和虚拟机的区别
*两者均可套娃
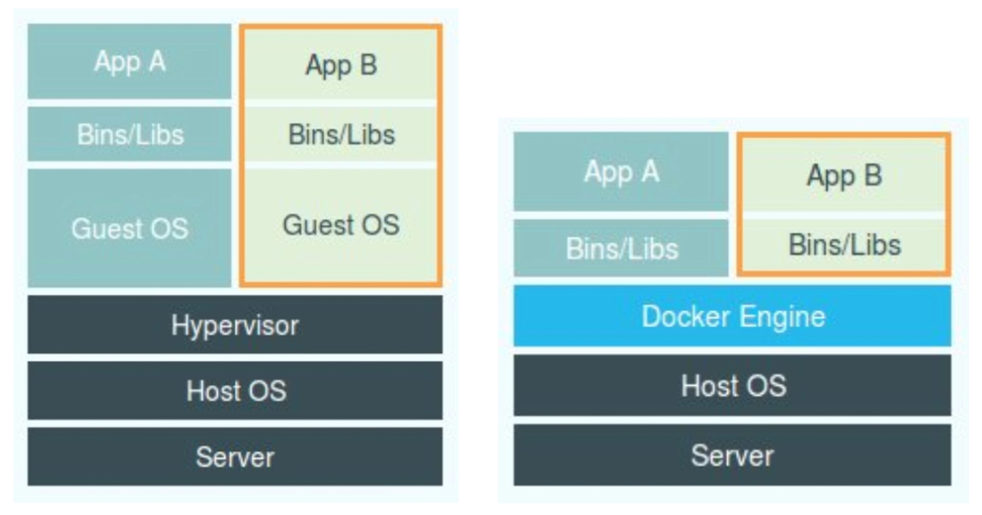
虚拟机基于Hypervisor,每台虚拟机都有独立的“虚拟 物理环境”,再在这之上构建完整的操作系统
容器则是在宿主机中,利用namespace和cgroup原本的linux特性 将进程隔离在封闭的环境中,也就是通过约束和修改进程的动态表现,从而创造出一个容器边界,再通过veth让进程的网络环境相互隔离,利用docker的网桥来进行容器进程之间的相互通信
容器技术本质是linux技术的组合
隔离
namespace
docker run -it busybox /bin/sh
起一个简单的busybox容器,此时ps只有两个进程
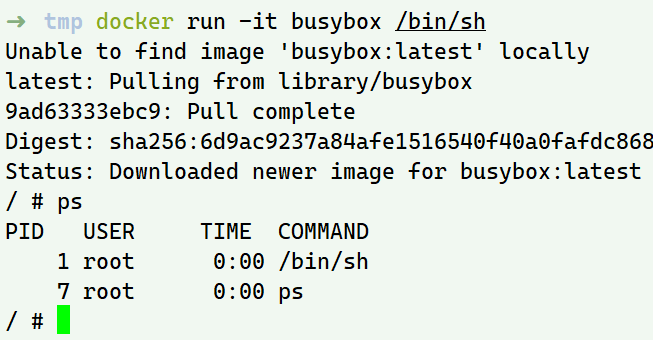
容器内部将初始的/bin/sh视作pid=1,而宿主机中实际为pid=45204,这就是namespace的隔离机制
linux中创建进程的系统调用是clone,比如
int pid = clone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL);
创建新进程的同时返回pid,当指定CLONE_NEWPID时 新的进程就会“看到”一个全新的进程空间,以1为起始 它自己就是这个1
linux中的namespace有7个http://man7.org/linux/man-pages/man7/namespaces.7.html,分别是UTS, IPC, PID, Mount, Cgroups, User, Network
docker创建容器就是linux系统中的一次fork调用,flag参数可以控制namespace
userns-remap
