其实已经学了一段时间了……但还有几个二级/三级标题没有学完,先放个上篇()
参考了很多师傅的博客,参考链接统一放在末尾w
如有错漏还烦请各位师傅指正……在此先提前磕一个了Orz
解析
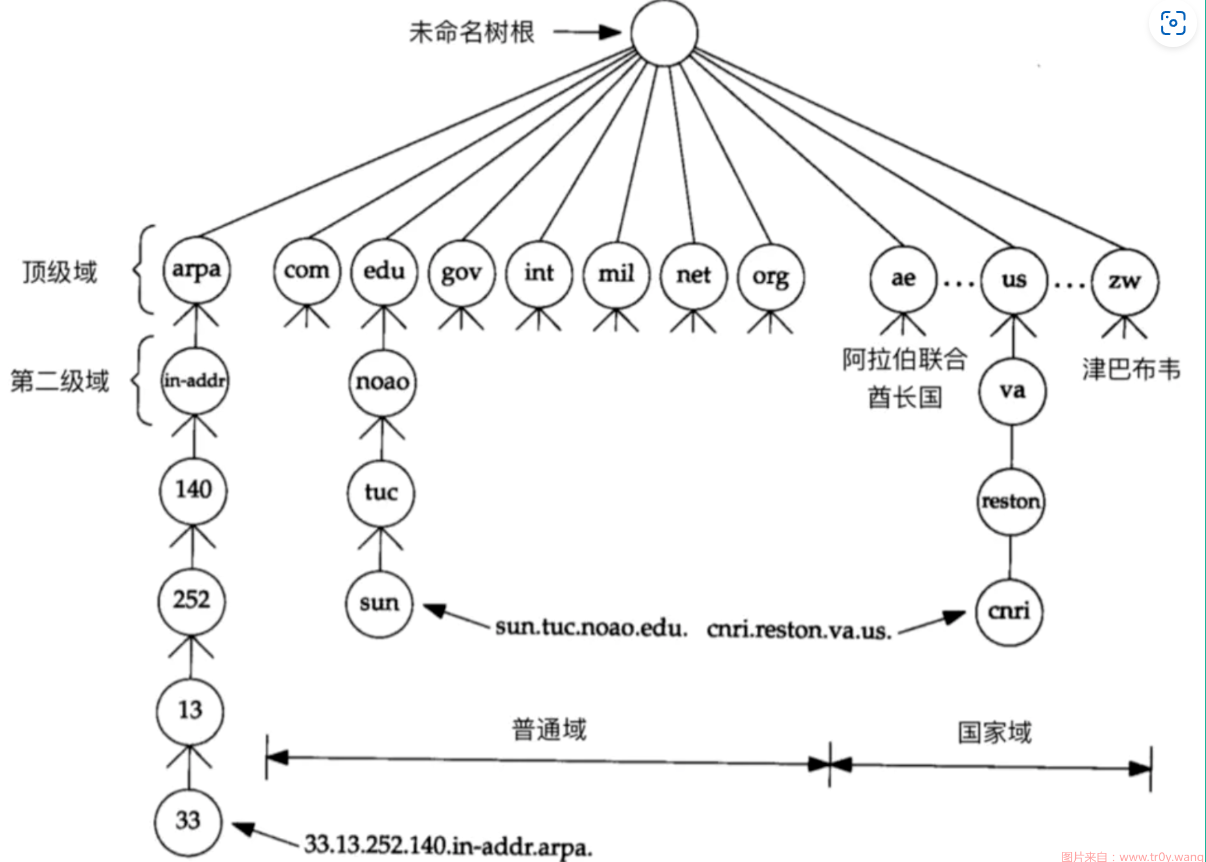
顶级域Top-Level Domains:
- generic Top-Level Domains: com, edu, net, ….
- country code Top-Level Domains: cn, us, ….
- effective Top-Level Doamins: github.io, ….
- arpa: 逆向解析域
一个完整的域名通常会具有二级及以上的域名形式,即二级域example.com或五级域a.b.c.example.com,通过DNS服务查询域名到ip时有这样两种方式:
- 递归查询:A-> B-> C,A向B发起解析的请求,B再向C发起请求,得到响应再给A;在此过程中A, B各发起一次DNS请求
- 迭代查询:A-> B, A-> C,A向B发起解析的请求,B告诉A去找C,A再向C发起请求;在此过程中A发起两次DNS请求
hosts
在进行DNS请求的过程中,首先会在本地的hosts文件里找,windows在C:\Windows\System32\drivers\etc\hosts,linux在/etc/hosts,格式为
# ip domain
127.0.0.1 localhost
LocalDNS
如果hosts中没有进入LocalDNS,即本地网络指定的DNS服务器
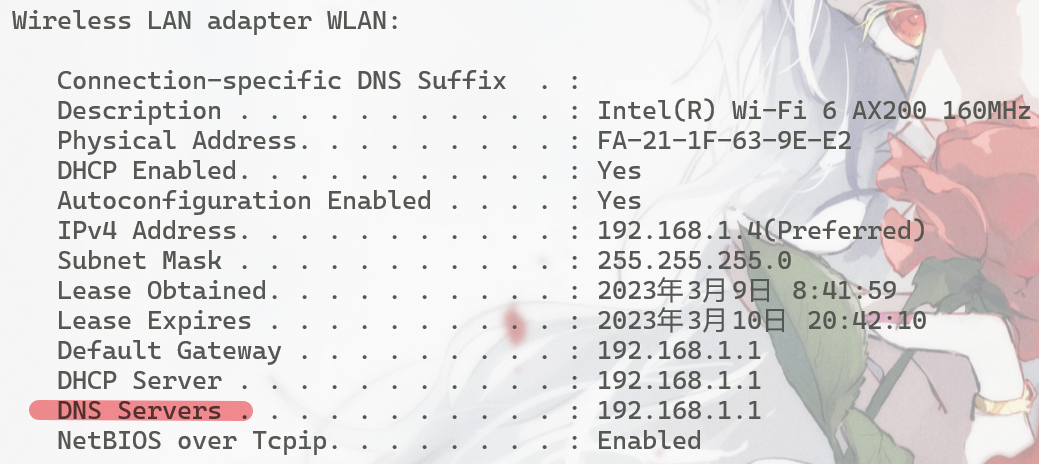
linux在/etc/resolv.conf中设置,想必虚拟机中配置过host-only模式的师傅一定很熟悉这个文件,它的格式是
# nameserver ip
nameserver 192.168.1.1
LocalDNS其实并不具备真正的域名解析功能,而是缓存域名的查询记录,同时作为向外迭代查询的第一环
当我们用nslookup查询时经常会出现Non-authoritative answer,这就是因为此时返回的记录是从LocalDNS的缓存里拿的;windows dns默认开启dns缓存,常用命令
ipconfig /displaydns
ipconfig /flushdns
*至于为什么仅主机网络模式要配置resolv.conf?这是因为在这种情况下虚拟机和主机会在同一子网内(有独立的DHCP服务器来分配ip),我们希望虚拟机可以访问外网 就要手动指定它的nameserver(理论上这一过程也是自动的,但实际中VirtualBox无法直接修改resolve.conf,所以总需要先route add default gw ip,再设置nameserver才可以,如果长时间开机有概率导致route失效,需要再次route add)
