
通过Filter来过滤哪些log需要被输出,最后,通过Layout来格式化日志信息
使用Log4j时只需把一个log4j2.xml的文件放到classpath下就可以让Log4j读取配置文件并按照我们的配置来输出日志
<?xml version="1.0" encoding="UTF-8"?>
<Configuration>
<Properties>
<!-- 定义日志格式 -->
<Property name="log.pattern">%d{MM-dd HH:mm:ss.SSS} [%t] %-5level %logger{36}%n%msg%n%n</Property>
<!-- 定义文件名变量 -->
<Property name="file.err.filename">log/err.log</Property>
<Property name="file.err.pattern">log/err.%i.log.gz</Property>
</Properties>
<!-- 定义Appender,即目的地 -->
<Appenders>
<!-- 定义输出到屏幕 -->
<Console name="console" target="SYSTEM_OUT">
<!-- 日志格式引用上面定义的log.pattern -->
<PatternLayout pattern="${log.pattern}" />
</Console>
<!-- 定义输出到文件,文件名引用上面定义的file.err.filename -->
<RollingFile name="err" bufferedIO="true" fileName="${file.err.filename}" filePattern="${file.err.pattern}">
<PatternLayout pattern="${log.pattern}" />
<Policies>
<!-- 根据文件大小自动切割日志 -->
<SizeBasedTriggeringPolicy size="1 MB" />
</Policies>
<!-- 保留最近10份 -->
<DefaultRolloverStrategy max="10" />
</RollingFile>
</Appenders>
<Loggers>
<Root level="info">
<!-- 对info级别的日志,输出到console -->
<AppenderRef ref="console" level="info" />
<!-- 对error级别的日志,输出到err,即上面定义的RollingFile -->
<AppenderRef ref="err" level="error" />
</Root>
</Loggers>
</Configuration>
SLF4J&Logback
类似上面那一对,做了些许改进
| Commons Logging | SLF4J |
|---|---|
| org.apache.commons.logging.Log | org.slf4j.Logger |
| org.apache.commons.logging.LogFactory | org.slf4j.LoggerFactory |
仍使用xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<encoder>
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
<charset>utf-8</charset>
</encoder>
<file>log/output.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.FixedWindowRollingPolicy">
<fileNamePattern>log/output.log.%i</fileNamePattern>
</rollingPolicy>
<triggeringPolicy class="ch.qos.logback.core.rolling.SizeBasedTriggeringPolicy">
<MaxFileSize>1MB</MaxFileSize>
</triggeringPolicy>
</appender>
<root level="INFO">
<appender-ref ref="CONSOLE" />
<appender-ref ref="FILE" />
</root>
</configuration>
学完基础语法的感觉是约等于同时复建了PHP+c+Python+NodeJS,虽说是速通,但是感觉触类旁通,很多东西都明白了(大概)
6小时速通基础,今天就可以学反射和其它的高级用法了!就可以跟链子了!!!
好耶!!!