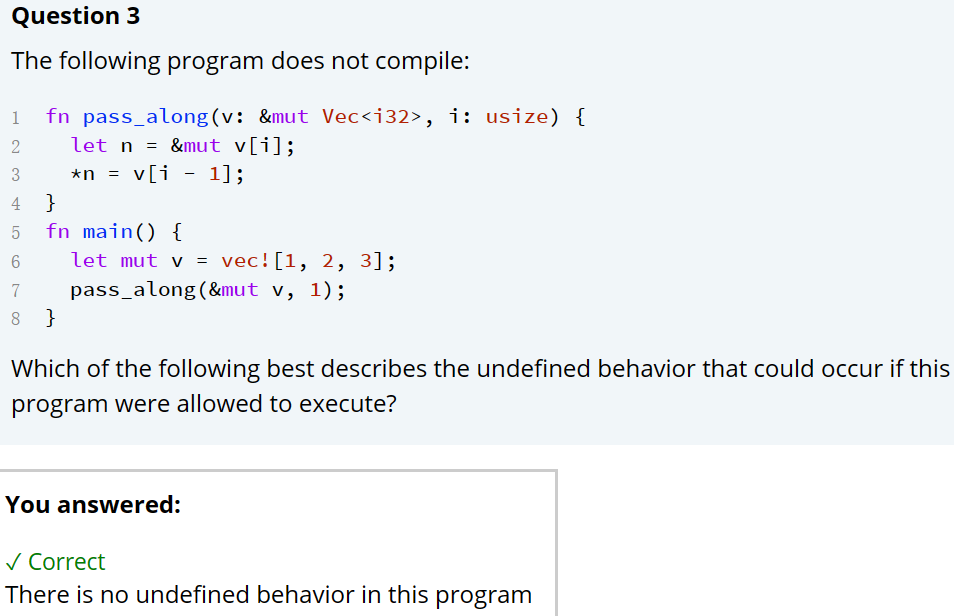
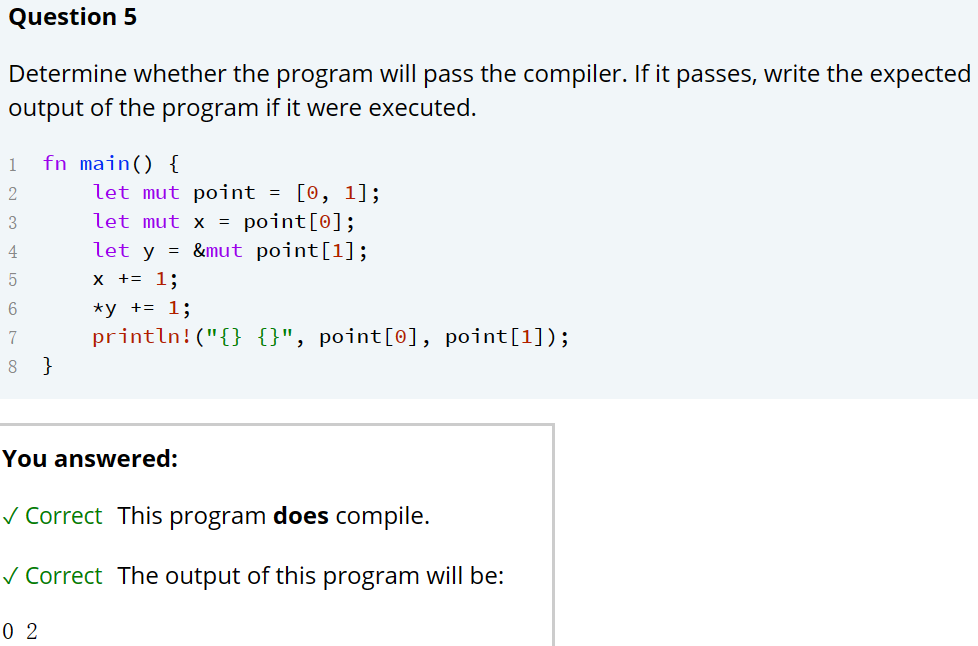
Q: 为啥突然学Rust?
A: 没有为啥,闲的 一方面是入夏以来输入/输出都很少,不是好现象,另一方面是也在听南大的操作系统课,rust正好就是对标c/c++的系统级编程语言,不如拿来学学 跟上最新的语言特性和发展进程x
环境配置
*为了上手方便,暂时下文涉及到的都是windows环境(我懒)
- 前提:Visual Studio及相关组件 https://visualstudio.microsoft.com/zh-hans/downloads/
如果不安装这些组件会直接影响Rust的正常运行
如果直接用rustup-init.exe安装,会默认安装Windows 11 SDK,我是手动在Visual Studio Installer中选择了Windows 10 SDK

*也可以不用官方的installer、不安装Visual Studio,用独立出来的cpp build tools~
本体:https://www.rust-lang.org/tools/install
IDE:Intellij Rust插件
曾经我也是重视的VS code信徒,但其实看似简单之下隐藏了很多繁琐的配置,而且内存占用其实并不小……还是入股Intellij了
- Hello, world!