根服务器
全球有13“台”根服务器(实际有多个服务器进行负载均衡啦),当DNS请求发来时实际会发向它的一个任播节点,再根据顶级域名向LocalDNS返回接下来要找的DNS顶级域名服务器的ip,向他发起查询
当我们直接dig . ns可以得到那.的13条NS记录(即13个服务器),但显然.没有A记录
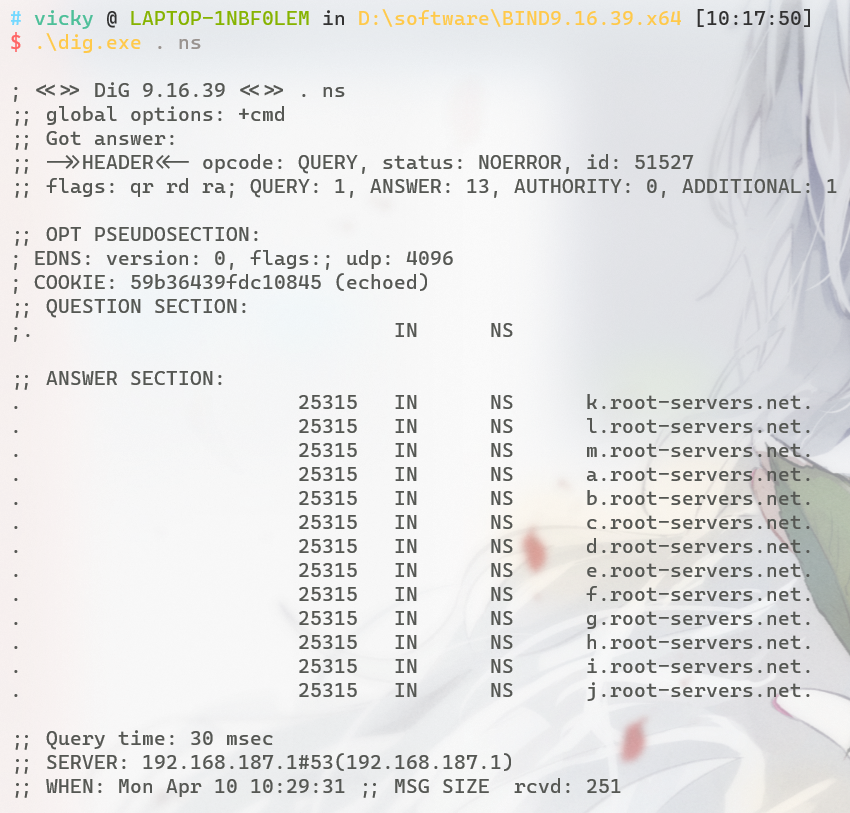
顶级域名服务器
顶级域名服务器手握*.com的解释权,但现在基本是授权给其它厂商来做,比如万网等DNS权威域名服务器,这类域名服务器会掌控特定域下的所有子域和主机的ip,所以它可以直接返回结果
域名授权的DNS权威域名服务器的信息在AUTHORITY SECTION部分中返回,告诉localDNS到这里去查
解析失败的多种原因
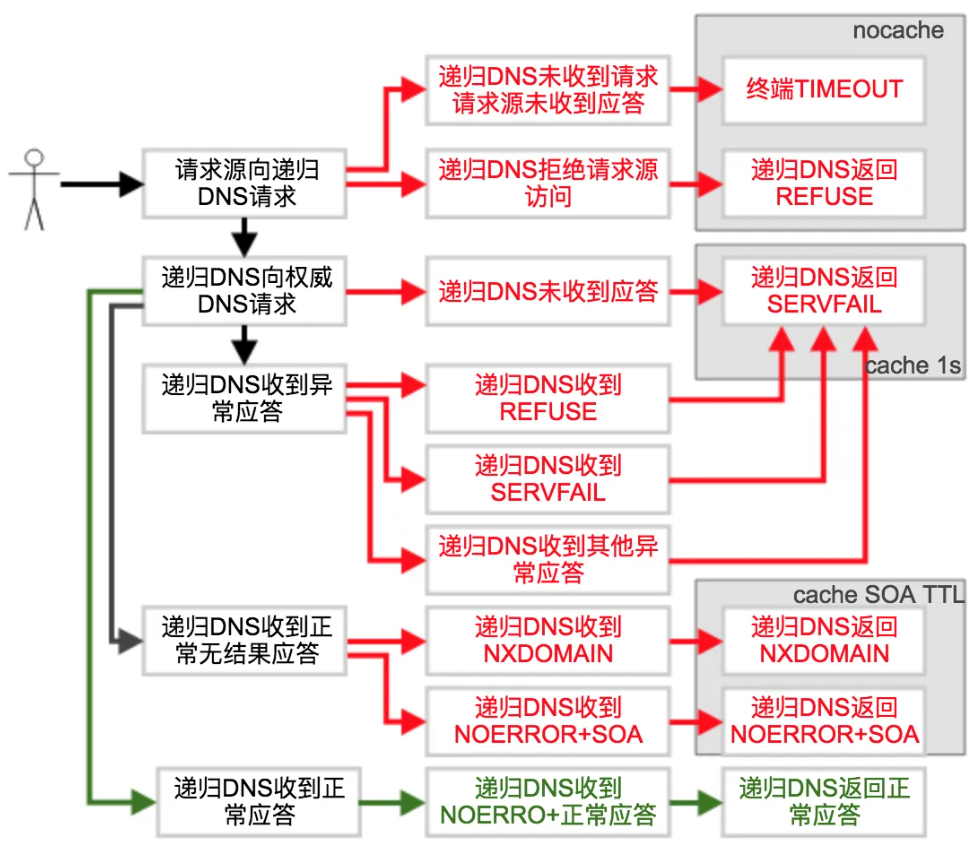
这里要引入DNS-Rcode这一字段,它在DNS响应报文中用于说明DNS应答状态,我们可以根据它来大致判断是什么原因导致域名无法被正确解析;常见的Rcode值和对应情况有如下这些
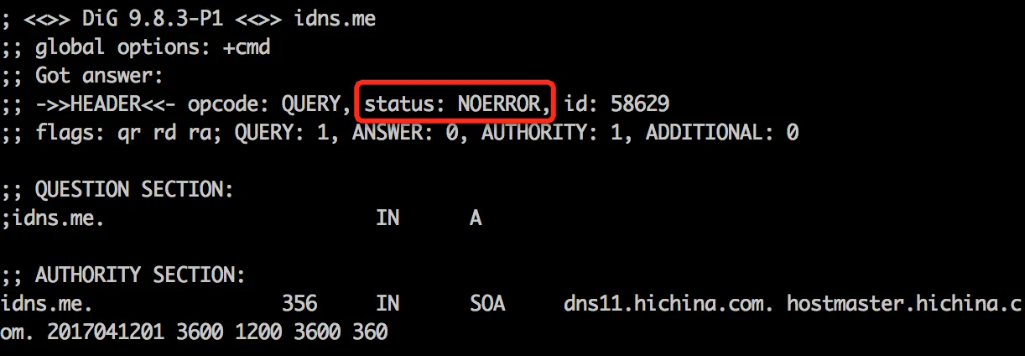
- 0, NOERROR:成功
特殊情况,响应成功但没有解析结果:域名权威服务器及托管的主域名均正常,权威本身也存在这条具体的域名记录,但是没有对应的记录类型(不包含CNAME,CNAME是特殊情况,可以响应任意类型的请求),这时权威返回了NOERROR;值的注意的是这个NOERROR的报文中没有ANSWER SECTION。但是会包含一个AUTHORITY SECTION,内容为改主域名的SOA记录,这个应答结果会在递归服务器中被缓存,缓存时间周期为域名的SOA记录的TTL
- 2, SERVFAIL:服务器失败,域名的权威服务器拒绝响应或REFUSE 递归返回Rcode=2给CLIENT;SERVFAIL的应答结果当然是空结果,但BIND会强制给这个结果增加一个1s的TTL,所以SERVFAIL的应答会在递归服务器中被缓存,缓存时间周期为1s
又分为这样几种情况:1. 权威不响应:包括递归服务器至权威服务器中间的网络异常在内,递归服务器在发出递归请求并完成重试超时后,给请求源一个SERVFAIL的应答,并缓存1s

2.权威向递归服务器应答REFUSE:当权威服务器不存在主域名及对应的SOA记录时,权威会向递归服务器返回REFUSE,即不在我服务的范围内拒绝,递归服务器在收到这个REFUSE应答后,给请求源一个SERVFAIL的应答,并缓存1s