docs: https://docs.docker.com/engine/security/userns-remap/
在docker中 对于user namespace的隔离就是userns-remap,但属于默认未启用的feature
容器中运行的服务尽量以非root的普通用户运行,如果必须在容器内使用root用户,就可以使用user namespace技术,将宿主机的普通用户映射成容器中的root用户
若启用,将影响文件挂载访问,并且所有容器都会启用用户隔离,可以通过--userns=host参数对单个容器禁用用户隔离
限制
Cgroup
通过namespace技术可以隔离(映射)容器的进程、用户等,但这并不是物理隔离,运行时如果不加限制还是会造成和宿主机的资源竞争
linux Control Group就是linux内核中为进程设置资源限制的重要技术,可以限制一个进程组能够使用的资源上限 包括CPU 内存 磁盘 网络等
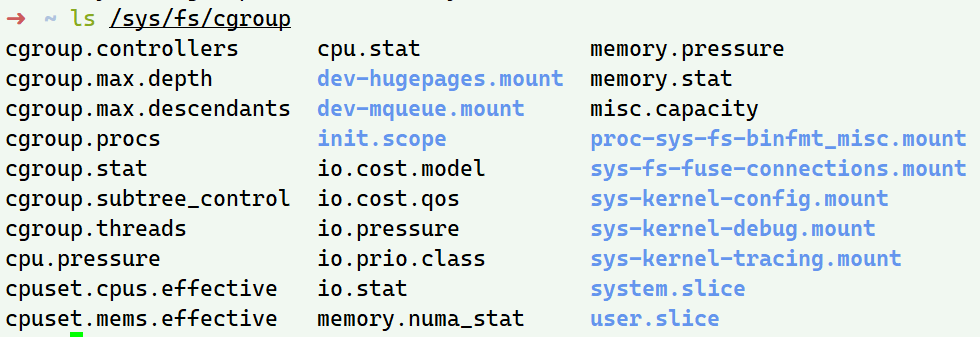
如上图 /sys/fs/cgroup下面诸如cpuset cou memory这样的子目录(或子系统),都是这台机器当前可以被Cgroups进行限制的资源种类,在这些目录之下可以列出指定资源被限制的方法
文件系统
手撕docker文件结构 —— overlayFS,image,container文件结构详解
rootfs
rootfs是每一个容器运行时内部可见的文件系统,即docker容器的根目录,我们运行docker exec命令进入container看到的文件系统就是rootfs
rootfs包含一个操作系统运行所需的文件系统,包含典型的类 Unix 操作系统中的目录系统,如 /dev、/proc、/bin、/etc、/lib、/usr、/tmp 及运行 docker 容器所需的配置文件、工具等