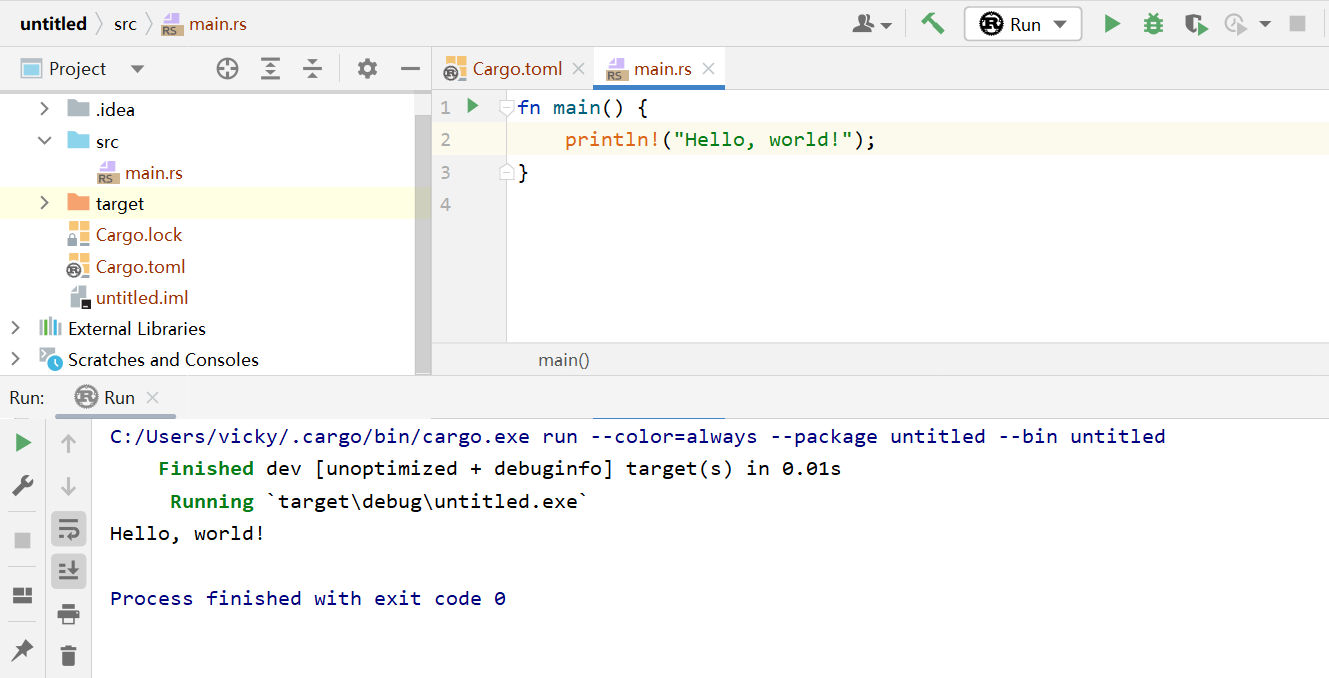
Intellij Rust默认配置下会直接生成Cargo项目 方便管理
- 卸载Rust
如果一个不小心安装有问题…
rustup self uninstall
语言特色
这几年断断续续接触了很多语言(C, Python, PHP, Java, Javascript, Go….),逐渐感受到各个编程语言在“和而不同”之余 存在各自的“舒适区”,这个舒适区由语言特性等很多因素共同决定;如果硬把需求安排在一个不适合的语言,那真的是如鲠在喉,语言是工具 不是目的
- 优点:速度快,内存利用率高,性能好,生成的可执行文件为静态编译,跨平台
- 缺点:编译器严格、编译耗时长,学习曲线陡峭
- 与其他语言的对比:属于强类型,代码风格类似C/C++,会用项目的概念来组织代码文件(类似Java的Maven)
- 敏感肌也很喜欢:可以编写shellcode loader
- 杀手级特性:让可能出现的安全问题、undefined behavior消失在编译前
语法基础
use this book~ The Rust Programming Language
变量&可变性
const修饰的都是完全不可变的,必须指明数据类型,作用域为全局
let修饰的不可变,let mut修饰的可变,作用域为当前函数
shadowing的存在使我们可以使用同名变量,但只有可变的变量才可以被shadowing
fn main() {
const SECRET_NUM: u32 = 12;
let a = "a";
// a = "b"; // will error, not mutable
let mut x: u32 = 1;
{
let mut x = x;
x += 2; // shadowing
println!("{x}"); // 3
println!("{SECRET_NUM}") // 12
}
println!("{x}"); // 1
println!("{SECRET_NUM}") // 12
}
数据类型
rust是statically typed language静态类型语言,写代码时没有显式声明的类型都会由编译器进行推断,如果发生错误会无法成功build
标量
- 整型:默认i32,isize/usize主要作为某些集合的索引,编译器会检测interger overflow
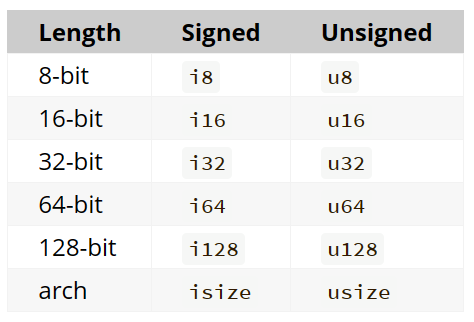
*debug模式编译下会检查integer overflow,release构建中则不会检查,如果出现此类错误 rust会进行two’s complement wrapping的操作(也就是u8下 256->0, 257->1),不会因此panic 但可能出现非预期情况,不鼓励这样做;如果确实需要这样的“优化”,可选用如下函数

*对这一特性我表示存疑,本机环境cargo 1.70.0 (ec8a8a0ca 2023-04-25),并不会因为加上--release就不检查溢出了,还是会在compile阶段报错退出
浮点型:默认f64(与f32速度几乎一样 但精度更高)
布尔型:true, false(fool)
字符型:单引号char代表一个unicode标量值
复合类型
- 元组tuple 可包含不同类型数据, 数组array 必须每个元素类型相同
fn main() {
let tup = (500, 3.14, 42); // tup: (i32, f64, u8)
let (x, y, z) = tup; // destructuring
println!("{z}"); // 42
println!("{}", tup.1) // 3.14
}
fn main(){
let t = ([1; 2], [3; 4]); // t: ([i32; 3], [i32; 4])
let (a, _) = t; // a = [1, 1], _ = [3, 3, 3]
println!("{}", a[0] + t.1[0]); // 4
}
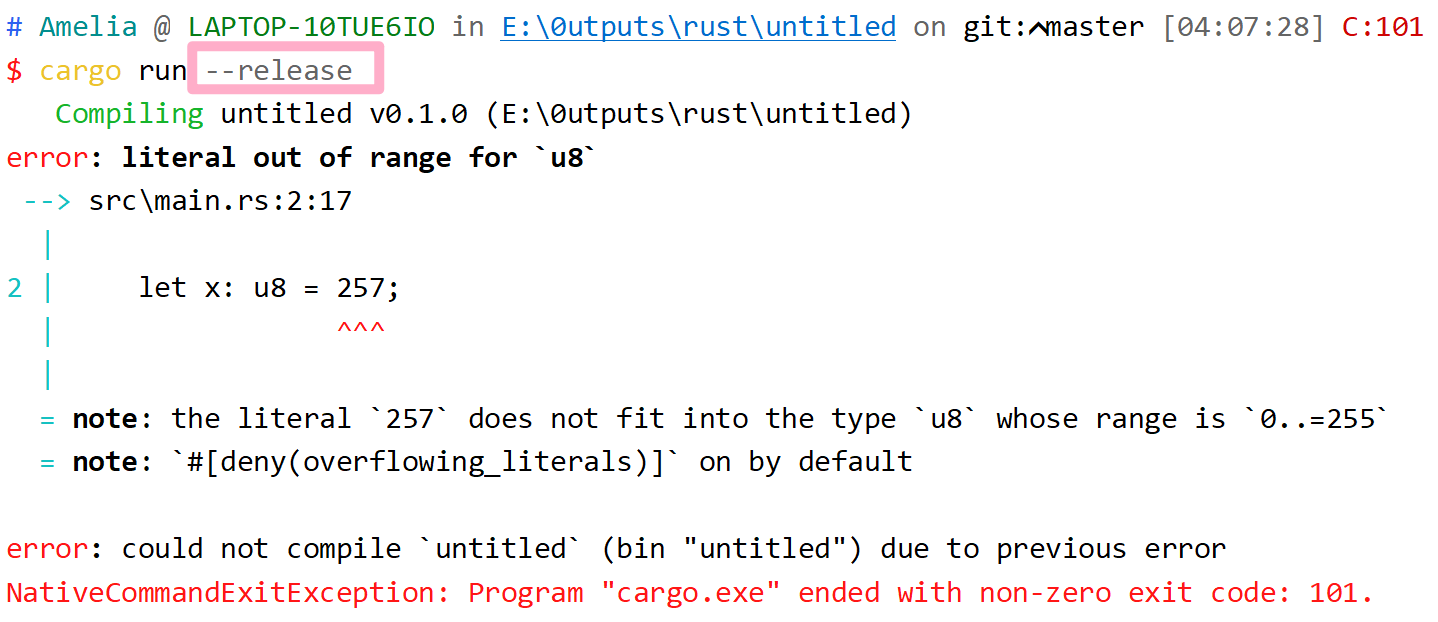
*当出现数组元素越界访问时不会出现编译错误,但会出现运行时错误而panic退出
use std::io;
fn main() {
let a = [1, 2, 3, 4, 5];
println!("Please enter an array index.");
let mut index = String::new();
io::stdin()
.read_line(&mut index)
.expect("Failed to read line");
let index: usize = index
.trim()
.parse()
.expect("Index entered was not a number");