3.权威向递归服务器应答SERVFAIL:当权威服务器存在主域名但是由于zonefile被破坏导致权威服务器上域名的NS记录异常时,权威会向递归服务器返回SERVFAIL,即解析失败,递归服务器在收到这个SERVFAIL应答后,给请求源一个SERVFAIL的应答,并缓存1s
4.权威向递归服务器应答其他的错误Rcode:不常见,递归服务器在收到其他错误应答后,给请求源一个SERVFAIL的应答,并缓存1s
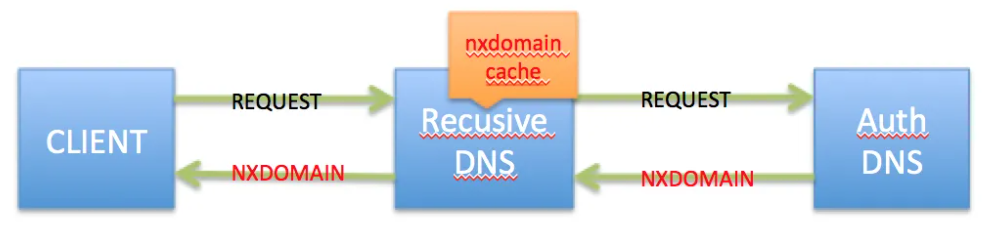
- 3, NXDOMAIN:不存在的记录,该条域名在权威服务器中并不存在
在NXDOMAIN的报文中会包含一个AUTHORITY SECTION,内容为改主域名的SOA记录,这个应答结果会在递归服务器中被缓存,缓存时间周期为域名的SOA记录的TTL
- 5, REFUSE:请求源IP不在服务范围内
除了记录不存在(NXDOMAIN)和解析失败(SERVFAIL)以外,如果请求源不在递归服务器的服务范围内,这种情况下递归服务器会直接给请求源一个REFUSE的应答,本地直接应答无缓存

- 超时,递归服务器不响应

记录
有以下一些记录
- A:域名指向IPv4地址
- AAAA:指向IPv6地址
- CNAME:作为一个域名的别名
- MX:电子邮件服务器地址
- NS:权威域名服务器记录(只有顶级域名才有NS记录)
- TXT:任意
- SOA:起始授权机构记录Start of Authority,在域名有多个NS记录时指定哪个是最权威的,由它告诉其它权威服务器什么时候更新记录
- PTR:A记录的逆向记录,可用于ip反查域名
- AXFR, IXFR:与域传送有关
SPF记录&邮件伪造
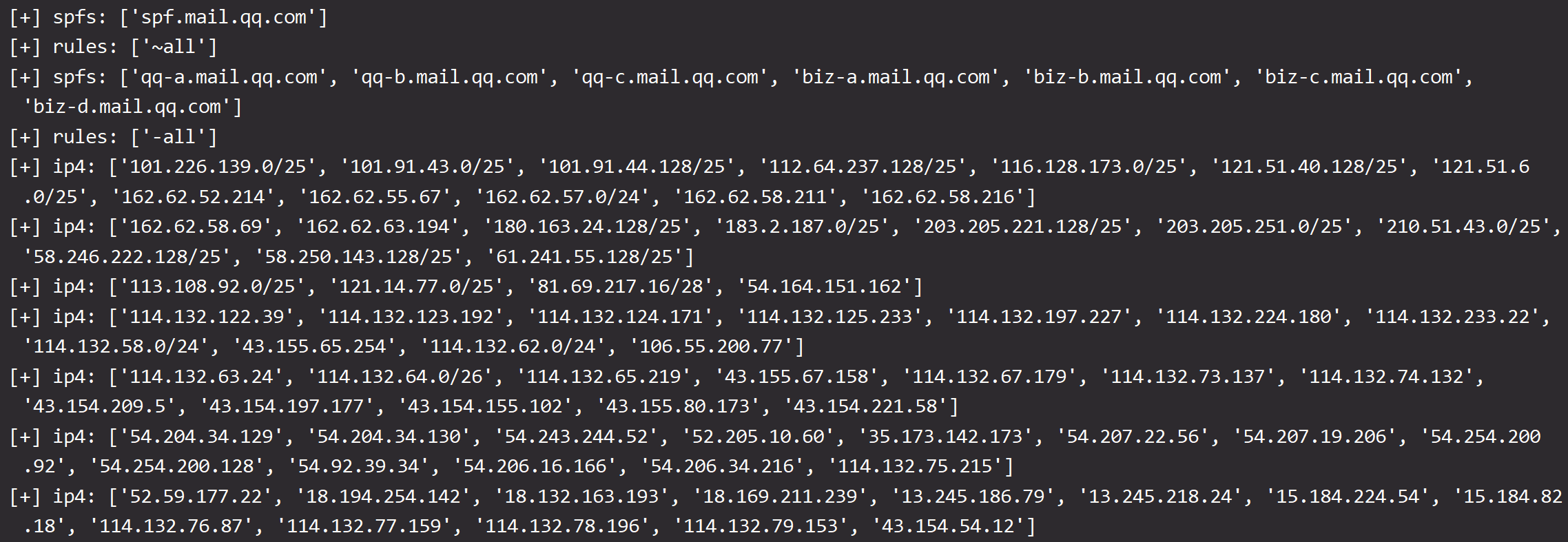
SPF记录是TXT类的一种,用来过滤垃圾邮件,机制是这样的:收件服务器收到admin@example.com发来的邮件,会校验源ip是否在example.com的SPF记录范围内
这其实衍生了一个攻击面,即:通过域名的SPF记录划定资产的ip范围,不过现在很多都会选择163, foxmail等作为邮件服务,所以能用到这一攻击方式的场景不多
写个py来处理这个需求
import re
import dns.resolver
def resolve(domain, type, note=''):
if type == 'spf':
resolveSPF(domain)
elif type == 'A' and note == 'takeover':