docker daemon为container挂载rootfs时也会先挂载为只读模式,与linux做法不同的是在这之后 docker daemon会利用union mount联合挂载技术在已有的rootfs上再挂一个读写层,container在运行过程中文件系统发生的变化只会写到读写层,并通过whiteout技术隐藏只读层中的旧版本文件
overlayFS
上面提到union mount,可以理解为将不同功能目录进行合并 最后展现出合并后的文件系统
overlayFS是联合挂载技术的一种实现,linux内核为docker提供的overlayFS驱动有两种:overlay2和overlay,overlay2是相对于overlay的一种改进,在inode利用率方面比overlay更有效
overlayFS通过三种目录实现,它们合并出来的目录被称为merged目录
- lower目录:可以是多个,位于最底层(只读层)
- upper目录:只有一个(读写层)
- work目录:工作基础目录,挂载后内容会被清空,在使用过程中其内容对用户不可见
- merged目录:联合挂载完后呈现给用户的统一视图,merged目录中实际没有实体文件,真正的文件在lower和upper中
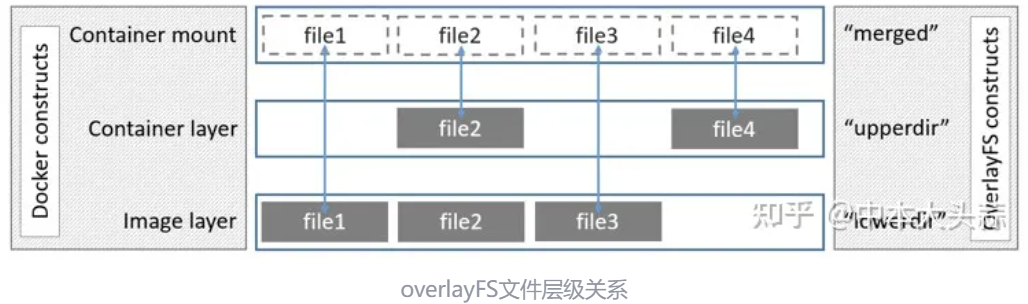
我们可以直接实验这个overlayFS是如何运作的
cd test
mkdir -p A B C worker
echo "From A" > A/a.txt
echo "From A" > A/b.txt
echo "From A" > A/c.txt
echo "From B" > B/a.txt
echo "From B" > B/d.txt
echo "From C" > C/b.txt
echo "From C" > C/e.txt
mkdir merged