let element = a[index];
println!("The value of the element at index {index} is: {element}");
}
函数
函数和变量名均使用snake case规范(下划线分隔小写单词),被使用的函数可位于任何位置,main为入口
函数声明必须带参数类型
可以用{}创建新作用域(代码块),{}是会计算并返回值的表达式,表达式的结尾没有分号,语句有分号、不返回值
函数的返回值无需命名,但需要声明类型
fn main() {
let x = plus_one(5);
println!("The value of x is: {}", x);
}
fn plus_one(x: i32) -> i32 {
x + 1 // `x + 1;` will error
}
控制流
可以直接对变量使用if/else,但要小心由此可能产生的类型问题:变量必须只有一个类型
循环有loop/while/for,loop需要手动停止循环,可以通过设置label来停止嵌套loop(适用于多次重试)
fn main() {
let mut count = 0;
'counting_up: loop {
println!("count = {count}");
let mut remaining = 10;
loop {
println!("remaining = {remaining}");
if remaining == 9 {
break;
}
if count == 2 {
break 'counting_up;
}
remaining -= 1;
}
count += 1;
}
println!("End count = {count}");
}
for可以方便的遍历数组,方便程度不亚于python
fn main() {
let a = [10, 20, 30, 40, 50];
for element in a {
println!("the value is: {element}");
}
}
fn main() {
for number in (1..4).rev() {
println!("{number}!");
}
println!("LIFTOFF!!!");
}
所有权
所有权ownership是rust的特性,正是它让rust做到内存安全和无需垃圾回收
这里的“安全”,在rust中意味着完全不容许undefined behavior的存在(即使unsafe也不行),为了实现这一目标 rust将大量的功夫用在了compile-time而不是run-time,这样减少了潜在的运行时bug 也侧面提升了性能(减少运行的check),所有权则是这一理念下 内存安全方面的具体实践
堆&Box
rust中,和函数有关的参数等数据存于栈上,堆上的数据则可以不依赖函数独立分配,可以使用Box::new来手动分配数据到堆,所有权会自动在“合适的时机”释放这块内存
Box deallocation principle(fully correct): if a variable owns a box, when Rust deallocates the variable’s frame, the Rust deallocates the box’s heap memory. 原则:当使用Box的变量在它的作用域内结束、被释放,那Box所在的堆内存也会被释放(也就是上面说的“合适的时机”,这一释放过程都被rust自动管理,无需手动控制)
很多数据结构内部都是用Box实现的,比如Vec, String, HashMap
下面的栗子里,但执行到第四行时会报错,因为first已经不指向Ferris了
fn main() {
let first = String::from("Ferris"); // L1
let full = add_suffix(first); // L4
println!("{full}, originally {first}"); // L5 will error!!!
}
fn add_suffix(mut name: String) -> String {
// L2
name.push_str(" Jr."); // L3
name
}
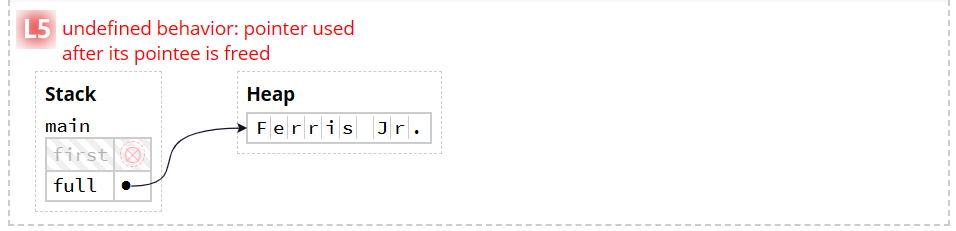
实际过程则是这样的:
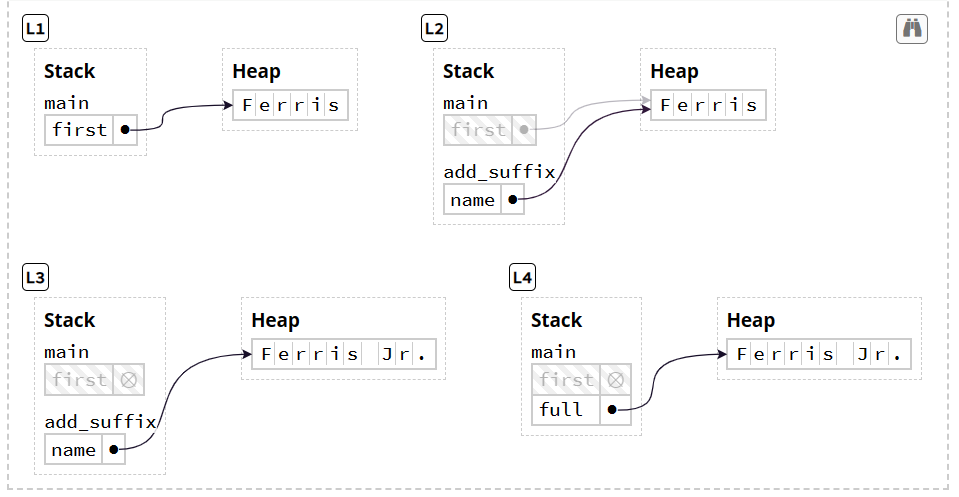
在L2阶段时发生指针复制,原有指针未消失,但我们不能再直接用原来的指针,也就是下面的规则:
Moved heap data principle: if a variable x moves ownership of heap data to another variable y, then x cannot be used after move.