resolveA(domain)
else:
if answers := dns.resolver.resolve(domain, type):
return answers.rrset
else:
return None
def resolveSPF(domain):
ip4_list = []
ip6_list = []
if records := resolve(domain, 'TXT'):
for record in records:
record = str(record)
if record[1:6] == 'v=spf':
if spfs := re.findall(r'include:(\S+)\s?', record):
rules = re.findall(r"\s(\S+)$", record)
print(f'[+] spfs: {str(spfs)}')
print('[+] rules: ' + str(rules).replace('"', ''))
[resolveSPF(i) for i in spfs]
else:
matchs = re.findall(r'(ip[46]):([\w:./]+)', record)
ip4_list += [ip[1] for ip in matchs if ip[0] == 'ip4']
ip6_list += [ip[1] for ip in matchs if ip[0] == 'ip6']
break
else:
print('[!] no spf record')
exit(1)
else:
print('[!] no TXT record')
exit(1)
if ip4_list:
print(f'[+] ip4: {str(ip4_list)}')
if ip6_list:
print(f'[+] ip6: {str(ip6_list)}')
resolveSPF(input('domain: '))
我他妈都快写完了,突然想到可以用ChatGPT啊,于是它几秒之内给出了这样的答案
from dns import resolver, rdatatype
def process_spf(record_str):
"""
处理spf记录
"""
segment_list = record_str.split(' ') # 拆分成段
ip_list = []
domain_list = []
for segment in segment_list:
if segment.startswith('ip'):
ip_list.append(segment[3:])
elif segment.startswith('include'):