mount -t overlay overlay -o lowerdir=A:B,upperdir=C,workdir=worker merged
我们将A B作为lower目录(只读),C作为upper目录(读写),worker作为work目录,新建merged作为显示视图
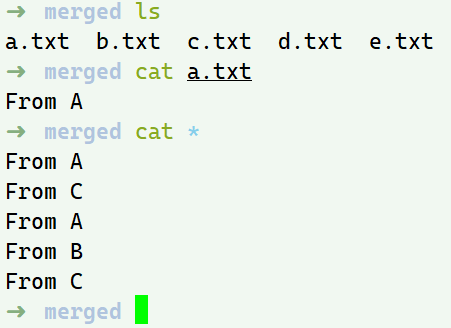
由于挂载时使用了lowerdir=A:B的参数,所以虽然同为lower目录 A在B之上,同名文件只保留A中的a.txt
如果我们此时删除视图merged中的a.txt,会发现A和B的a.txt都没有消失,读写层C还多了一个权限为c的a.txt
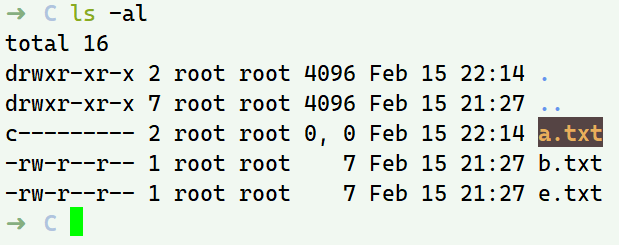
这个upper读写层中多出来的文件就叫whiteout文件,通过覆盖lower只读目录里的a.txt来表示该文件已经被删除
修改和删除同理,修改文件时使用copy on write写时复制技术,在未更改文件内容时,视图merged直接使用lower里的数据,只有当merged中的数据发生变化时 才会把变化的文件内容复制到读写层进行修改 并遮盖掉只读层中的老文件
Image file system
存储结构
对于docker镜像 可以使用这样的命令查看镜像的overlay2结构目录
docker image inspect ubuntu
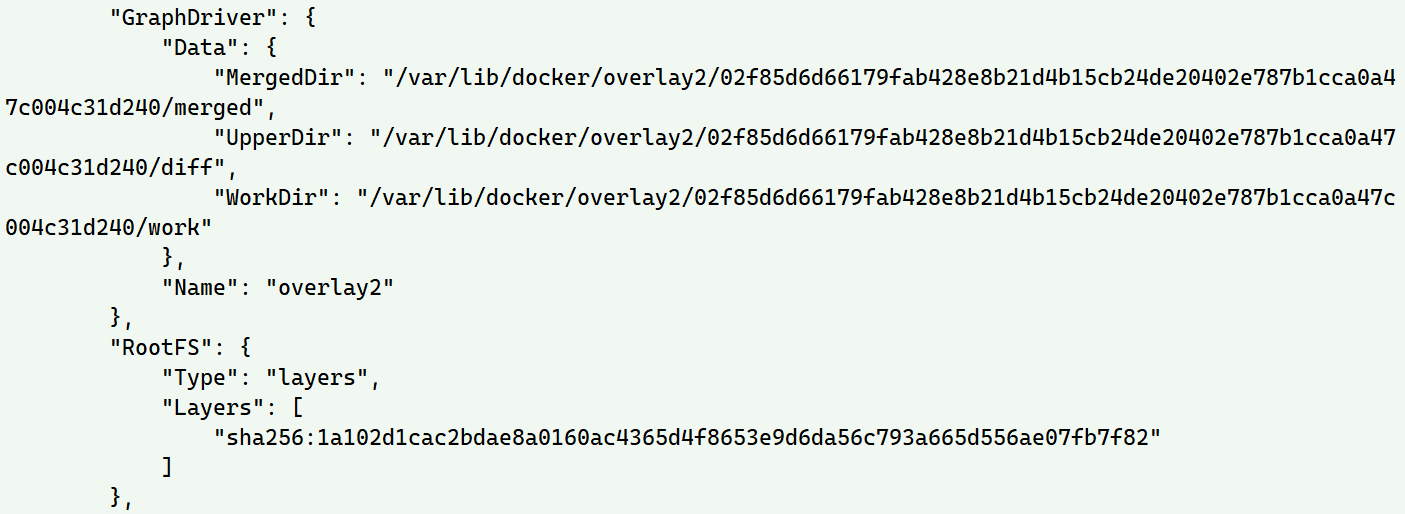
进入这个镜像的读写upper目录,可以看到完整的ubuntu系统目录


回退上一层,会发现只有diff, link, commited,并没有inspect中显示的merged, work目录
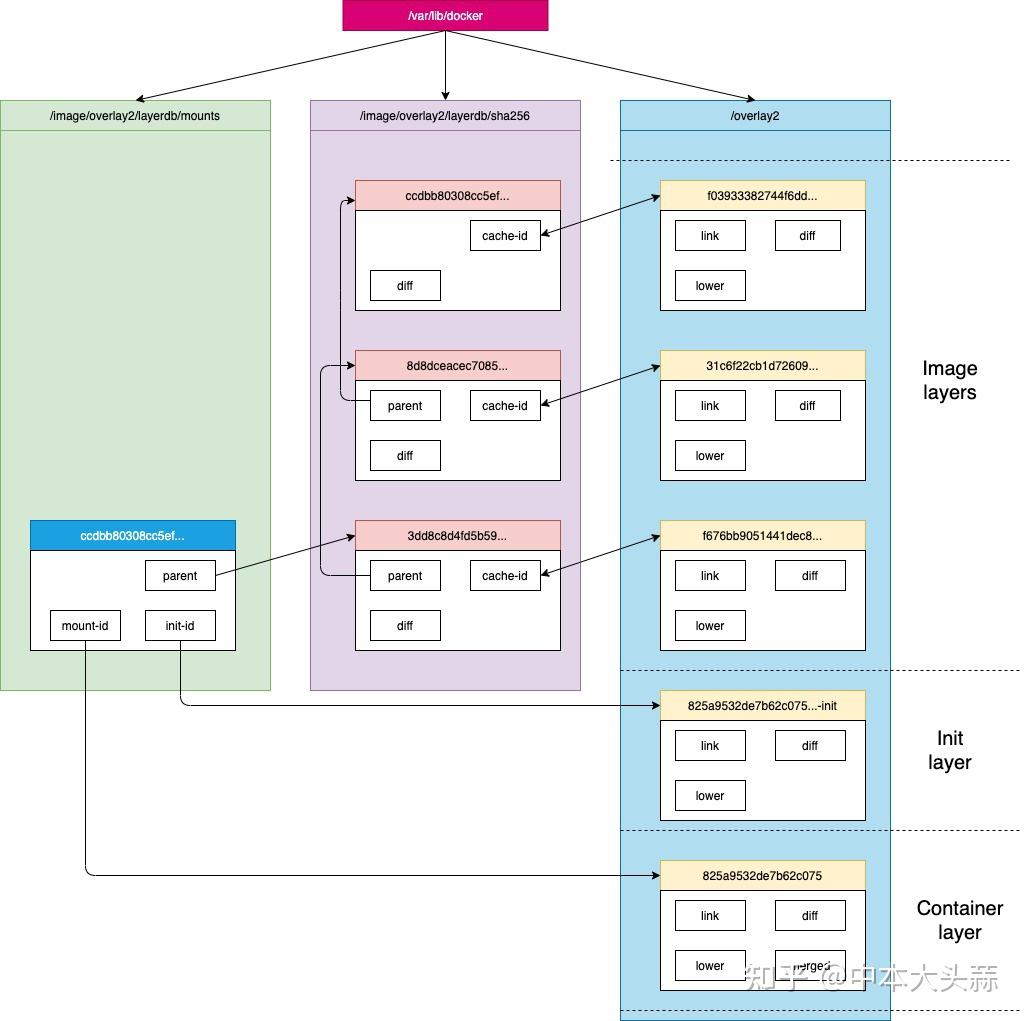