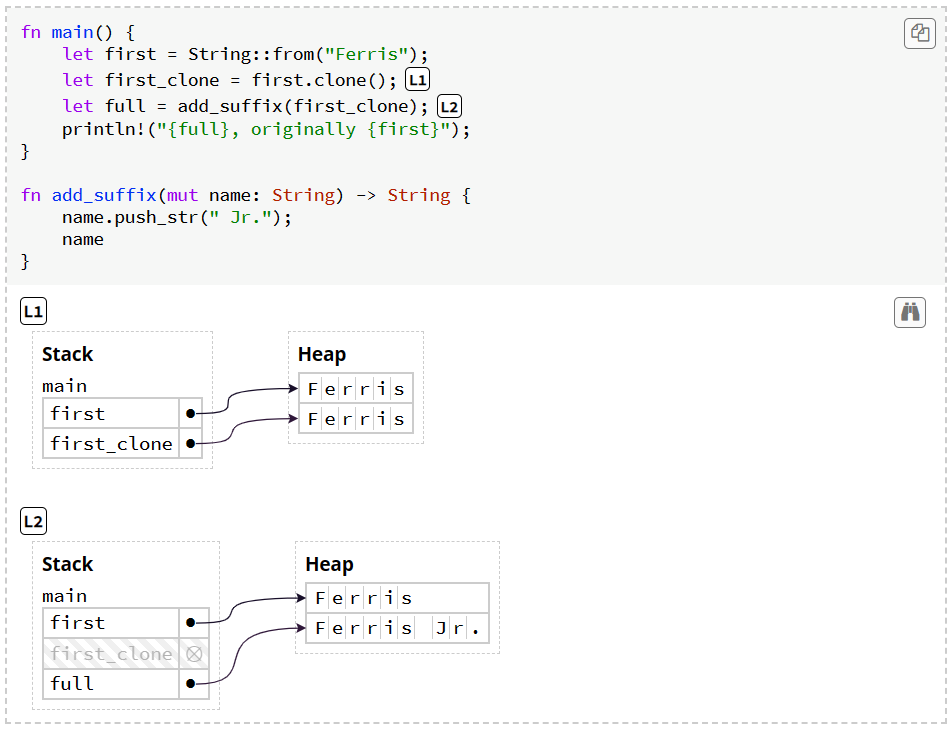
clone方法可以在指针复制的同时不丢失原指针的所有权,“绕过”上面的规则
在同一作用域内、只在栈上拷贝的数据也不受上述规则的限制(废话了,毕竟是在栈上)
*答错的一道quiz:选出下面会出现undefined behavior的选项

关键在于:在b被传入move_a_box后、b才会被释放
引用&借用
*这部分内容有C的基础会好理解一些
非常显然,如果严格按照上面所有权的规则进行 变量被moved之后再想找到原来的值就需要在函数上添加一个返回值,然而我们经常需要使用那个值!
引用reference就是解决这个问题的,它作为Non-owning pointer存在,允许使用堆上的值 但不直接指向堆
fn main() {
let m1 = String::from("Hello");
let m2 = String::from("world"); // L1
greet(&m1, &m2); // L3
let s = format!("{} {}", m1, m2);
}
fn greet(g1: &String, g2: &String) {
// L2
println!("{} {}!", g1, g2);
}
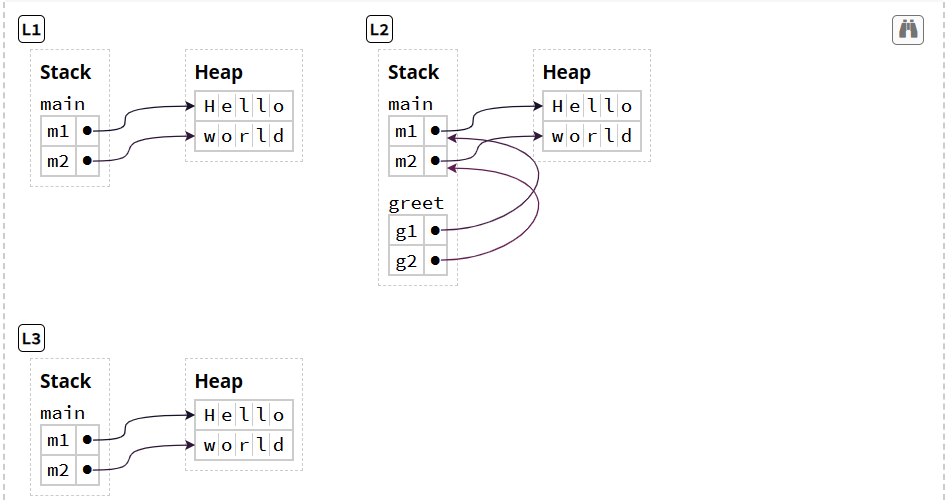
&m1作为m1的引用、再作为greet的参数,这一行为被称为借用borrowing
*作为前缀表示解引用,可以读出具体数据,修改*x的值就是修改x指向堆内存的值

只有第一次的解引用*x可以被修改值并同步堆内存的修改,二次解引用的**&x只可以读值不可以修改,而&*x是直接指向值的引用指针、和*x的数据类型并不一样
*x, **&x和*&*x三者是完全等价的(数据类型、值),都可以直接读出堆内存指向的值,但只有*x可被改值
Pointer Safety Principle: data should never be aliased and mutated at the same time. 数据不可以同时 既有别名(存在引用)、又本身可变
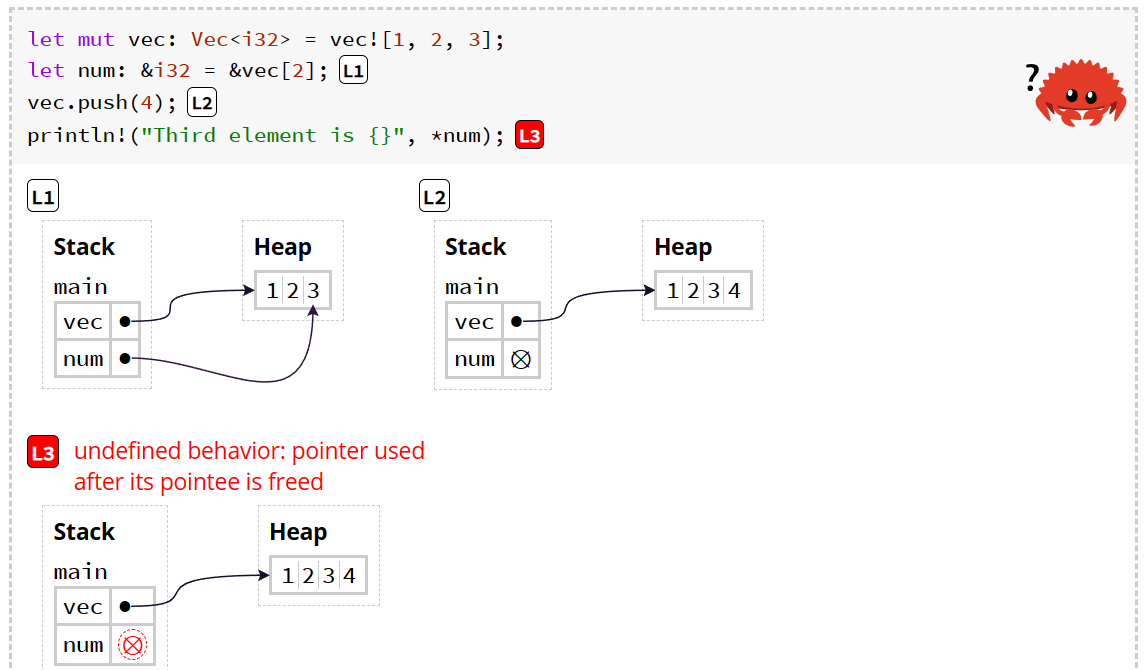
在上面的例子中,当vec.push(4)被执行时,原vec的cap和len都需要增大,为了满足新的cap和len的需求 很可能会重新分配在堆上的位置,所以num是否还指向vec[2]就是undefined behavior,很可能出现潜在的安全问题,所以这一行为会被编译器阻止
borrow checker的核心原理是检查它们的权限
- read: data can be copied to another location
- write: data can be mutated in-place
- own: data can be moved or dropped
这些权限只存在于编译期用于编译器来进行检查,而引用/别名的出现会暂时对原有变量的权限做出改变;让我们深入了解在上面例子中 read, write, own权限都发生了什么样的变化:
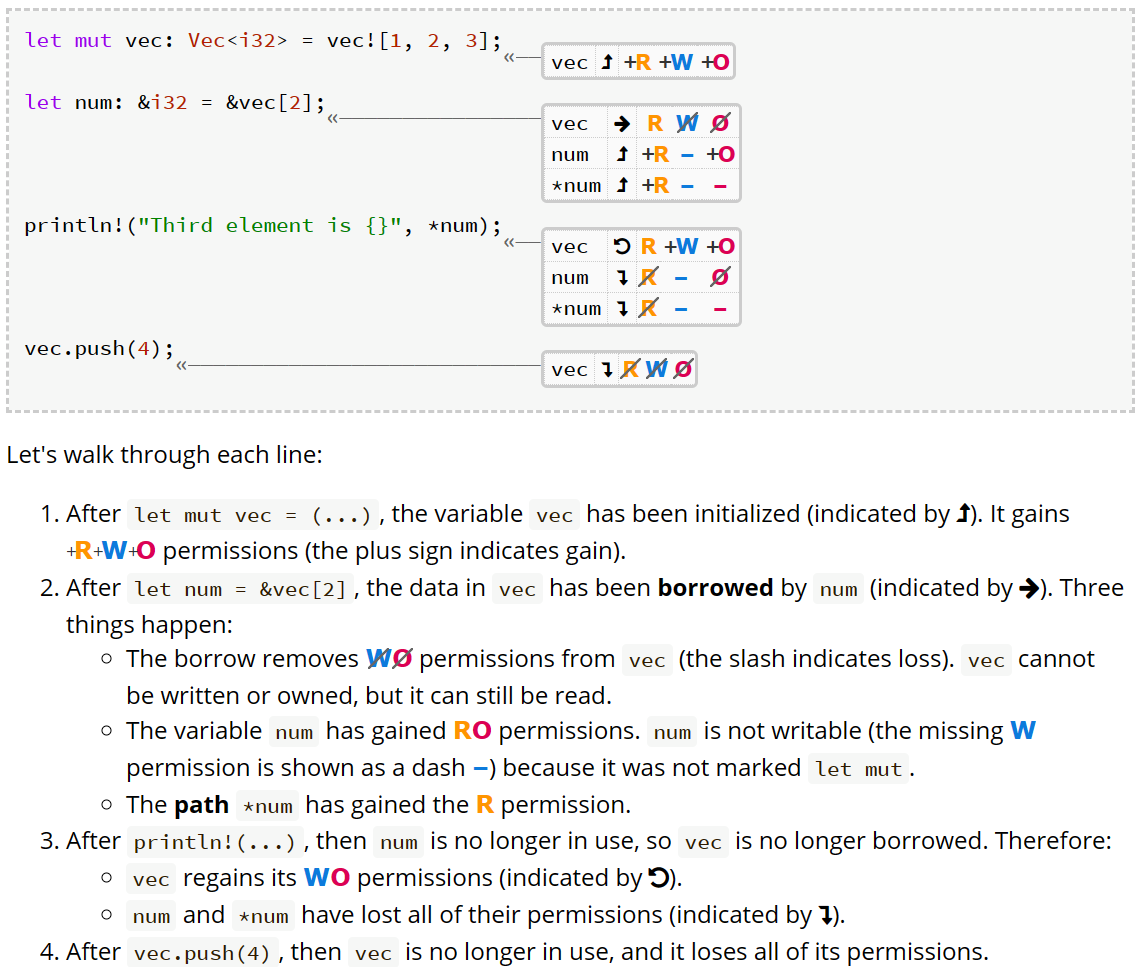
我们可以看到,在vec被num借用期间,vec会丢失write和owner权限,而对应的num如果可变则获取write和owner权限 不可变则只获得owner权限,*num的权限和被借用的vec保持一致;一旦存在引用就会使数据的权限发生变化(暂时变成read-only),当引用消失 权限就会立刻回收,把write+owner权限还给原数据