domain = segment[8:].strip('"') # 去掉双引号
spf_record = query_txt_record(domain)
sub_domain_list, sub_ip_list = process_spf(spf_record)
domain_list += sub_domain_list
ip_list += sub_ip_list
return domain_list, ip_list
def query_txt_record(domain):
"""
查询域名的TXT记录
"""
try:
result = resolver.query(domain, rdatatype.TXT)
except Exception as e:
return ''
records = [r.to_text()[1:-1] for r in result]
spf_records = [r for r in records if r.startswith('v=spf')]
if spf_records:
return spf_records[0]
else:
return ''
if __name__ == '__main__':
domain = 'example.com'
spf_record = query_txt_record(domain)
domain_list, ip_list = process_spf(spf_record)
print('Domains:')
print(set(domain_list))
print('IPs:')
print(set(ip_list))
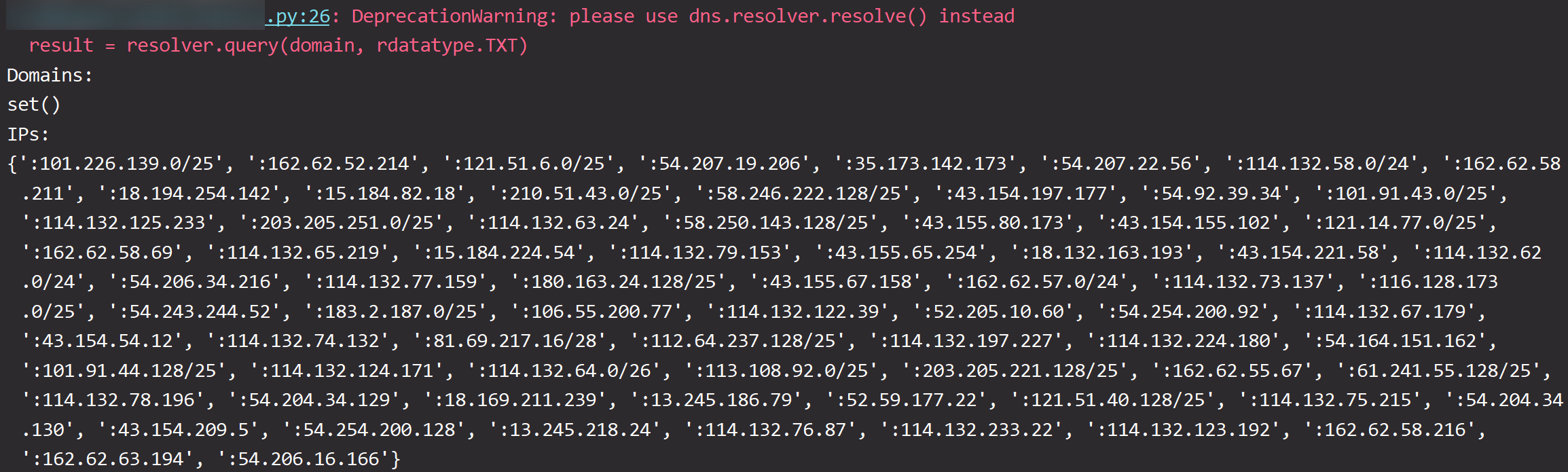
……行,ChatGPT牛逼,我下岗了,是我冒犯了
CNAME&子域接管
直接举例:
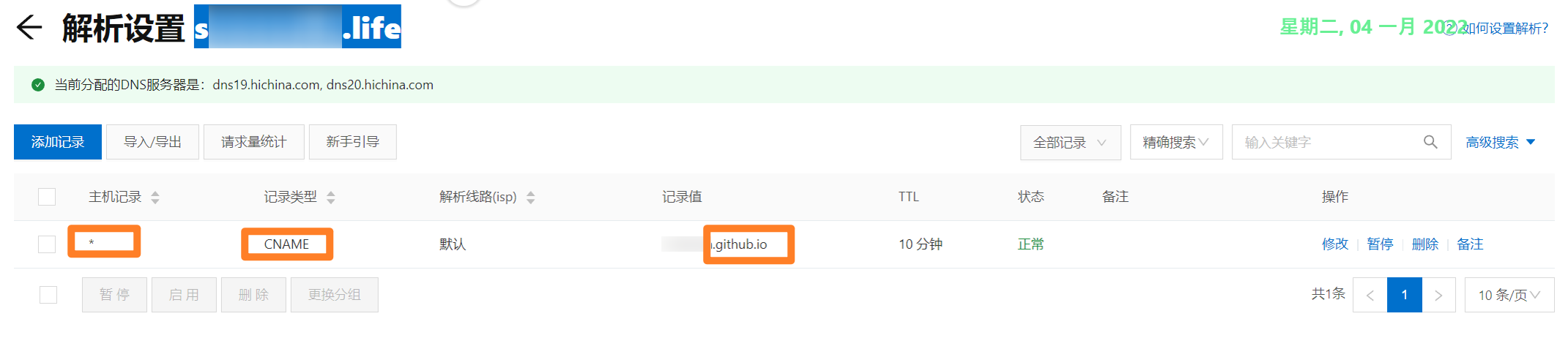
当CNAME像这样是*时会导致子域名接管,此时我们随便一个abcd.github.io都可以设置自己的CNAME为abcd.sxxxxx.life,并且可以正常访问
这是相当危险的漏洞,因为可以直接绕过诸多对于跨域、跨源的限制,甚至绕过一些限制域名的waf

由于这样的配置下任意子域都存在一样的A记录和CNAME记录,我们借此来快速判断域名是否存在子域接管漏洞(我这里代码是比对A记录的,CNAME也可以(写的时候脑子短路了)
def resolveA(domain):
tmp = tldextract.extract(domain)
qwe = []
asd = []