link和lower文件中的内容分别为当前层和下一层的软连接名字,如果当前层是底层,则不存在lower文件;真正的软链接文件都存在/var/lib/docker/overlay2/目录下,分别指向对应层的diff目录
image元数据
metadata存储在/var/lib/docker/image/<storage_driver>/imagedb/content/sha256/目录下
新起一个ubuntu,image id为3db8720ecbf5,那这个busybox镜像的元数据就在/var/lib/docker/image/overlay2/imagedb/content/sha256/3db8720ecbf5......中
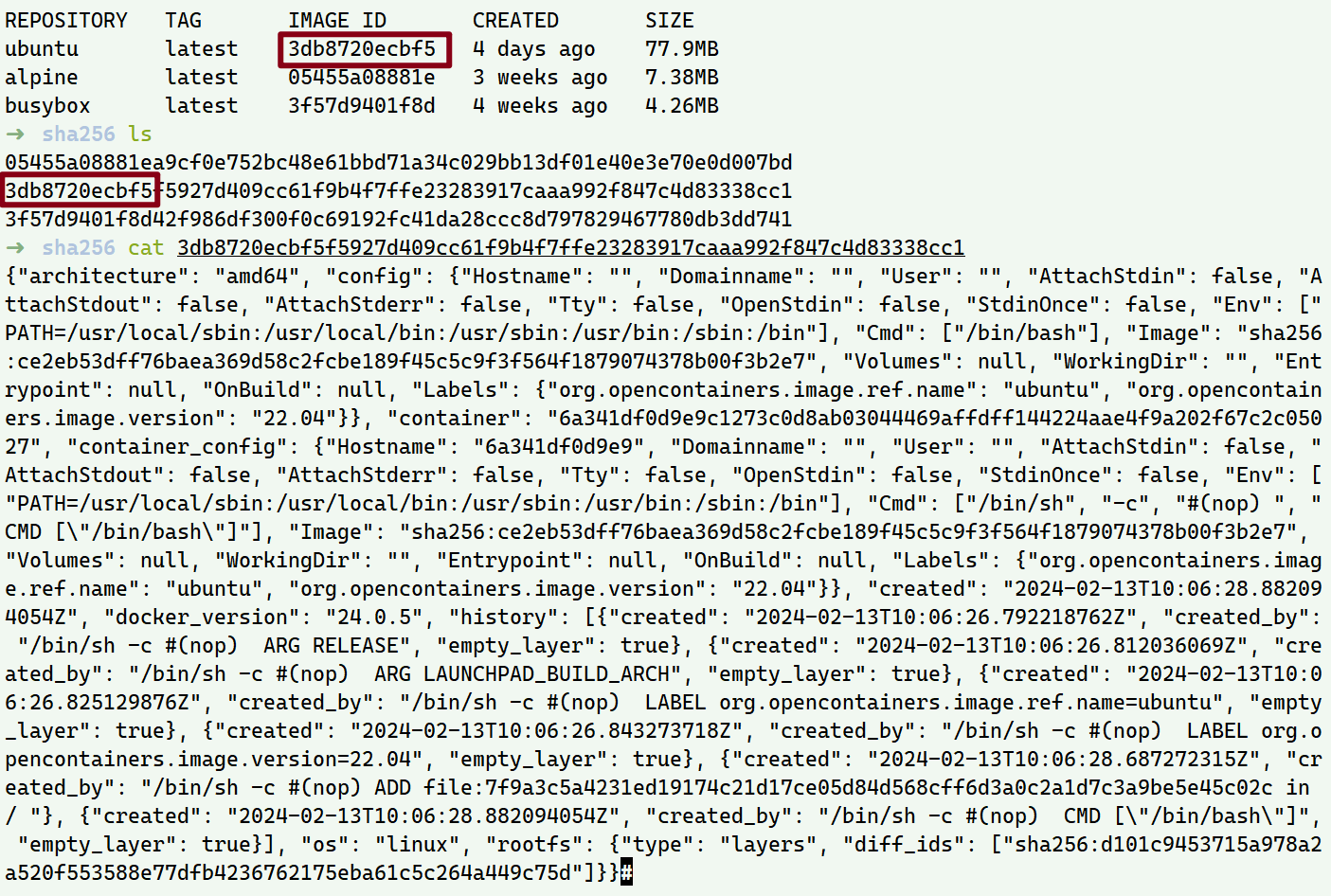
和docker image inspect中的信息基本一致,我们发现这些信息中都有很多sha256的id
RootFS.Layers: d101c9453715a978a2a520f553588e77dfb4236762175eba61c5c264a449c75d (diff_id)
ContainerConfig.Image: ce2eb53dff76baea369d58c2fcbe189f45c5c9f3f564f1879074378b00f3b2e7
这个镜像只有一层,如果有多层 那rootfs的diff_ids会有多个sha256 id,从上到下依次为镜像层的最低层到最顶层
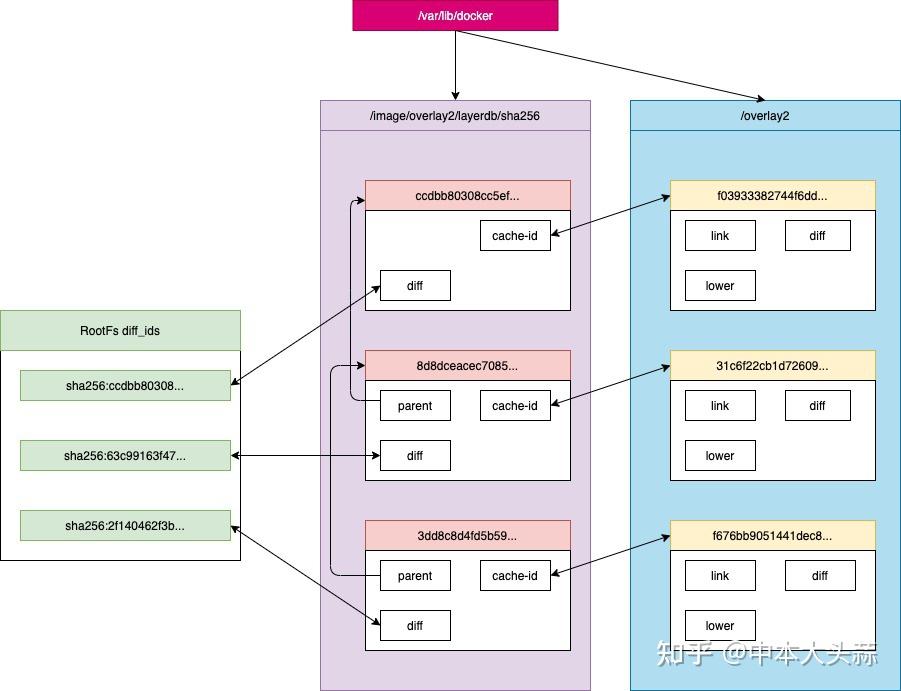
上一个标题中讲到 镜像的每层文件都存储在/var/lib/docker/overlay2/<cache_id>目录下,那镜像的diff_id是如何关联到实际存储的cache_id呢?