而上上张图(出现undefined behavior的反例)中则有这样的权限关系

编译时会在vec.push(4)就报错 而不是第四行

浅层原因(蛋)是borrow checker已经检测到 第三行的vec只有read,而write权限被num借走了,所以此时vec不可变 导致报错,深层原因(鸡)则是rust为了避免可能存在的安全问题 而设计了这样的borrow checker(先鸡后蛋)
上面所有提到的&引用都是不可变引用immutable reference(也叫做shared references),它作为non-owning pointer 只作为不可变的别名;然而我们也可以让它暂时拥有write权限(仍然非owner),也就是&mut,可变引用mutable reference(也叫做unique reference)

对比前面的不可变引用num有这些区别:
- 不可变引用:原数据仍有read权限,
num只读+owner,*num只读 - 可变引用:原数据失去所有权限,
num只读+owner,*num可读可写
在可变引用存在时,实际是允许了可变而避免了别名——原数据失去read权限,而*可变引用可读可写,可以直接通过*可变引用操作原数据内容
可变引用也可以降权为read-only的引用

这里的num2是对*num的引用,因此把*num的write和owner权限借走了,又因为是不可变引用,*num2只读 不可写
上面讨论的都是在顺序执行流里 权限在引用存在时的流动关系,当if-else等控制流存在时 基本相同,不再赘述
*两道比较复杂的题,有亿点让人头大
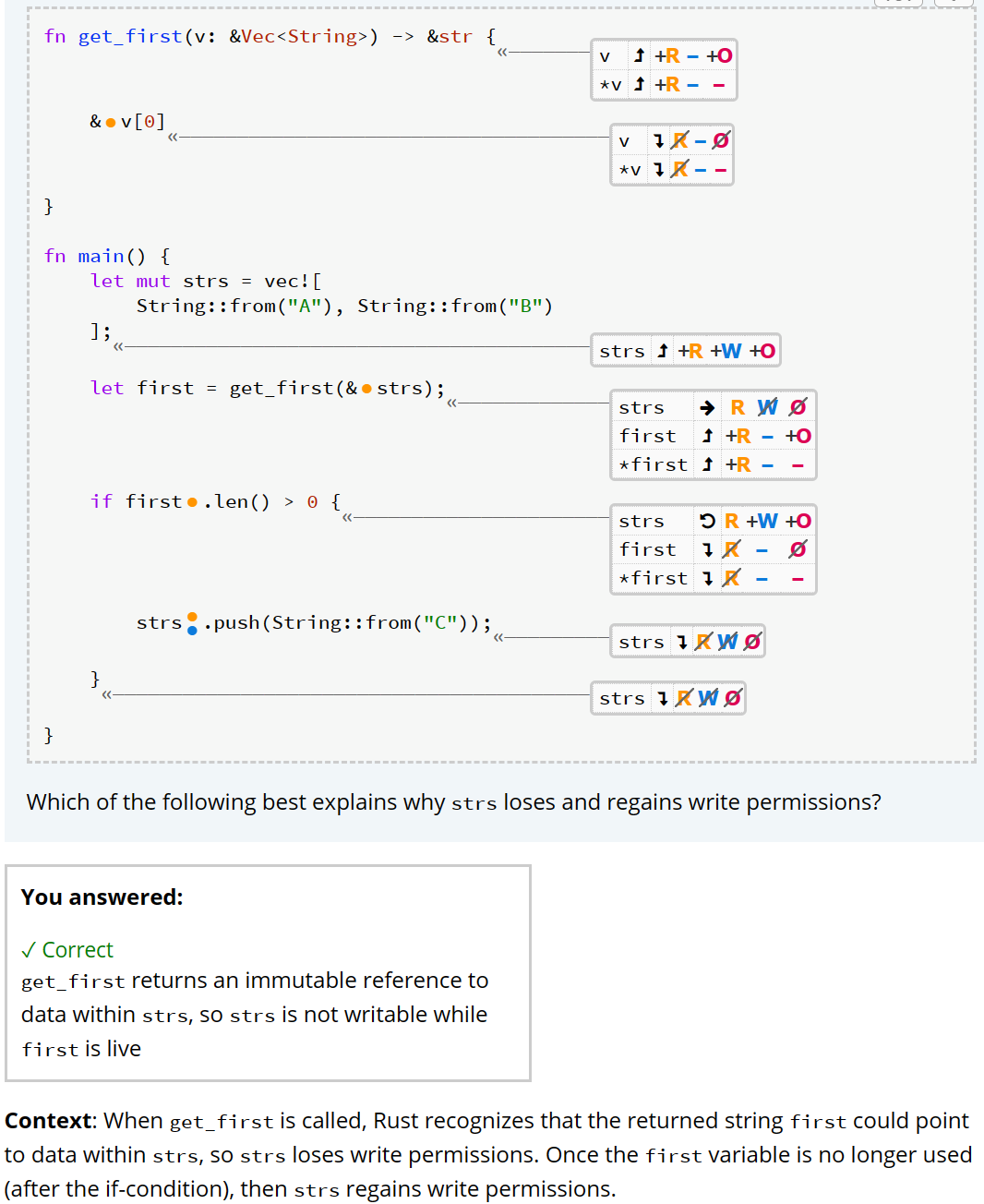
当rust判断 数据存在引用时,就会失去原有的write权限,当引用结束了它的生命周期,write会被归还
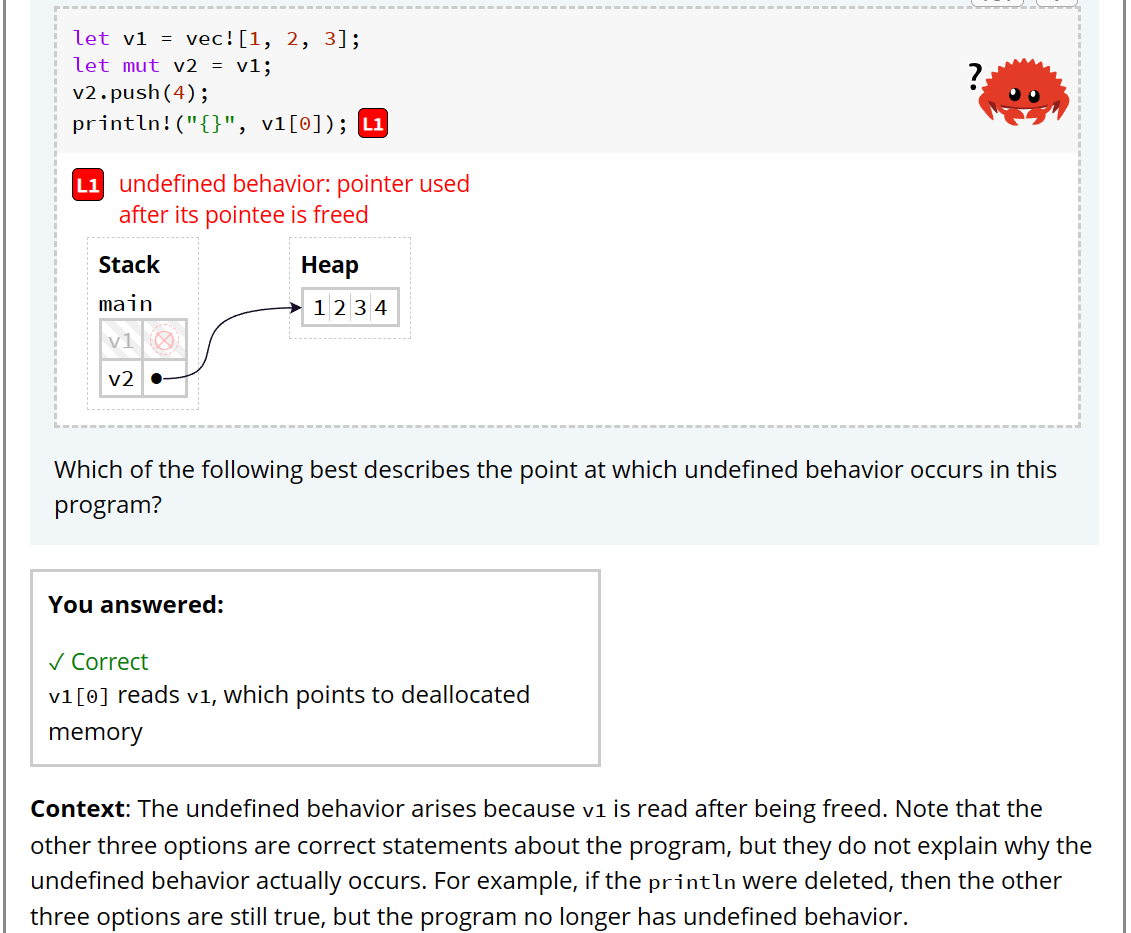

这个题 其它几个选项的描述都是对的,但只有use after being free的解释是最根本的
作为Pointer Safety Principle的一部分,borrow checker也会强制要求数据的生存时间必须大于它的任何引用,然鹅 当引用作为函数的输入或输出时,rust是无法确定这个引用的生存周期的,rust在这种情况下引入了F权限


这个例子就不会被成功编译,因为只从函数声明来看无法确定输出的&String类型的对象是strings的引用还是default的引用;如果default进入了first_or的程序流、最后返回default,在经过drop之后就无法正确打印s了,因为s指向的default已经无了

这样的例子也是不安全的,因为当函数执行完毕后&s会消失
如何修复报错
Returning a reference to the stack
*核心:返回引用需要关心 引用指向的原数据能不能活到函数提供返回值,如果坚持返回引用 需要加生命周期的前缀,或者放弃返回引用 直接返回数据本身
fn return_a_string()-> &String{
let s = String::from("Hello, world");
&s
}
这个例子中当需要返回&s时它已经寄了,不能保证s获得足够长
有4种方式可以延长字符串的寿命
- 将返回类型由
&String改为String
fn return_a_string() -> String {
let s = String::from("Hello world");