if qwe_records := resolve(f'{uuid.uuid4().hex[0:random.randint(6, 32)]}.{tmp.domain}.{tmp.suffix}', 'A'):
for record in qwe_records:
qwe.append(str(record))
print(f'[+] qwe.{tmp.domain}.{tmp.suffix}: {qwe}')
if asd_records := resolve(f'{uuid.uuid4().hex[0:random.randint(6, 32)]}.{tmp.domain}.{tmp.suffix}', 'A'):
for record in asd_records:
asd.append(str(record))
print(f'[+] qwe.{tmp.domain}.{tmp.suffix}: {asd}')
if set(qwe) == set(asd):
print(f'[*] {tmp.domain}.{tmp.suffix} exists subdomain-takeover vuln')
else:
print(f'[!] no subdomain-takeover vuln')
PTR&反查域名
如何实现ip反查域名?由于一个ip可以对应多个域名,理论上我们可以遍历整个域名树——这未免太蠢了,所以为了解决这个问题产生了逆向解析域in-addr.arpa,当我们要查12.23.34.45这个ip对应的域名时,反向被解析的ip地址就会变成域名一样的形式:45.34.23.12.in-addr.arpa
能成功反查域名的前提是这个域名有被配置过反向解析
dig -x <ip>
nslookup -type=ptr <ip>
AXFR&域传送
*详细的漏洞成因&分析见DNS 域传送漏洞学习
dig @<vuln-dns-server> -t axfr <domain>
nslookup ls <domain> <vuln-dns-server>
如果存在漏洞 可以通过这样的命令列出域内的所有记录
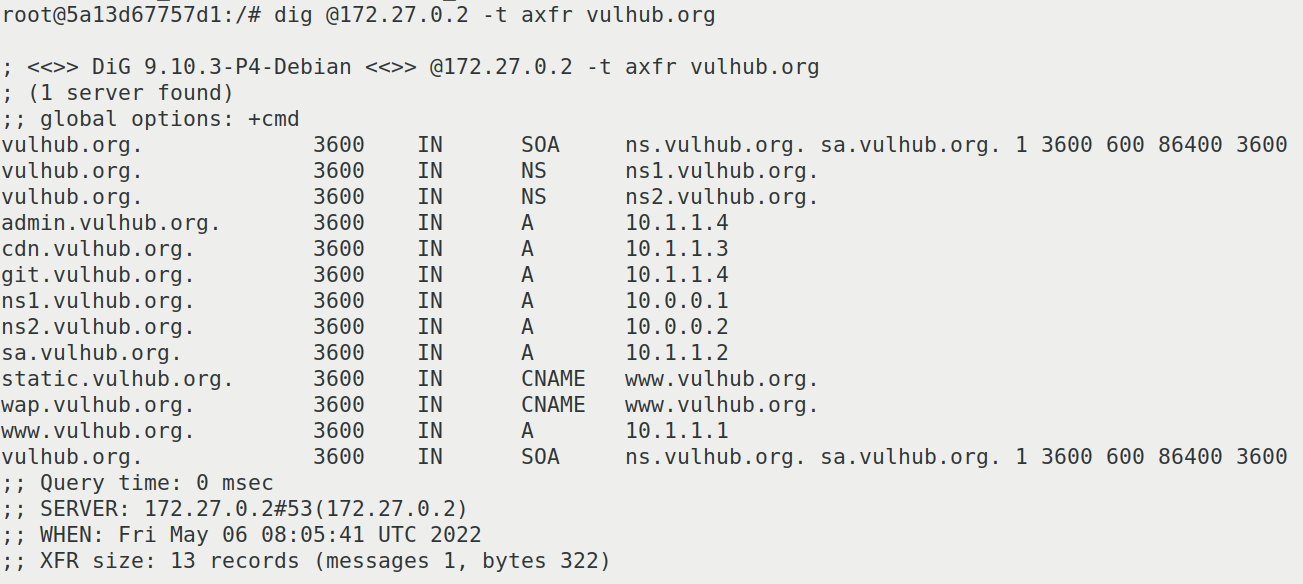
常用命令
nslookup和dig都不能一次查域名的所有记录,只能多次查询;以下是他们支持的type
- A: Specifies a computer’s IP address.
- ANY: Specifies a computer’s IP address.
- CNAME: Specifies a canonical name for an alias.
- GID Specifies a group identifier of a group name.