docker利用rootfs中的每个diff_id和历史信息计算出与之对应的内容寻址的索引chain id,而chain id关联了cache_id,进而做到镜像关联到每一个镜像层的镜像文件
本例中:
image_id: ce2eb53dff76baea369d58c2fcbe189f45c5c9f3f564f1879074378b00f3b2e7
container_id: dad1032d40526458db14b2e043e6aebc981ea5b844e2e07e366964f604749fdd
container_name: pedantic_carson
layer_id(cache_id): 5e4eeab9b8f57db9c1a41e3db01bb141e77f92e931d2c1a112e73feaa6830883
存储相关文件位于/var/lib/docker/overlay2/<layer_id>文件夹下
- diff_ids: d101c9453715a978a2a520f553588e77dfb4236762175eba61c5c264a449c75d
可以有很多层
- chain_id: d101c9453715a978a2a520f553588e77dfb4236762175eba61c5c264a449c75d
如果该镜像层已经是最底层(没有父镜像层),该层的diff_id便是chain_id,在/var/lib/docker/image/overlay2/layerdb/sha256/<chain_id>文件夹下有相关文件
layer元数据
我们从diff_id得到chain_id,该如何关联cache_id呢?
docker中定义了Layer和RWLayer两种接口,分别用来定义只读层和可读写层的一些操作,又据此定义了roLayer和mountedLayer,分别实现了上述两种接口