s
}
- 返回静态字符串(当我们无需涉及堆内存分配时
fn return_a_string() -> &'static str {
"Hello world"
}
- 显式调用gc,将borrow-checking挪到运行时
use std::rc::Rc;
fn return_a_string() -> Rc<String> {
let s = Rc::new(String::from("Hello world"));
Rc::clone(&s)
}
Rc::clone仅克隆指向s的指针 而不克隆数据,在运行时 Rc会检查最后一个指向数据的Rc何时删除 并在那之后释放数据
- 添加可变引用作为函数参数
fn return_a_string(output: &mut String) {
output.replace_range(.., "Hello world");
}
由函数调用放负责为返回的字符串创建空间,但是如果运用得当 这种做法是memory-efficient的
Not enough permissions
*当试图修改只读数据,或在存在引用时删除数据

这个例子的第二行就会报错,因为name本身是不可变引用 不存在write权限
我们希望这样调用
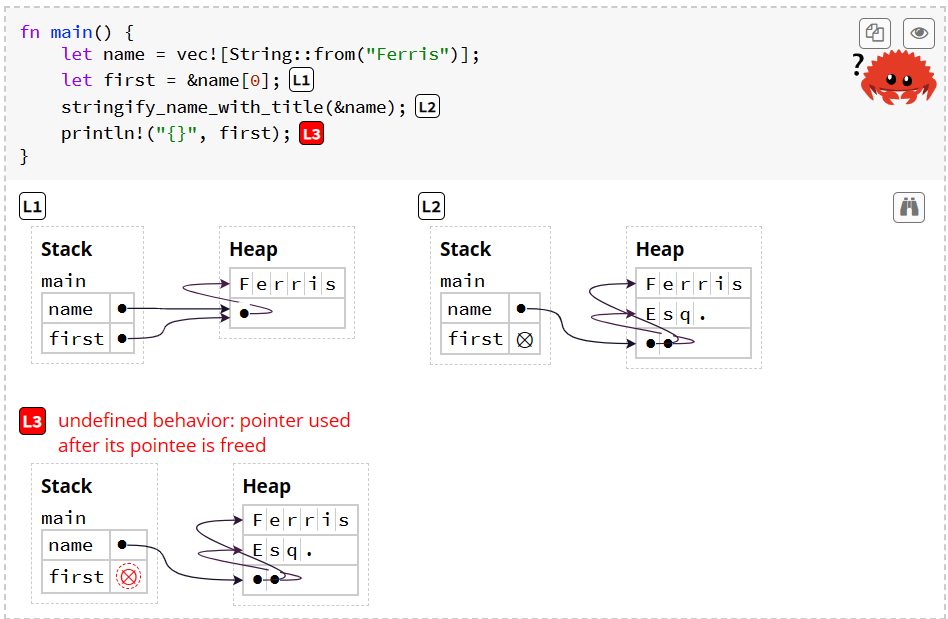
first指向name[0],name.push()重新分配了name 导致打印first会报错;也就是在存在&name时还试图修改name
如何修改?如果只是简单粗暴的修改接收参数的类型(从不可变引用改为可变引用)是很不负责任的做法,因为传入的参数可被修改 这不是调用方所预期的行为
另一个选择是将引用改为数据,确保传入的name一定拥有name的所有权——但这也不是好的解决方案,rust并不鼓励直接传入像Vec或String这样的数据类型
那么传入的&Vec<String>类型和传出的String都不改变,只有修改函数体了
- 克隆传入参数
fn stringify_name_with_title(name: &Vec<String>) -> String {
let mut name_clone = name.clone();
name_clone.push(String::from("Esq."));
let full = name_clone.join(" ");
full
}
通过克隆name,我们可以直接修改这个vector的副本 且不影响原参数
- 使用已存在的函数
fn stringify_name_with_title(name: &Vec<String>) -> String {
let mut full = name.join(" ");
full.push_str(" Esq.");
full
}
- 看情况会用到的方式
// before
fn round_in_place(v: &Vec<f32>) {
for n in v {
*n = n.round();
}
}
// error[E0594]: cannot assign to `*n`, which is behind a `&` reference
// --> test.rs:4:9
// after
fn round_in_place(v: &mut Vec<f32>) {
for n in v {
*n = n.round();
}
}
在这个对小数取整的函数中,需要对传入的Vec一一修改,最好的方式是将参数改为可变引用 并直接用*n修改原数据