- HINFO: Specifies a computer’s CPU and type of operating system.
- MB: Specifies a mailbox domain name.
- MG: Specifies a mail group member.
- MINFO: Specifies mailbox or mail list information.
- MR: Specifies the mail rename domain name.
- MX: Specifies the mail exchanger.
- NS: Specifies a DNS name server for the named zone.
- PTR: Specifies a computer name if the query is an IP address; otherwise, specifies the pointer to other information.
- SOA: Specifies the start-of-authority for a DNS zone.
- TXT: Specifies the text information.
- UID: Specifies the user identifier.
- UINFO: Specifies the user information.
- WKS: Describes a well-known service.
nslookup
- 命令行模式
# 返回指定类型的记录(默认A记录) 可指定DNS server
nslookup -type=<type> <domain> <dns-server>
# 返回域名ttl
nslookup -d <domain> <dns-server>
# 列出域
nslookup ls
nslookup view
- 交互模式
nslookup
set type=txt
server <dns-server>
<domain>
dig
比nslookup返回的信息要全
- 命令行
# 通用 b指的是主机ip 指定本机哪个ip向DNS server发送请求
dig @<dns-server> -P <dns-port> -t <type> -b <ip> <domain>
# 反查ptr
dig -x <ip>
# 仅获取ip 精简输出
dig +short <domain>
# 获取递归过程的查询结果 处于安全考虑 很多组织严格限制了可以发起递归查询的主机
dig +trace <domain>
- 交互模式
略
host
host <ip>
host -C <type> <domain>
默认返回的信息很简略,good(加-v可以得到和dig一样的效果
whois
查询域名的注册情况
whois www.example.com
会暴露使用的域名厂商、个人姓名、注册省市
协议的多种安全尝试
说到DNS我们的第一反应一定是“它使用UDP协议”,但实际上TCP协议也有参与,在DNS的设计之初就在域传送中引入了TCP协议,而随着时代发展日益增长,各类记录 导致动辄超过512byte而被截断的UDP渐渐不能满足我们的要求,最终在DNS出现的30多年之后,RFC 7766提出使用TCP作为主要协议来解决UDP无法解决的问题,TCP也不再只作为一种被截断再重试时使用的机制(RFC1123),随后出现的DNS over TLS, DNS over HTTPS也都是对DNS协议的补充
可能有人要问了:为什么传输数据多了就一定要用TCP呢?从理论上来说,EDNS机制下一个UDP的数据包最多到64kb 已经远超常见DNS查询所需的开销(查询协议头42byte+响应协议头42byte 请求体和响应体预计15和70byte),但实际生产中 一旦数据包中的数据超过MTU(传送链路的最大传输单元 一般1500byte),当前数据包可能会被分片传输、丢弃,部分设备甚至会拒绝包含ENDS(0)选项的请求,这就导致使用UDP协议的DNS不稳定,而TCP作为“可靠”的传输协议 用来解决这个问题就再合适不过了,通过序列号、重传等机制可以保证消息的不重不漏,消息接收方的TCP栈会对分片的数据重新进行拼装,DNS等应用层协议可以直接处理好完整数据,同时 当数据包足够大的时候,TCP三次握手带来的额外开销比例就会越来越少