- roLayer: 用于描述不可改变的镜像层
元数据位于/var/lib/docker/image/<storage_driver>/layerdb/sha256/<chain_id>
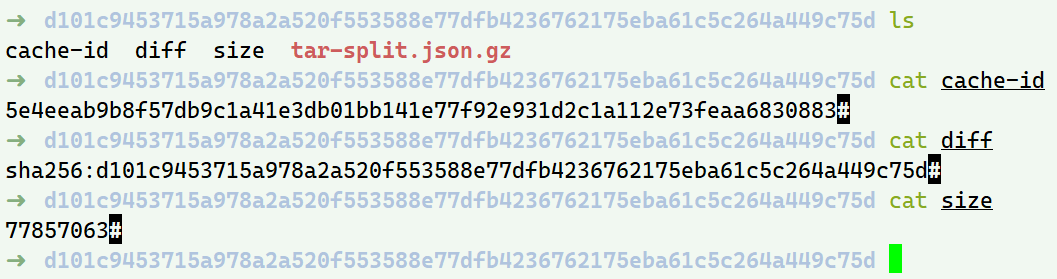
如果非底层的layer,还会有parent文件 存放当前layer的父layer的diff_id;tar-split.json.gz是layer压缩包的split文件 通过这个文件可以还原layer的tar包,在docker save导出image时会用到
- mountedLayer: 用于描述可读写的容器层
元数据位于/var/lib/docker/image/<storage_driver>/layerdb/mounts/<container_id>/
Container file system
一个容器完整的层由三个部分组成:
- 镜像层:即rootfs,提供容器启动的文件系统,也就是上一个三级标题中的image文件,镜像层书与roLayer
- init层:用于修改容器中一些文件,如/etc/hostname, /etc/hosts/, /etc/resolv.conf等,属于mountedLayer
- 容器层:使用联合挂载统一给用户提供的可读写目录,属于mountedLayer
我们已经知道不变的镜像层的文件系统,现在来看init和容器层;还是以之前的ubuntu为例(各id不变),查看mountedLayer的元数据目录/var/lib/docker/image/<storage_driver>/layerdb/mounts/<container_id>/查看数据
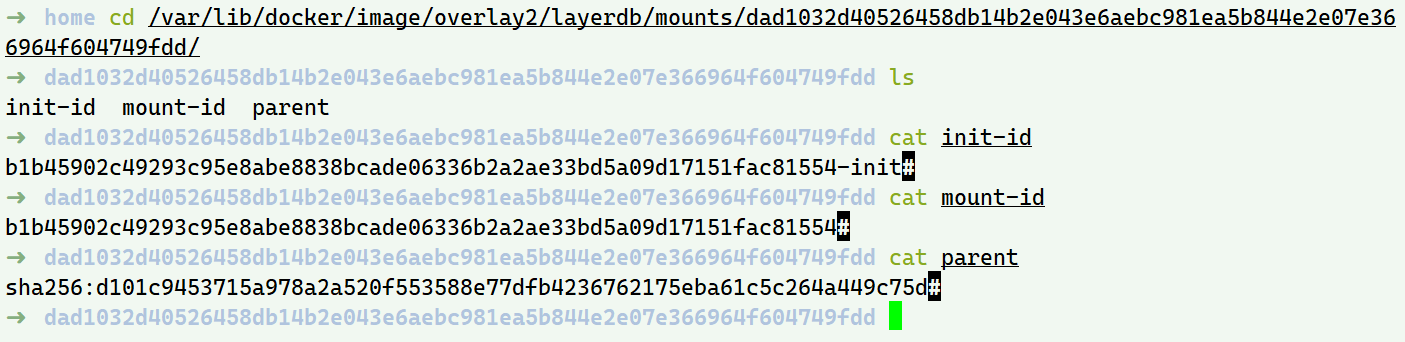