Aliasing and mutating a data structure
*指的是一个引用指向的堆数据被其它的别名解引用
举例
fn add_big_strings(dst: &mut Vec<String>, src: &[String]){
let largest: &String = dst.iter().max_by_key(|s| s.len()).unwrap();
for s in src{
if s.len()>largest.len(){
dst.push(s.clone());
}
}
}
第二行largest会把dst的write权限借走 直到倒数第四行push时仍没有归还,但此时dst是需要write权限的,就会引起编译器报错——因为dst.push()可能会影响dst的数据,导致largest的引用失效
为了解决这个问题 我们缩短largest的生存周期
- 对largest克隆
fn add_big_strings(dst: &mut Vec<String>, src: &[String]) {
let largest: String = dst.iter().max_by_key(|s| s.len()).unwrap().clone();
for s in src {
if s.len() > largest.len() {
dst.push(s.clone());
}
}
}
但可能会影响性能
- 将比较和push分开执行
fn add_big_strings(dst: &mut Vec<String>, src: &[String]) {
let largest: String = dst.iter().max_by_key(|s| s.len()).unwrap().clone();
for s in src {
if s.len() > largest.len() {
dst.push(s.clone());
}
}
}
*修复核心:缩短借出去的时间,保证本体在需要对应权限(如write)的时候不出问题
Copying vs moving out of a collection
从vector中复制数据有可能对新手造成困扰

在上图的例子中,第二行对v[0]引用 全场无write,到第三行对n_ref解引用后n顺利读出来值,但如果vector内的组成元素不是i32而是String则会有点问题
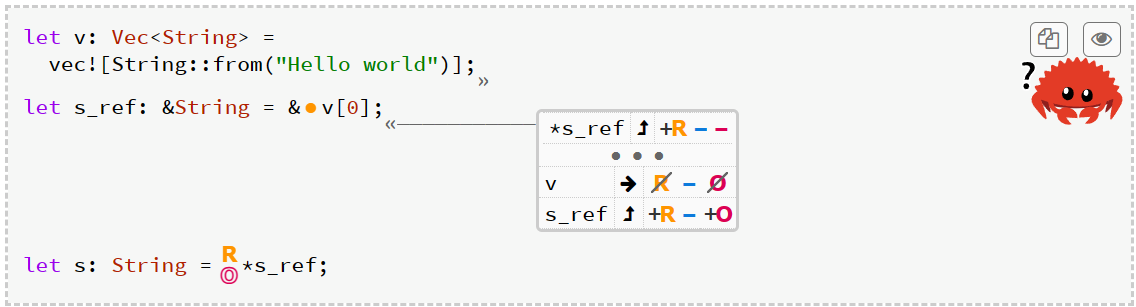
除了第一行以外其它都一样 但会报错
原因是,s、v和s_ref实际都指向字符串,一旦之后这三个有一个被dropped,关联的变量也会dropped,就会发生double-free
然而这种undefined behavior并不会发生在含有i32的vector中!区别就是复制String实际是会复制一个指向heap data的指针,而复制i32不会;在Rust的官方解释中说:i32有Copy trait,String没有
*总之,当一个值不用上堆,那它可以随意复制,比如i32和&String,而String在堆上 拥有heap data,就不能直接复制
*特例:对mut类型数据有特殊操作,比如&mut i32也是不能复制的,如:
let mut n = 0;
let a = &mut n;
let b = a; // wrong
这时为了避免两个可变引用指向同一个数据
那应该如何正确复制呢?
- 避免对String切换所有权,只是使用不可变引用本身
let v: Vec<String> = vec![String::from("Hello, World")];