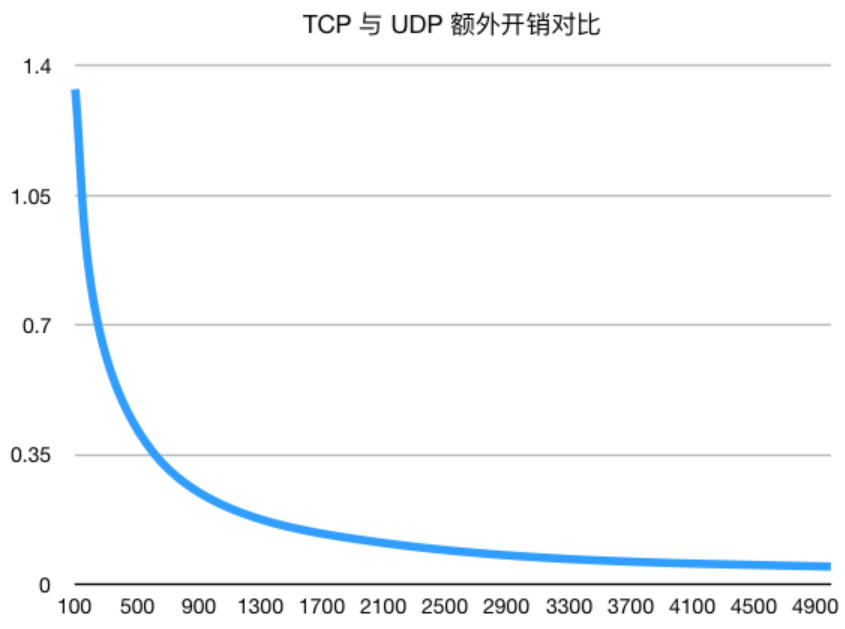
实际环境中,如果DNS响应数据包太大 将会在tc位设1,表明这个数据超长而有删节

本地DNS服务看到这样的响应就会尝试建立TCP连接来重发
下面来说几个DNS发展过程中为了安全、可靠而多次引入的几个机制
EDNS
在2020的DNS Flag Day提出ENDS(Extension Mechanisms for DNS),在遵循已有的DNS消息格式上增加字段来支持更多类型的DNS请求业务,提出的理由是这样的
- DNS协议头部的第二个16字节中都已经被用的差不多了,需要添加新的返回类型(RCODE)和标记(FLAGS)来支持其他需求
- 只为标示domain类型的标签分配了两位,现在已经用掉了两位(00标示字符串类型,11表示压缩类型),后面如果有更多的标签类型则无法支持,建议用上 10 和 01
- 当初DNS协议中设计的用UDP包传输时DNS数据大小限制为512字节,现在很多主机已经具备重组大数据包的能力,所以要有一种机制来允许DNS请求方通知DNS服务器让其返回大一些的数据包
为了确保向后兼容,EDNS引入了一种新的伪资源记录OPT RR(Resource Record);之所以叫做伪资源记录 是因为它不包含任何DNS数据,OPT RR不能被cache、不能被转发、不能被存储在zone文件中中,它被放在DNS通信双方DNS数据包的ADDITIONAL SECTION中,每个DNS数据包中只能有一个OPT伪资源记录,当有多种EDNS扩展协议时,各个{attribute, value}对一个紧接一个存储在RDATA中
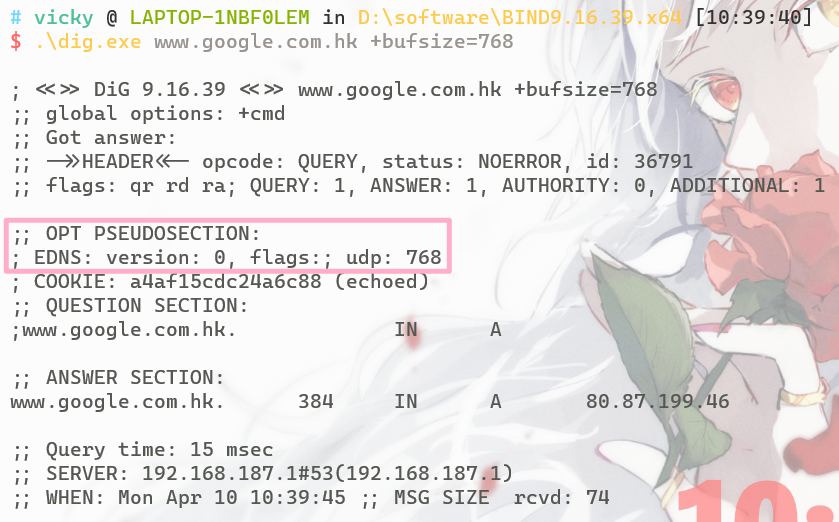
所以也很显然:EDNS的支持与否跟域名关联的权威服务器强相关,可以直接dig看有没有OPT RR来判断是否开启,或通过dns.google.com来查询
https://dns.google/resolve?name=<url>&type=A&edns_client_subnet=119.6.6.6
这里用到的edns_client_subnet和cdn有关,支持DNS Resolver传递用户的ip地址给权威server,CDN根据该ip地址可以更好的进行资源调度;更多内容可以参照google的文档
OPT的另一个作用是指出UDP payload size,它可以告诉DNS服务器 自己作为CLIENT能处理的最大UDP报文大小(满足扩大UDP传输大小的需求),参照文档,用dig时默认的bufsize是1232,允许最小bufsize为512,最大为4096,如果设置的size过小会自动调整到512~4096的范围内,如果传输的数据大于设定的bufsize会导致内容截断
dig <domain> +bufsize=xxx
*个人感觉实战用到这一点难度较高,因为本身最小的bufsize 512已经是取众数之后设出的规范,一般简单的查询很难突破这一限额,想要在这一点上做文章……我匮乏的想象力不知道该怎么做,另外EDNS是否开启、客户端是否支持等等也是一系列玄学问题Orz
DNSSEC
Domain Name System Security Extensions,流程基本没变,只是在权威服务器返回响应时附带type是RRSIG(Resource Record Signature)的PR

DNSSEC解决中间人攻击的方式是KSK
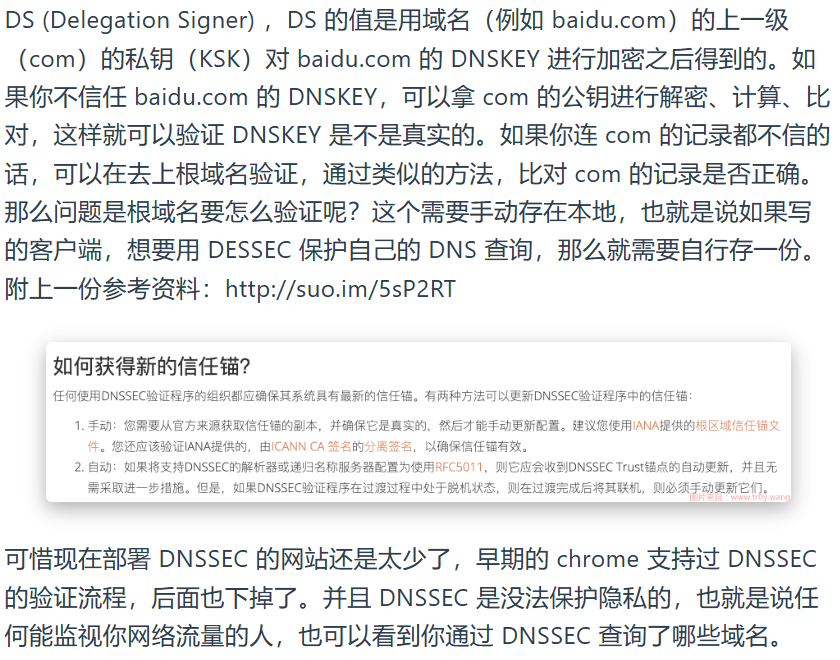
*偷个懒直接截图了()