- mount-id: 存储在/var/lib/docker/overlay2/的目录名称
- init-id: 在mount-id的内容后加了一个-init,在/var/lib/docker/overlay2/下存在同名目录
- parent: 容器所基于的镜像的最上层的chain_id
查看/var/lib/docker/overlay2/b1b45902c49293c95e8abe8838bcade06336b2a2ae33bd5a09d17151fac81554-init的内容
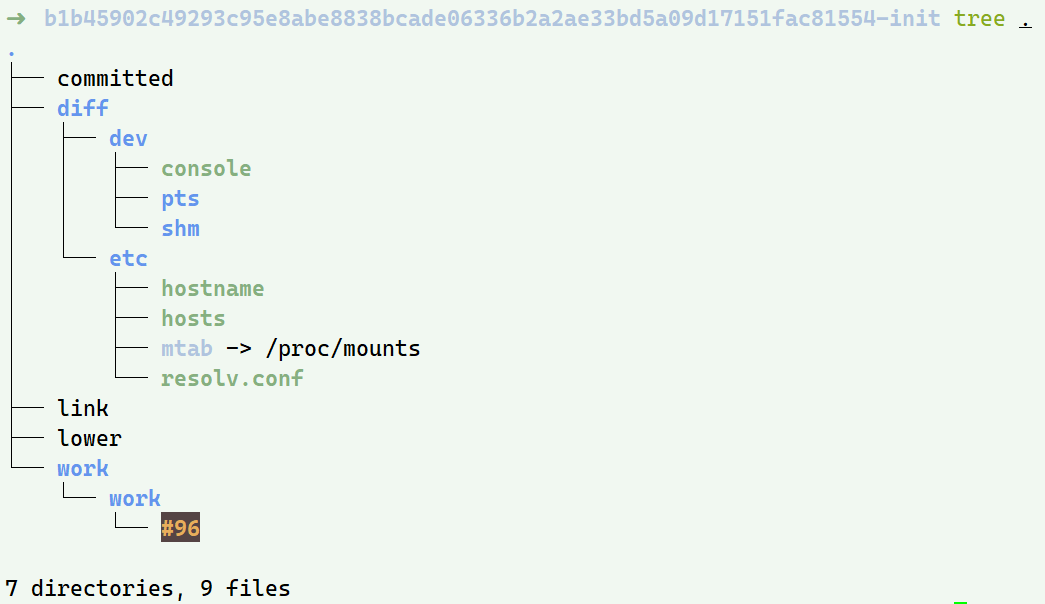
可以看到除了常规文件外只有少数配置文件;需要这一层的原因是当容器启动时,这些本该属于镜像层的文件或目录,比如hostname, 用户等需要修改,但image层又不允许修改,所以启动时通过单独挂载一层init层,通过修改init层中的文件达到修改这些文件的目的,而这些修改往往只对当前容器生效,在docker commit提交为镜像的时候 并不会将init提交
再看容器层的内容(目录名去掉-init):
/var/lib/docker/overlay2/b1b45902c49293c95e8abe8838bcade06336b2a2ae33bd5a09d17151fac81554/
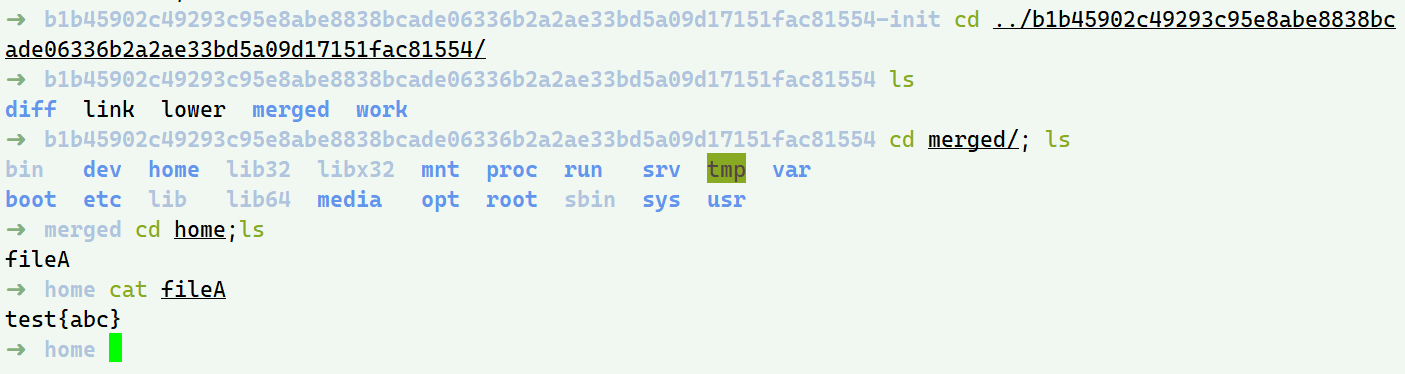
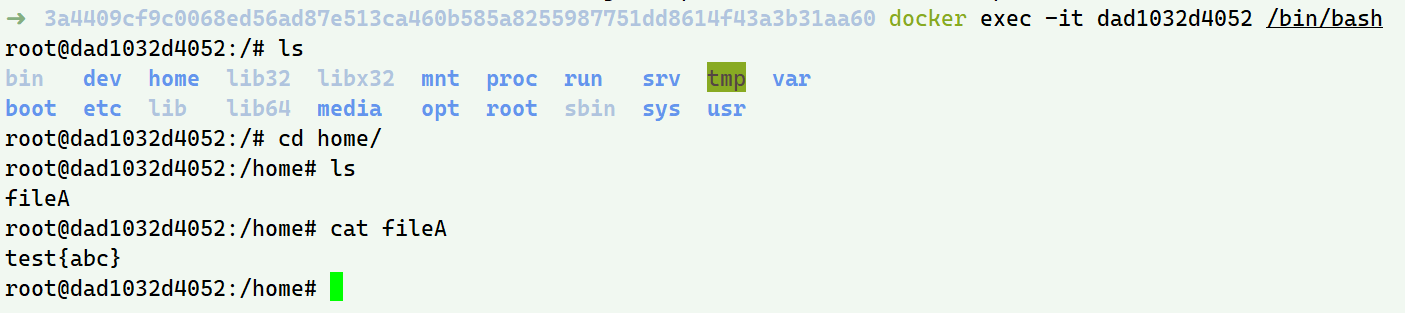
我们想要的容器内实际的文件终于在./merged/文件夹找到了,它就是由镜像层,init层与容器层联合挂载得到的(就像最初overlayFS小实验中的merged目录一样)
而同级的diff目录下就保存了针对文件的修改,添加一般文件则是正常读写权限,而删除init中原本就有的 则为whiteout文件 权限为c