let s_ref: &String = &v[0];
println("{s_ref}");
- 用无敌的克隆,获得String的所有权
let v: Vec<String> = Vec![String::from("Hello, world")];
let mut s: String = v[0].clone();
s.push('!')
println("{s}");
- 用内置方法
Vec::remove将String拿出来
let mut v: Vec<String> = vec![String::from("hello world")];
let mut s: String = v.remove(0);
s.push('!');
println("{s}");
assert!(v.len() == 0);
Mutating Different Tuple Fields(safe)
以上的报错都来自于潜在的安全性问题,但完全没有安全性问题的程序也可能会报错,因为Rust采用了细粒度的权限分级,然而Rust也可能会把不同的path合并为同一path
举例1:从tuple中拿一个元素给另一个tuple
fn main() {
let mut name = (
String::from("Ferris"),
String::from("Rustacean")
);
let first = &name.0;
name.1.push_str(", Esq.");
println!("{first} {}", name.1);
}
first借走了name.0的String,两者都不拥有write和own权限,但name.1仍有write 我们可以自由的使用name.1.push_str()
举例2:换成函数的写法
fn get_first(name: &(String, String)) -> &String {
&name.0
}
fn main() {
let mut name = (
String::from("Ferris"),
String::from("Rustacean")
);
let first = get_first(&name);
name.1.push_str(", Esq.");
println!("{first} {}", name.1);
}
这里是对&name整体传参,所以name.1的write权限也无了
由此可见,Rust不关心具体的函数实现,只关心传入传出的参数类型
*可恶!正确的函数也会被误伤
Mutating different array elements(safe)
类似的,对array也会有一样的效果——恶意中伤!
我们可以用内置函数来避免
let mut a = [0, 1, 2, 3];
let (x, rest) = a.split_first_mut().unwrap();
let y = &rest[0];
*x += *y;
或者unsafe!
let mut a = [0, 1, 2, 3];
let x = &mut a[0] as *mut i32;
let y = &a[1] as *const i32;
unsafe { *x += *y; } // DO NOT DO THIS unless you know what you're doing!
unsafe blocks允许使用裸指针,也不会被borrow checker检查安全性(好耶
*这一章的几个题还挺难的 在这里记录一下